TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025074384
公報種別
公開特許公報(A)
公開日
2025-05-14
出願番号
2023185137
出願日
2023-10-30
発明の名称
逆強化学習管理装置、逆強化学習管理方法及び逆強化学習管理システム
出願人
株式会社日立製作所
代理人
弁理士法人第一国際特許事務所
主分類
G06N
20/00 20190101AFI20250507BHJP(計算;計数)
要約
【課題】学習情報が少ない状況であっても、高精度の報酬関数が生成可能な逆強化学習管理手段を提供すること。
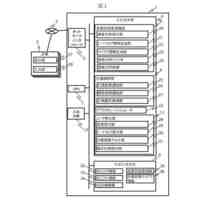
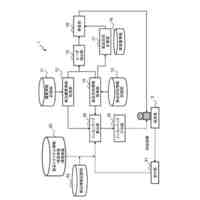
【解決手段】所定のシナリオに関する学習情報に基づいて、強化学習エージェントに与える報酬を規定する初期報酬関数を生成する関数生成部と、初期報酬関数に基づいて、強化学習エージェントの挙動を規定する初期方策を生成し、初期方策を用いて、シナリオにおいて、特定の状態に対して実施する特定の行動を示す状態・行動ペアのシーケンスからなる遷移を含む遷移情報を生成する遷移管理部と、遷移情報の中から、所定の分散基準を満たす遷移のサブセットを判定する遷移選択部と、遷移のサブセットの中から、無効な状態・行動ペアを特定し、無効な状態・行動ペアに基づいて、初期報酬関数に対する制約を規定し、制約を初期報酬関数に対して適用することで、修正済みの報酬関数を生成する制約生成部とを含む逆強化学習管理装置。
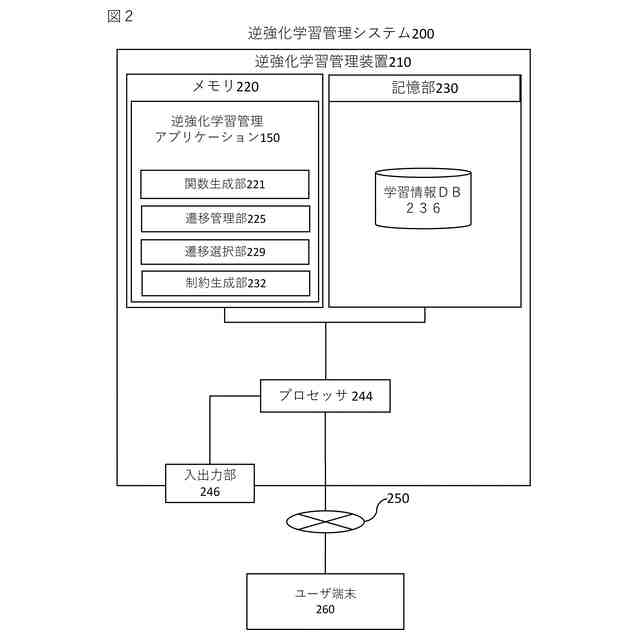
【選択図】図2
特許請求の範囲
【請求項1】
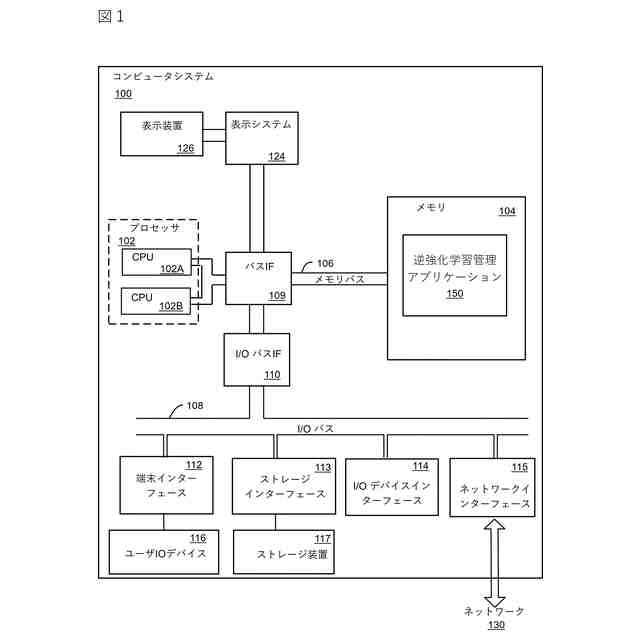
逆強化学習管理装置であって、
プロセッサとメモリと記憶部とを備え、
前記記憶部は、
所定のシナリオに関する学習情報を格納し、
前記メモリは、
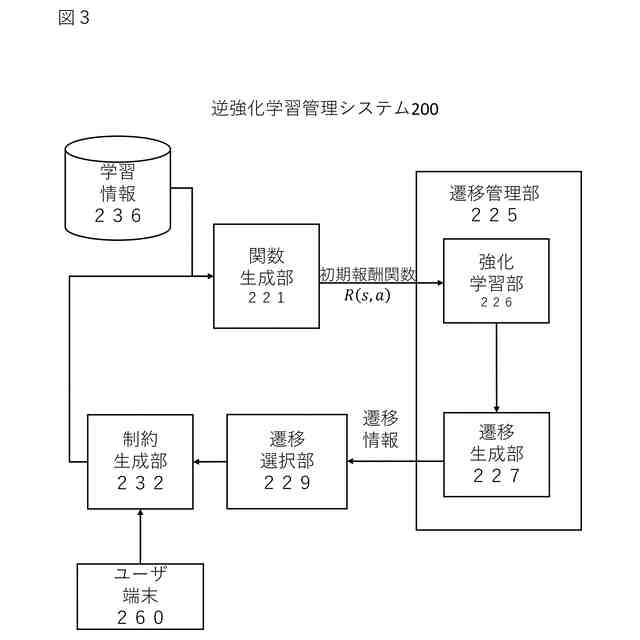
前記学習情報に基づいて、強化学習エージェントに与える報酬を規定する初期報酬関数を生成する関数生成部と、
前記初期報酬関数に基づいて、前記強化学習エージェントの挙動を規定する初期方策を生成し、前記初期方策を用いて、前記シナリオにおいて、特定の状態に対して実施する特定の行動を示す状態・行動ペアのシーケンスからなる遷移を含む遷移情報を生成する遷移管理部と、
前記遷移情報の中から、所定の分散基準を満たす遷移のサブセットを判定する遷移選択部と、
