TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025124582
公報種別
公開特許公報(A)
公開日
2025-08-26
出願番号
2024209863
出願日
2024-12-03
発明の名称
画像を記述する構造化テキストを生成する方法
出願人
富士通株式会社
代理人
弁理士法人ITOH
主分類
G06N
3/0475 20230101AFI20250819BHJP(計算;計数)
要約
【課題】 画像を記述する構造化テキストを生成するためのコンピュータ実装方法を提供する。
【解決手段】 当該方法は、前記画像からアイテムを抽出するステップと、抽出されたアイテムを符号化するステップと、前記画像の予測ドメインからドメイン埋め込みを生成するステップと、符号化された抽出された前記アイテムと前記ドメイン埋め込みを復号することにより前記画像内の2つのアイテム間の関係を予測するステップと、前記2つのアイテムと予測された前記関係を分類して前記構造化テキストをトリプレットとして形成するステップと、を含む。
【選択図】 図5
特許請求の範囲
【請求項1】
画像を記述する構造化テキストを生成するためのコンピュータ実装方法であって、
前記画像からアイテムを抽出するステップと、
抽出された前記アイテムを符号化するステップと、
前記画像の予測ドメインからドメイン埋め込みを生成するステップと、
符号化された抽出された前記アイテムと前記ドメイン埋め込みを復号することにより前記画像内の2つのアイテム間の関係を予測するステップと、
前記2つのアイテムと予測された前記関係を分類して前記構造化テキストをトリプレットとして形成するステップと、
を含む方法。
続きを表示(約 1,100 文字)
【請求項2】
前記画像内の2つのアイテム間の関係を予測するステップは、
符号化された抽出された前記アイテムから述語埋め込みを生成するステップと、
前記ドメイン埋め込みと前記述語埋め込みを連結して拡張述語埋め込みを生成するステップと、
前記拡張述語埋め込みから前記関係を予測するステップと、
を含む、請求項1に記載の方法。
【請求項3】
前記画像内の2つのアイテム間の関係を予測するステップは、
前記ドメイン埋め込みに対する条件学習可能クエリにセルフアテンションメカニズムを使用するステップと、
