TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025076663
公報種別
公開特許公報(A)
公開日
2025-05-16
出願番号
2023188412
出願日
2023-11-02
発明の名称
実況音声生成システム
出願人
国立研究開発法人産業技術総合研究所
代理人
個人
,
個人
主分類
G10L
13/02 20130101AFI20250509BHJP(楽器;音響)
要約
【課題】状況に対応してある程度定まった発話と柔軟な言語による発話とを異なる処理とすることで、リアルタイムな発話と柔軟性の高い発話を実現することができる実況音声生成システムを提供すること。
【解決手段】イベント状況についての状況データを取得する入力部1、状況データによって第1発話データを選択する第1処理部10、状況データによって第2発話データを生成する第2処理部20、第1発話データと、第1発話データを選択するための状況データの条件を記憶する第1発話データ記憶部3、第1発話データによる第1音声と第2発話データによる第2音声を生成する音声生成部11、21、第1音声と第2音声を出力する音声出力部2を備え、第1処理部10は第1発話データ記憶部3から第1発話データを選択し、第2処理部20は第1AI処理4によって第2発話データを生成し、音声出力部2は、第1音声を第2音声に優先して出力する。
【選択図】 図1
特許請求の範囲
【請求項1】
イベント状況について実況音声を出力する実況音声生成システムであって、
前記イベント状況についての状況データを取得する入力部と、
前記入力部で取得した前記状況データによって第1発話データを選択する第1処理部と、
前記入力部で取得した前記状況データによって第2発話データを生成する第2処理部と、
前記第1処理部で選択される第1発話データ、及び前記第1発話データを選択するための前記状況データの条件を記憶する第1発話データ記憶部と、
前記第1発話データによる第1音声及び前記第2発話データによる第2音声を生成する音声生成部と、
前記音声生成部で生成された前記第1音声及び前記第2音声を出力する音声出力部と
を備え、
前記第1処理部では、前記第1発話データ記憶部から前記第1発話データを選択し、
前記第2処理部では、第1AI処理によって前記第2発話データを生成し、
前記音声出力部では、前記第1音声を、前記第2音声に優先して出力する
ことを特徴とする実況音声生成システム。
続きを表示(約 1,300 文字)
【請求項2】
前記音声出力部では、前記第1音声を出力している間は前記第2音声を出力しない
ことを特徴とする請求項1に記載の実況音声生成システム。
【請求項3】
前記第1音声を出力している間に、前記第2発話データが生成されると、生成された前記第2発話データによる前記第2音声を生成することなく、前記第2処理部では、新たな前記状況データによる前記第2発話データを生成する
ことを特徴とする請求項1に記載の実況音声生成システム。
【請求項4】
前記第1音声を出力している間に、前記第2音声が生成されると、生成された前記第2音声を前記音声出力部から出力することなく、前記第2処理部では、新たな前記状況データによる前記第2発話データを生成する
ことを特徴とする請求項1に記載の実況音声生成システム。
【請求項5】
前記音声出力部では、前記第2音声を出力している間に、前記第1音声を出力する際には、前記第2音声の出力を停止する