前記遷移のサブセットの中から、無効な状態・行動ペアを特定し、前記無効な状態・行動ペアに基づいて、前記初期報酬関数に対する制約を規定し、前記制約を前記初期報酬関数に対して適用することで、修正済みの報酬関数を生成する制約生成部、
として前記プロセッサを機能させるための処理命令を含むことを特徴とする逆強化学習管理装置。
続きを表示(約 3,600 文字)
【請求項2】
前記遷移管理部は、
前記シナリオについて、複数の異なる初期条件に対応する複数の遷移を前記遷移情報として生成する、
ことを特徴とする、請求項1に記載の逆強化学習管理装置。
【請求項3】
前記制約生成部は、
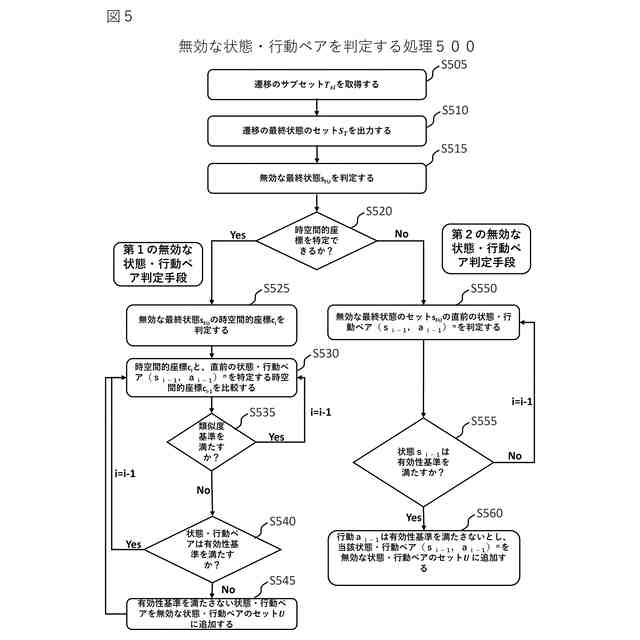
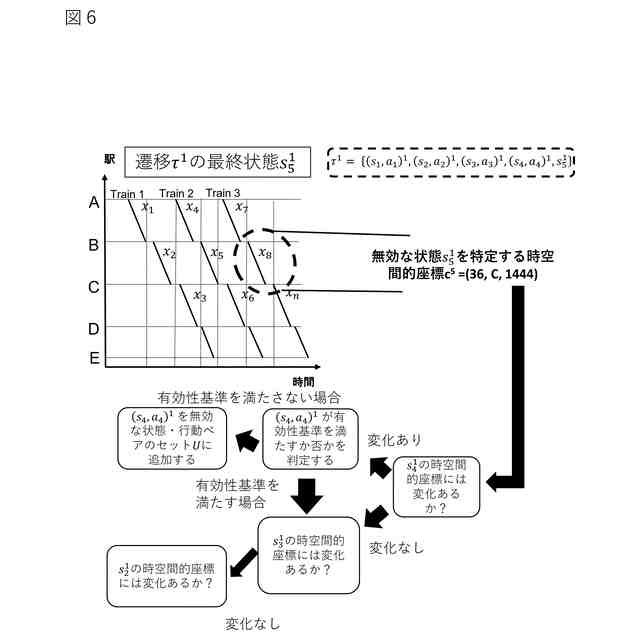
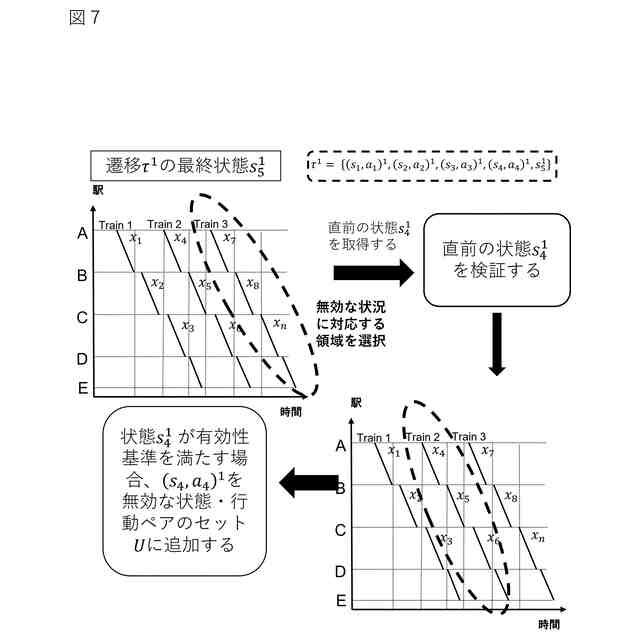
前記遷移のサブセットに含まれる第1の遷移における最終の状態・行動ペアである第1の状態・行動ペアを特定する第1の時空間的座標を判定し、
前記第1の遷移において、前記第1の状態・行動ペアに先行する第2の状態・行動ペアを特定する第2の時空間的座標を判定し、
前記第1の時空間的座標及び前記第2の時空間的座標が所定の類似度基準を満たさない場合、前記第2の状態・行動ペアが所定の有効性基準を満たすか否かを判定し、
前記第2の状態・行動ペアが所定の有効性基準を満たさないと判定した場合、前記第2の状態・行動ペアを前記無効な状態・行動ペアとして特定する、
ことを特徴とする、請求項1に記載の逆強化学習管理装置。
【請求項4】
前記制約生成部は、
前記第2の状態・行動ペアが所定の有効性基準を満たす場合、又は、前記第1の時空間的座標及び前記第2の時空間的座標が所定の類似度基準を満たす場合、前記第1の遷移において、前記第2の状態・行動ペアに先行する第3の状態・行動ペアを特定する第3の時空間的座標を判定し、
前記第2の時空間的座標及び前記第3の時空間的座標が所定の類似度基準を満たさない場合、前記第3の状態・行動ペアが所定の有効性基準を満たすか否かを判定し、
前記第3の状態・行動ペアが所定の有効性基準を満たさないと判定した場合、前記第3の状態・行動ペアを前記無効な状態・行動ペアとして特定する、
ことを特徴とする、請求項3に記載の逆強化学習管理装置。
【請求項5】
前記制約生成部は、
前記遷移のサブセットに含まれる第1の遷移における最終の状態・行動ペアである第1の状態・行動ペアに先行する第2の状態・行動ペアにおける第2の状態が所定の有効性基準を満たすか否かを判定し、
前記第2の状態が所定の有効性基準を満たす場合、前記第2の状態・行動ペアにおいて前記第2の状態に対応する第2の行動が前記有効性基準を満たさないと判定し、前記第2の状態・行動ペアを前記無効な状態・行動ペアとして特定する、