前記条件学習可能クエリ及び符号化された抽出された前記アイテムをクロスアテンションメカニズムに入力して、拡張述語埋め込みを生成するステップと、
前記拡張述語埋め込みから前記関係を予測するステップと、
を含む、請求項1に記載の方法。
【請求項4】
前記画像の予測ドメインは、前記画像のグローバル情報から生成される、請求項1に記載の方法。
【請求項5】
前記予測ドメインはトレーニング済みニューラルネットワークを使用して予測される、請求項4に記載の方法。
【請求項6】
前記グローバル情報は、画像エンコーダによって生成された前記画像のヘッドトークンを含む、請求項4に記載の方法。
【請求項7】
前記トレーニング済みニューラルネットワークは、多層パーセプトロン(MLP)ニューラルネットワークを含むドメイン予測ユニットである、請求項5に記載の方法。
【請求項8】
MLPは3つの層を含む、請求項7に記載の方法。
【請求項9】
前記ドメイン予測ユニットは、線形層を使用してトレーニングされ、ドメイン予測及び線形層の重みは、グランドトゥルースドメインクラスと前記ドメイン埋め込みから生成されたドメインクラスとの間の損失計算を使用して更新され、前記グランドトゥルースドメインクラス及び前記ドメインクラスの損失計算は、1つのホットコーディングフォーマットを含む、請求項7に記載の方法。
【請求項10】
前記ドメイン予測ユニットは、事前トレーニングされた大規模言語モデル(LLM)を使用してトレーニングされ、ドメイン予測の重みは、前記ドメイン埋め込みと前記LLMによって生成されたグランドトゥルースドメイン埋め込みとの間の類似メトリックをユーザ入力ドメイン名から計算し、前記類似メトリックから決定される損失関数を最小化することによって更新される、請求項7記載の方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本発明は、画像を記述する構造化テキストを生成するためのコンピュータ実装方法、コンピュータプログラム及び情報処理機器に関する。
続きを表示(約 3,100 文字)
【背景技術】
【0002】
コンピュータビジョンの分野では、画像認識は近年信じられないほどの発展を遂げている。特に、ニューラルネットワークは、画像内の目的語を認識し、画像からシーングラフのような構造化テキストを生成するために一般的になっている。
【0003】