ことを特徴とする請求項1に記載の実況音声生成システム。
【請求項6】
前記第2処理部では、前記第1音声が出力されることをトリガーとして前記第2発話データを生成する
ことを特徴とする請求項1に記載の実況音声生成システム。
【請求項7】
前記入力部で取得した前記状況データによって第3発話データを生成する第3処理部と、
前記第2処理部で生成される第2発話データ、及び前記第2発話データが生成される際の前記状況データを関連付けて記憶する第2発話データ記憶部と
を備え、
前記音声生成部では、前記第3発話データによる第3音声を生成し、
前記音声出力部では、前記音声生成部で生成された前記第3音声を出力し、
前記第3処理部では、前記第2発話データ記憶部に記憶されたデータを教師データとした第2AI処理によって前記第3発話データを生成し、
前記音声出力部では、前記第1音声を、前記第2音声及び前記第3音声に優先して出力する
ことを特徴とする請求項1に記載の実況音声生成システム。
【請求項8】
前記音声出力部では、前記第1音声を出力している間は前記第3音声を出力しない
ことを特徴とする請求項7に記載の実況音声生成システム。
【請求項9】
前記第1音声を出力している間に、前記第3発話データが生成されると、生成された前記第3発話データによる前記第3音声を生成することなく、前記第3処理部では、新たな前記状況データによる前記第3発話データを生成する
ことを特徴とする請求項7に記載の実況音声生成システム。
【請求項10】
前記第1音声を出力している間に、前記第3音声が生成されると、生成された前記第3音声を前記音声出力部から出力することなく、前記第3処理部では、新たな前記状況データによる前記第3発話データを生成する
ことを特徴とする請求項7に記載の実況音声生成システム。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本発明は、イベント状況について実況音声を出力する実況音声生成システムに関する。
続きを表示(約 7,600 文字)
【背景技術】
【0002】
F1などのモータースポーツを含むスポーツ映像には、例えば、「次は最終の直線ゾーン、追い抜いていけるか?」のような実況音声が付与され、視聴者に状況説明や実況者の主観的なコメントが伝えられる。視聴者は実況を聞きながら映像を観ることで、状況をより深く理解し、観戦をより楽しむことができる。実況は多くのスポーツ映像やビデオゲーム映像に付与され、視聴者を楽しませる重要な役割を果たし、映像そのものの価値向上も期待できる。一方、実況付与には対象スポーツやイベントに関する知識や相応の話術が必要となることから、オンライン上に存在するスポーツ映像やビデオゲーム映像の多くには実況が付与されていない。
実況の一例として、レーシングゲーム映像に対する実況に着目する。このような実況では映像中で起こる重要なイベントについて、適切なタイミングで短時間の間に発話する必要がある。従来の言語生成研究では主に、“何について発話するか”というプランニングの問題と、“どのように発話するか”という言語の表層化の問題に分けて研究されてきた。実況生成においては、従来から取り組まれてきたこれらの問題に加え、“いつ発話するか”、“どの程度の時間発話するか”、“どの程度詳しく発話するか”といった従来考慮されてこなかった問題に対処する必要がある。発話タイミングを同定したり、実況発話を生成するためには、映像などで表現された時系列データを考慮する必要がある。これは、例えば画像キャプション生成のような時間軸を考慮しない言語生成の設定やストーリー生成といった発話タイミングがあらかじめ与えられる問題設定とは異なる。