ことを特徴とする、請求項1に記載の逆強化学習管理装置。
【請求項6】
前記制約生成部は、
前記第2の状態が所定の有効性基準を満たさない場合、前記第2の状態・行動ペアに先行する第3の状態・行動ペアにおける第3の状態が所定の有効性基準を満たすか否かを判定し、
前記第3の状態が所定の有効性基準を満たす場合、前記第3の状態・行動ペアにおいて前記第3の状態に対応する第3の行動が前記有効性基準を満たさないと判定し、前記第3の状態・行動ペアを前記無効な状態・行動ペアとして特定する、
ことを特徴とする、請求項5に記載の逆強化学習管理装置。
【請求項7】
前記遷移管理部は、
前記修正済みの報酬関数を用いて、前記強化学習エージェントを訓練する、
ことを特徴とする、請求項1に記載の逆強化学習管理装置。
【請求項8】
逆強化学習管理装置において実行される逆強化学習管理方法であって、
前記逆強化学習管理装置は、
プロセッサとメモリと記憶部とを備え、
前記記憶部は、
所定のシナリオに関する学習情報を格納し、
前記メモリは、
前記学習情報に基づいて、強化学習エージェントに与える報酬を規定する初期報酬関数を生成する工程と、
前記初期報酬関数に基づいて、前記強化学習エージェントの挙動を規定する初期方策を生成する工程と、
前記初期方策を用いて、前記シナリオにおいて、特定の状態に対して実施する特定の行動を示す状態・行動ペアのシーケンスからなる遷移を含む遷移情報を生成する工程と、
前記遷移情報の中から、所定の分散基準を満たす遷移のサブセットを判定する工程と、
前記遷移のサブセットに含まれる第1の遷移における最終の状態・行動ペアである第1の状態・行動ペアを特定する第1の時空間的座標が特定可能か否かを判定する工程と、
前記第1の時空間的座標が特定可能の場合、前記第1の時空間的座標を判定する工程と、
前記第1の遷移において、前記第1の状態・行動ペアに先行する第2の状態・行動ペアを特定する第2の時空間的座標を判定する工程と、
前記第1の時空間的座標及び前記第2の時空間的座標が所定の類似度基準を満たさない場合、前記第2の状態・行動ペアが所定の有効性基準を満たすか否かを判定する工程と、
前記第2の状態・行動ペアが所定の有効性基準を満たさないと判定した場合、前記第2の状態・行動ペアを無効な状態・行動ペアとして特定する工程と、
前記第2の状態・行動ペアが所定の有効性基準を満たす場合、又は、前記第1の時空間的座標及び前記第2の時空間的座標が所定の類似度基準を満たす場合、前記第1の遷移において、前記第2の状態・行動ペアに先行する第3の状態・行動ペアを特定する第3の時空間的座標を判定する工程と、
前記第2の時空間的座標及び前記第3の時空間的座標が所定の類似度基準を満たさない場合、前記第3の状態・行動ペアが所定の有効性基準を満たすか否かを判定する工程と、