シーングラフ生成(Scene graph generation (SGG))は、Visual Question and Answer(VQA)、画像編集、動作認識などのタスクに使用することができる。しかし、シーングラフ認識モデルは、一般的な目的語関係に偏ったラベル付き画像でトレーニングされることが多い。つまり、ラベル付き画像は、主語(subject)-目的語(object)関係を記述するために、「on」、「in」、「by」などの単純な記述子に焦点を当てることが多い。大規模なデータベースにおける単純な記述子の数は、目的語-主語のペアを記述するための意味のある文脈的に豊富な述語をはるかに超えることが多い。このような不均衡なデータ分布でトレーニングされたSGGモデルの予測は、単純で「粒度の粗い」記述に偏っているため、情報量の少ないシーングラフになってしまう。
【0004】
単純な記述子は目的語の関係性を正しくラベル付けすることができるが、画像にはほとんど、あるいは全くコンテキストを提供しない。これにより、目的語間の意味のある関係性を欠いた単純なシーングラフのトリプレットが生成される。そのため、これらの単純なシーングラフは、豊富な意味表現を必要とするVQAのような下流タスクでは使用が制限されている。
【0005】
一般的な研究では、ロングテール述語分布に焦点を当てることによって、シーングラフのバイアスを解除しようとしている。すなわち、‘riding on’、‘selling’、‘standing on’のような、より情報量の豊富な‘粒度の細かい’記述である。しかしながら、発明者らは、これらの手法が全体的なモデル性能を乱す可能性があることを発見した。例えば、分布の単純な先頭述語は、‘standing on’の‘on’のような、より意味のある末尾述語にもしばしば見られる。従って、ロングテール述語の偏りをなくすことに焦点を当てたり、先頭述語を過剰に適合させたり、或いは過小に適合させたりすることによって、シーングラフモデルが悪影響を受ける可能性がある。従って、SGG法を用いて文脈的に意味のある述語を生成することが望ましい。
【発明の概要】
【0006】
本発明は、独立請求項に定義されており、ここで参照すべきである。更なる特徴は、従属請求項に記載されている。
【0007】
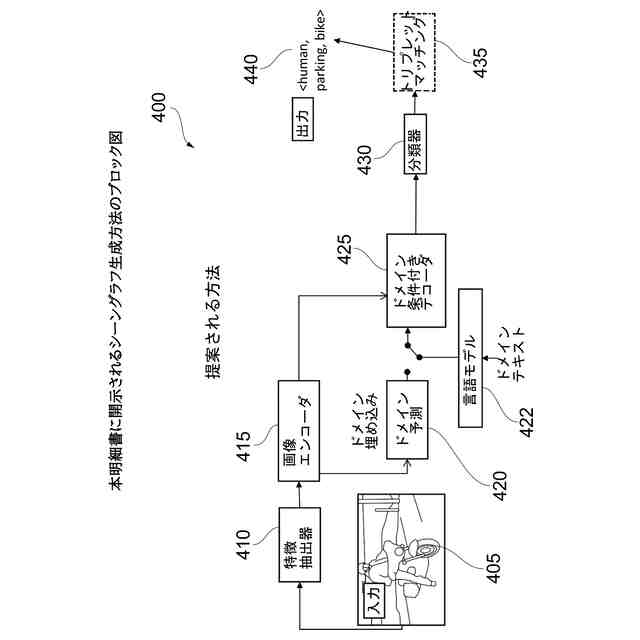
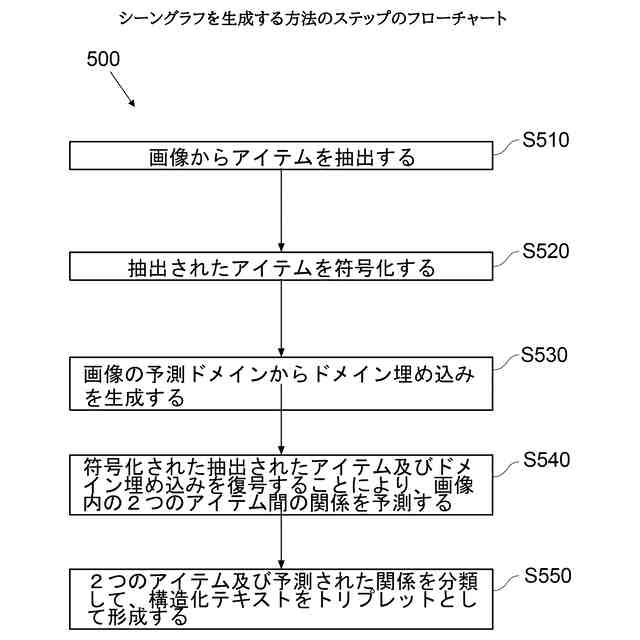