従来の言語生成研究において、映像や画像といった視覚情報を入力する設定は多く存在する。しかし、実況生成のために映像を正しく認識することは容易ではない。例えば、実況では車両間の細かな位置関係についてしばしば述べられ、空撮映像のように似通ったビデオフレーム系列から車両の位置関係のわずかな違いを認識する必要がある。一方、画像キャプション生成では、「人が踊っている」などの必ずしもオブジェクト間の軽微な違いを捉える必要のないテキストの出力を想定している。このような背景から、レースの状況をより正確に捉えるため、映像に加え、時系列状況データを入力として用いることが有効である。状況データには、レーシングカーの座標位置、速度、及びハンドル角度といったサーキットやレーシングカーに関する複数の数値データが含まれる。実際のF1レースにおいても、複数のセンサーから300種類以上の数値データがリアルタイムに計測され、モータースポーツ以外の分野においても、サッカー選手の位置情報をGPSで取得しており、様々なスポーツで状況データを活用する試みが広がっている。
ところで、特許文献1は、ゲーム展開に対応した実況中継を自動的に行うゲーム実況中継装置を提案している。特許文献1のゲーム実況中継装置では、予め複数のゲーム展開パターンに対応させた所定の実況中継用音声データが音声データ記憶手段に記憶され、ゲームシステムのゲーム展開パターンを判別し、ゲーム展開パターンに対応した音声データの読み出し指令を出力する。
特許文献2は、特許文献1のゲーム実況中継装置と同様に、進行されるゲームの状況に応じた実況内容が規定された実況データをあらかじめ記憶しているが、ゲーム内容に対する着目点に適合するような少なくとも2種類の実況軸が決定され、これらの実況軸に対応する実況データに従って実況内容を決定することで、現実のアナウンサーのように複数の切り口で試合を実況するというような多面的な実況を実現できる装置を提案している。
特許文献3は、機械学習の学習済みモデルに基づいて機能するように構成された音声情報生成部を有することで、実況などの音声出力を、ゲームの状況や実況などの会話の流れに沿って行えるシステムを提案している。
【先行技術文献】
【特許文献】
【0003】
特開平8-215433号公報
特開2013-111178号公報
特開2021-194229号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
特許文献1や特許文献2のように、実況データをあらかじめ記憶している場合には、リアルタイム性に優れるが、「次は最終の直線ゾーン、追い抜いていけるか?」のような、状況説明とともに実況者の主観的なコメントを発話させることは難しい。
一方、特許文献3のように、機械学習の学習済みモデルに基づいて音声情報を生成する場合には、状況説明とともに実況者の主観的なコメントを発話させることができるが、リアルタイム性に劣る。
【0005】
本発明は、状況に対応してある程度定まった発話と柔軟な言語による発話とを異なる処理とすることで、リアルタイムな発話と柔軟性の高い発話を実現することができる実況音声生成システムを提供することを目的とする。