前記第3の状態・行動ペアが所定の有効性基準を満たさないと判定した場合、前記第3の状態・行動ペアを前記無効な状態・行動ペアとして特定する工程と、
前記第1の時空間的座標が特定可能でない場合、前記第1の状態・行動ペアに先行する第2の状態・行動ペアにおける第2の状態が所定の有効性基準を満たすか否かを判定する工程と、
前記第2の状態が所定の有効性基準を満たす場合、前記第2の状態・行動ペアにおいて前記第2の状態に対応する第2の行動が前記有効性基準を満たさないと判定し、前記第2の状態・行動ペアを前記無効な状態・行動ペアとして特定する工程と、
前記第2の状態が所定の有効性基準を満たさない場合、前記第2の状態・行動ペアに先行する第3の状態・行動ペアにおける第3の状態が所定の有効性基準を満たすか否かを判定する工程と、
前記第3の状態が所定の有効性基準を満たす場合、前記第3の状態・行動ペアにおいて前記第3の状態に対応する第3の行動が前記有効性基準を満たさないと判定し、前記第3の状態・行動ペアを前記無効な状態・行動ペアとして特定する工程と、
前記無効な状態・行動ペアに基づいて、前記初期報酬関数に対する制約を規定する工程と、
前記制約を前記初期報酬関数に対して適用することで、修正済みの報酬関数を生成する工程と、
を前記プロセッサに実行させる処理命令を含むことを特徴とする逆強化学習管理方法。
【請求項9】
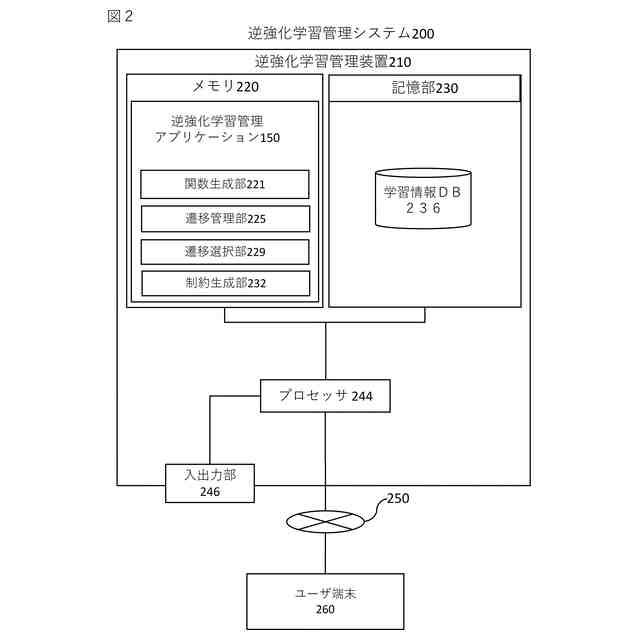
逆強化学習管理装置と
ユーザ端末とが通信ネットワークを介して接続されている逆強化学習管理システムであって、
前記逆強化学習管理装置は、
プロセッサとメモリと記憶部とを備え、
前記記憶部は、
所定のシナリオに関する学習情報を格納し、
前記メモリは、
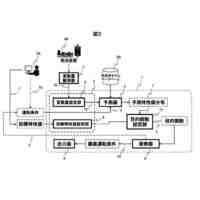
前記学習情報に基づいて、強化学習エージェントに与える報酬を規定する初期報酬関数を生成する関数生成部と、
前記初期報酬関数に基づいて、前記強化学習エージェントの挙動を規定する初期方策を生成し、前記初期方策を用いて、前記シナリオにおいて、特定の状態に対して実施する特定の行動を示す状態・行動ペアのシーケンスからなる遷移を含む遷移情報を生成する遷移管理部と、
前記遷移情報の中から、所定の分散基準を満たす遷移のサブセットを判定する遷移選択部と、
前記遷移のサブセットの中から、無効な状態・行動ペアを特定し、前記無効な状態・行動ペアに基づいて、前記初期報酬関数に対する制約を規定し、前記制約を前記初期報酬関数に対して適用することで、修正済みの報酬関数を生成する制約生成部と、
前記修正済みの報酬関数によって訓練された前記強化学習エージェントによる出力情報を前記ユーザ端末に出力する入出力部、