本発明の一態様によると、画像を記述する構造化テキストを生成するためのコンピュータ実装方法であって、
前記画像からアイテムを抽出するステップと、
抽出されたアイテムを符号化するステップと、
前記画像の予測ドメインからドメイン埋め込みを生成するステップと、
符号化された抽出された前記アイテムと前記ドメイン埋め込みを復号することにより前記画像内の2つのアイテム間の関係を予測するステップと、
前記2つのアイテムと予測された前記関係を分類して前記構造化テキストをトリプレットとして形成するステップと、
を含む方法が提供される。本方法は、構造化テキストを出力するステップを更に含むことができる。
【図面の簡単な説明】
【0008】
例としてのみ、以下の添付の図面を参照する。
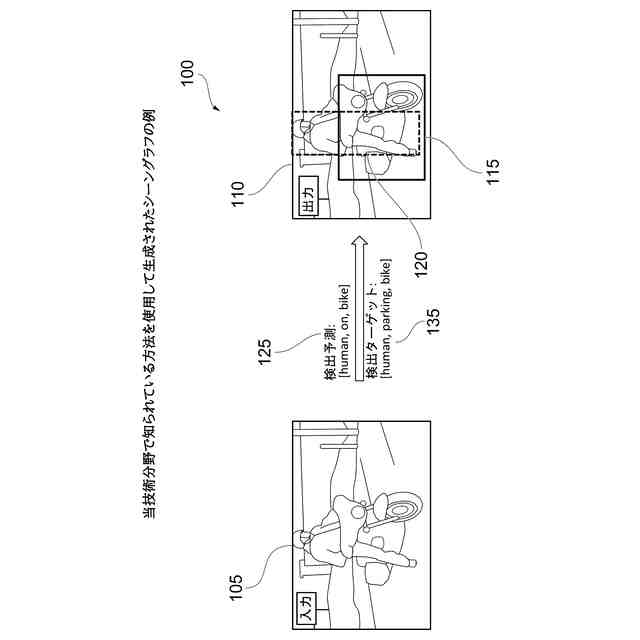
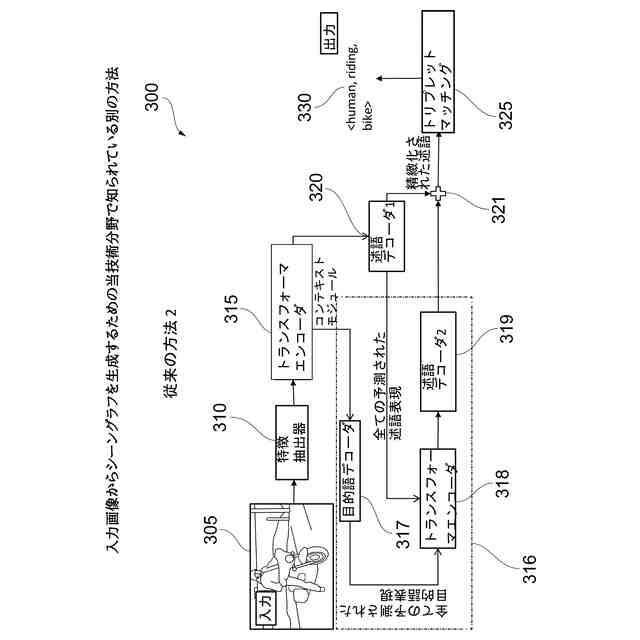
当技術分野で知られている方法を使用して生成されたシーングラフの例を示す。
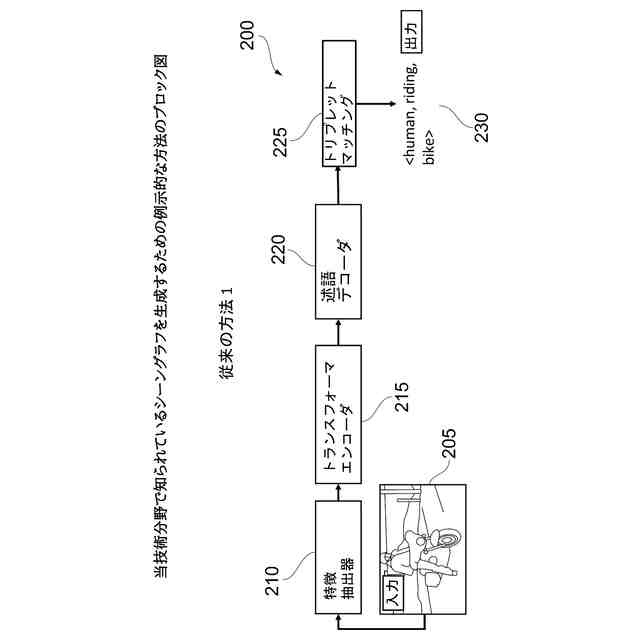
当技術分野で知られているシーングラフを生成するための例示的な方法のブロック図を示す。
入力画像からシーングラフを生成するための当技術分野で知られている別の方法を示す。
本明細書に開示されるシーングラフ生成方法のブロック図を示す。
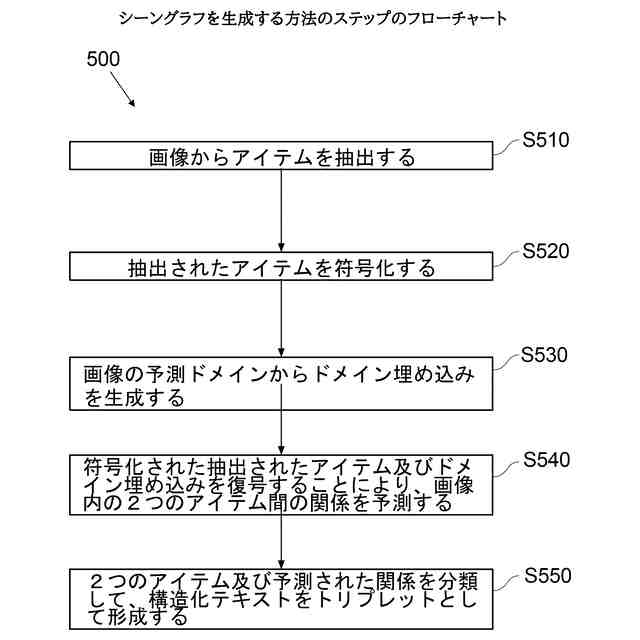
シーングラフを生成する方法のステップのフローチャートを示す。
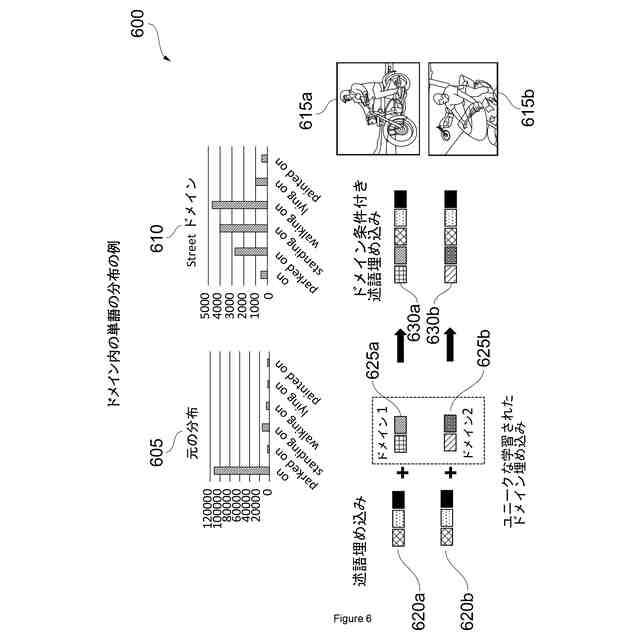
ドメイン内の単語の分布の例を示す。
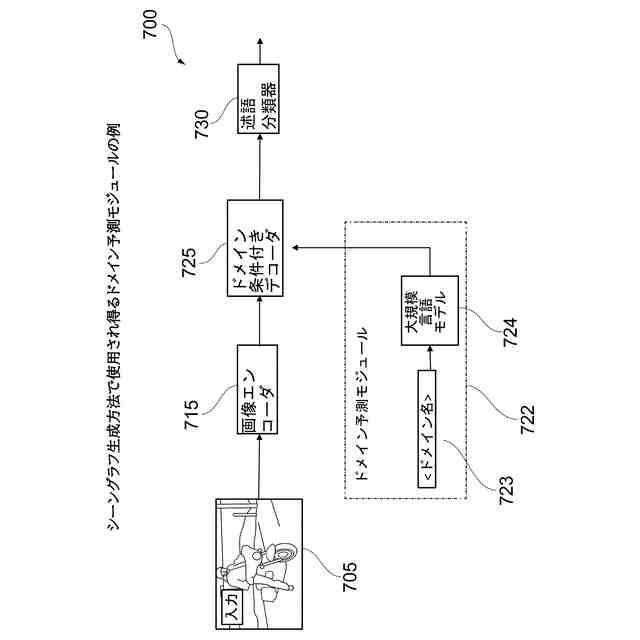
シーングラフ生成方法で使用され得るドメイン予測モジュールの例を示す。
シーングラフ生成方法で使用され得るドメイン予測モジュールの別の例を示す。
シーングラフ生成方法で使用され得るドメイン条件付きデコーダの例を示す。
シーングラフ生成方法で使用され得る別のドメイン条件付きデコーダの例を示す。
ドメイン条件付きデコーダで発生し得るトランスフォーマードメイン符号化の例を示す。
本明細書に開示されるシーングラフ生成方法をトレーニングする全体的トレーニング手法を示す。
ドメイン分割及びグループ化の例を示す。
ドメイン予測をトレーニングするためのトレーニング手法の例を示す。
ドメイン予測モジュールをトレーニングするための別のトレーニング手法の例を示す
シーングラフ生成方法の全体的な処理フローを示す。
本明細書に開示されるシーングラフ生成方法の全体的なテスト段階を示す。
既存の方法と対比して、本明細書に開示する方法を使用して生成された意味的に意味のあるシーングラフのトリプレットの例を示す。
既存の方法と対比して、本明細書に開示する方法を使用して生成された意味的に意味のあるシーングラフのトリプレットの例を示す。
本明細書に開示された方法を使用したシーングラフのトリプレットの生成の別の例を示す。
本明細書に開示された方法を実行するためのグラフィカルユーザインタフェース(GUI)の例を示す。
情報処理機器又はコンピュータ装置のブロック図である。
【発明を実施するための形態】
【0009】
近年、機械学習はコンピュータビジョン(computer vision (CV))の進歩に大きく貢献している。認識及び応用タスクのためのコンピュータビジョンモデルの視覚シーン理解を改善する要求がある。特定のコンピュータビジョンタスクはシーングラフ生成であり、ニューラルネットワークは入力画像を受け取り、画像内の目的語の関係又は属性を生成することができる。
【0010】
一般的にシーングラフは、少なくとも1つの目的語(又はアイテム)及び少なくとも1つの関係及び/又はアクション(又は「述語」又は「属性」)の特定の組み合わせを示すグラフである。例えば、シーングラフは、画像内の目的語、及びそれらの相互関係を示すことができる。すなわち、シーングラフは、グラフィカルシーンの論理的/空間的表現に対応することができる。dog、人々(people)(つまり、普通名詞)などのシーン内の目的語は、目的語ノードから形成され、目的語間の関係、動作又は記述子、例えば、「looking」、「sitting」、「playing」、「black」、「tall」などの述語は、目的語ノードを接続する述語ノードを形成するか、又は単一の目的語ノードに接続される。幾つかのシーングラフでは、ノードは目的語にのみ割り当てられ、述語は目的語を接続するエッジに沿ったラベルである。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
他の特許を見る
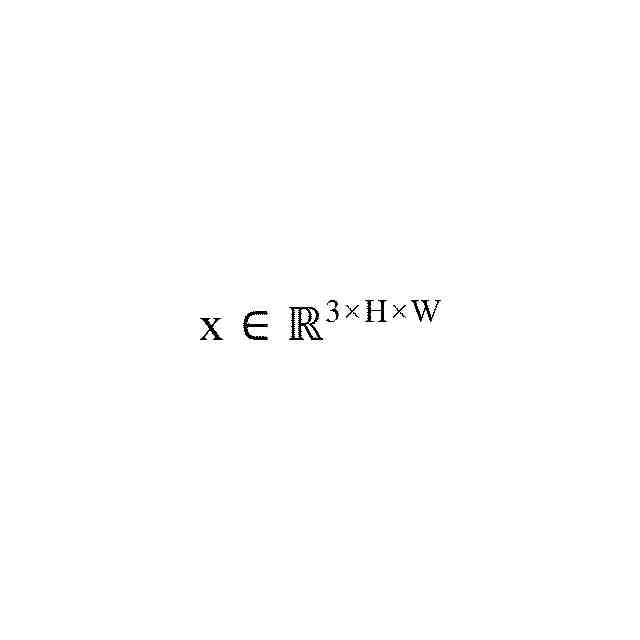

 特許ウォッチ
特許ウォッチ