として前記プロセッサを機能させるための処理命令を含むことを特徴とする逆強化学習管理システム。
発明の詳細な説明
【技術分野】
【0001】
本開示は、逆強化学習管理装置、逆強化学習管理方法及び逆強化学習管理システムに関する。
続きを表示(約 2,200 文字)
【背景技術】
【0002】
Reinforcement Learning(RL;以下「強化学習」)は、スケジューリング問題、リソース管理、組織の運用など、様々な分野で活用されている。
【0003】
「強化学習」とは、機械学習の一種であり、エージェント(学習するシステム)が環境と相互作用しながら最適な行動を学習する手法である。より具体的には、このエージェントは、状態を観測し、その状態に応じて適切な行動を選択し、選択した行動に応じて報酬が与えられる。エージェントは、試行錯誤を通じて、報酬を最大化するような行動選択のルールを規定するポリシー(以下、「方策」)を学習することとなる手法である。
【0004】
エージェントに与えられる報酬は、いわゆる報酬関数によって計算される。様々な状態に対して最適な行動が選択できる強化学習エージェントを得るためには、適切な報酬関数の設計が重要である。しかし、この報酬関数は、様々な状態において、可能性がある多数の行動に対して適切な重み付を割り当てる必要があるため、手動で設計することは難しい。
【0005】
そこで、近年、報酬関数を自動で設計するInverse Reinforcement Learning(IRL;以下「逆強化学習」)が注目されている。逆強化学習では、様々な状態において、適切な行動を示す、専門家などによって作成された豊富な学習情報がある場合、当該学習情報を用いることで、適切な報酬をエージェントに与える報酬関数を自動で生成することができる。
【0006】
逆強化学習を用いて報酬関数を生成する従来の提案の1つとしては、Anwar, Usmanらによる研究(非特許文献1)が存在する。非特許文献1では、「現実世界の設定では、数学的に記述することが難しい制約が数多く存在する。しかし、強化学習(RL)の実世界での展開においては、RLエージェントは、安全に行動するためには、これらの制約を認識することが重要である。本研究では、制約を遵守するエージェントの振る舞いのデモンストレーションから制約を学習する問題を検討する。我々は、実験的にアプローチを検証し、フレームワークが、エージェントが尊重する最も可能性の高い制約を学習できることを示す。」
【先行技術文献】
【非特許文献】
【0007】
Anwar, Usman, Shehryar Malik, Alireza Aghasi and Ali Ahmed. “Inverse Constrained Reinforcement Learning.” International Conference on Machine Learning (2020). https://arxiv.org/abs/2011.09999
【発明の概要】
【発明が解決しようとする課題】
【0008】
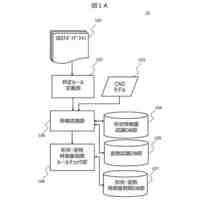
特許文献1には、学習対象の分野に関する学習情報を用いて、報酬関数に対して適用すべき制約を判定する手段が記載されている。
特許文献1は、学習対象の分野に関する豊富な学習情報が利用可能であることを前提としている。しかし、実際には、エージェントの行動選択に応じて適切な報酬を与える報酬関数を逆強化学習で生成するためには、大量の高精度の学習情報が必要であり、例えば列車スケジューリングのような複雑な問題の場合、発生し得る数多くの状態を考慮する学習情報の入手が困難である。仮に、不十分な学習情報に基づいて逆強化学習を行った場合、得る報酬関数は、例えば危険な行動に対して高い報酬を与えてしまい、このような報酬関数によって訓練されたエージェントは、事故を招く方策を学習してしまうことが考えられる。
学習情報が少ない状況であっても、高精度の報酬関数が生成可能な逆強化学習手段は、特許文献1では検討されていない。
【0009】
そこで、本開示は、学習情報が少ない状況であっても、高精度の報酬関数が生成可能な逆強化学習管理手段を提供することを目的とする。
【課題を解決するための手段】
【0010】
上記の課題を解決するために、代表的な本発明の逆強化学習装置は、プロセッサとメモリと記憶部とを備え、前記記憶部は、所定のシナリオに関する学習情報を格納し、
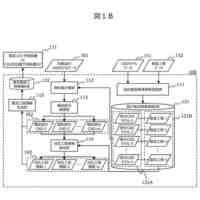
前記メモリは、前記学習情報に基づいて、強化学習エージェントに与える報酬を規定する初期報酬関数を生成する関数生成部と、前記初期報酬関数に基づいて、前記強化学習エージェントの挙動を規定する初期方策を生成し、前記初期方策を用いて、前記シナリオにおいて、特定の状態に対して実施する特定の行動を示す状態・行動ペアのシーケンスからなる遷移を含む遷移情報を生成する遷移管理部と、前記遷移情報の中から、所定の分散基準を満たす遷移のサブセットを判定する遷移選択部と、前記遷移のサブセットの中から、無効な状態・行動ペアを特定し、前記無効な状態・行動ペアに基づいて、前記初期報酬関数に対する制約を規定し、前記制約を前記初期報酬関数に対して適用することで、修正済みの報酬関数を生成する制約生成部として前記プロセッサを機能させるための処理命令を含む。
【発明の効果】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
株式会社日立製作所
回転電機
3日前
株式会社日立製作所
軌条車両
4日前
株式会社日立製作所
気体圧縮装置
今日
株式会社日立製作所
作業支援システム
1日前
株式会社日立製作所
軌道計画システム
3日前
株式会社日立製作所
診断装置および診断方法
今日
株式会社日立製作所
再生品販売支援システム
3日前
株式会社日立製作所
乗りかご及びエレベーター
3日前
株式会社日立製作所
制御装置、及び情報提示方法
2日前
株式会社日立製作所
設計支援システムおよび方法
4日前
株式会社日立製作所
乗り場ドア及びエレベーター
4日前
株式会社日立製作所
人工衛星及び人工衛星システム
3日前
株式会社日立製作所
最適化システム及び最適化方法
3日前
株式会社日立製作所
蓄電池部分の輸送および保管方法
3日前
株式会社日立製作所
電力変換装置および電力変換方法
3日前
株式会社日立製作所
原料照合システム及び原料照合方法
3日前
株式会社日立製作所
超電導コイルおよび超電導磁石装置
4日前
株式会社日立製作所
雲高計測システム及び雲高計測方法
3日前
株式会社日立製作所
電力取引システム及び電力取引方法。
1日前
株式会社日立製作所
障害検知システム、及び障害検知方法
1日前
株式会社日立製作所
意思決定支援システム及び意思決定方法
3日前
株式会社日立製作所
材料情報管理システム及び審査支援方法
3日前
株式会社日立製作所
製造情報推定装置および製造情報推定方法
4日前
株式会社日立製作所
支援装置、支援方法、及び支援プログラム
3日前
株式会社日立製作所
電力系統管理システム及び電力系統管理方法
今日
株式会社日立製作所
設計支援装置、プログラム及び設計支援方法
1日前
株式会社日立製作所
製造装置の運転条件を提供する方法及びシステム
3日前
株式会社日立製作所
エレベータシステム及び通信パケット解析対策方法
3日前
株式会社日立製作所
測定管理装置、測定管理システム及び測定管理方法
1日前
株式会社日立製作所
通信環境モデルを生成する装置、システムおよび方法
2日前
株式会社日立製作所
危険運転警告装置、車両、および、危険運転警告方法
3日前
株式会社日立製作所
動画検証装置、動画検証方法、及び動画検証システム
1日前
株式会社日立製作所
イベント分析装置,イベント分析方法およびプログラム
今日
株式会社日立製作所
リサイクル促進システム、および、リサイクル促進方法
1日前
株式会社日立製作所
攻撃検知ルール生成装置および攻撃検知ルール生成方法
1日前
株式会社日立製作所
使用量管理システム、データ処理装置及び使用量管理方法
2日前
続きを見る
他の特許を見る

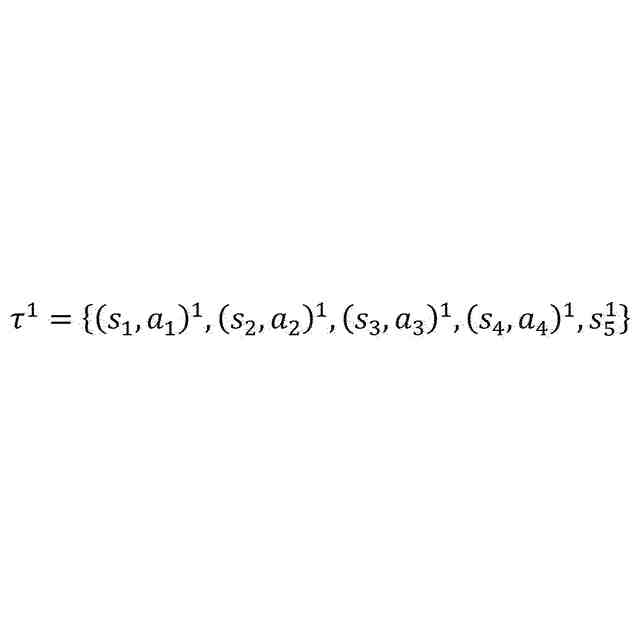

 特許ウォッチ
特許ウォッチ