【課題を解決するための手段】
【0006】
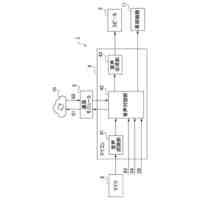
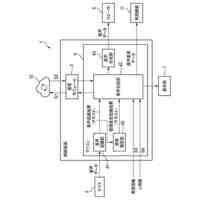
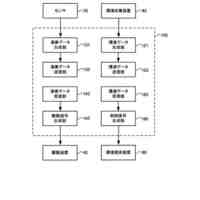
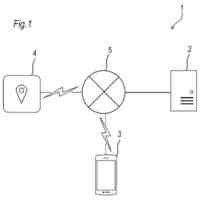
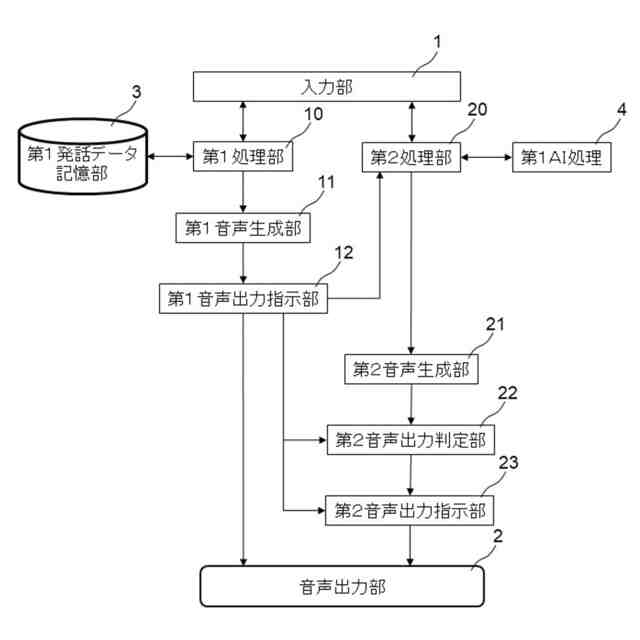
請求項1記載の本発明の実況音声生成システムは、イベント状況について実況音声を出力する実況音声生成システムであって、前記イベント状況についての状況データを取得する入力部1と、前記入力部1で取得した前記状況データによって第1発話データを選択する第1処理部10と、前記入力部1で取得した前記状況データによって第2発話データを生成する第2処理部20と、前記第1処理部10で選択される第1発話データ、及び前記第1発話データを選択するための前記状況データの条件を記憶する第1発話データ記憶部3と、前記第1発話データによる第1音声及び前記第2発話データによる第2音声を生成する音声生成部11、21と、前記音声生成部11、21で生成された前記第1音声及び前記第2音声を出力する音声出力部2とを備え、前記第1処理部10では、前記第1発話データ記憶部3から前記第1発話データを選択し、前記第2処理部20では、第1AI処理4によって前記第2発話データを生成し、前記音声出力部2では、前記第1音声を、前記第2音声に優先して出力することを特徴とする。
請求項2記載の本発明は、請求項1に記載の実況音声生成システムにおいて、前記音声出力部2では、前記第1音声を出力している間は前記第2音声を出力しないことを特徴とする。
請求項3記載の本発明は、請求項1に記載の実況音声生成システムにおいて、前記第1音声を出力している間に、前記第2発話データが生成されると、生成された前記第2発話データによる前記第2音声を生成することなく、前記第2処理部20では、新たな前記状況データによる前記第2発話データを生成することを特徴とする。
請求項4記載の本発明は、請求項1に記載の実況音声生成システムにおいて、前記第1音声を出力している間に、前記第2音声が生成されると、生成された前記第2音声を前記音声出力部2から出力することなく、前記第2処理部20では、新たな前記状況データによる前記第2発話データを生成することを特徴とする。
請求項5記載の本発明は、請求項1に記載の実況音声生成システムにおいて、前記音声出力部2では、前記第2音声を出力している間に、前記第1音声を出力する際には、前記第2音声の出力を停止することを特徴とする。
請求項6記載の本発明は、請求項1に記載の実況音声生成システムにおいて、前記第2処理部20では、前記第1音声が出力されることをトリガーとして前記第2発話データを生成することを特徴とする。
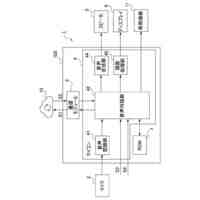
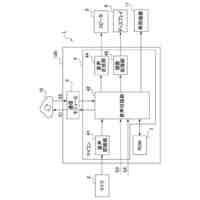
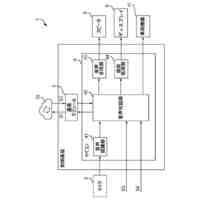
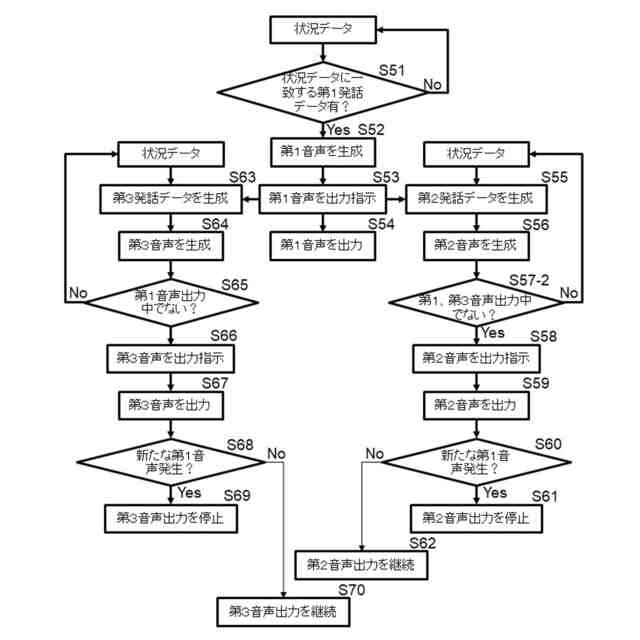
請求項7記載の本発明は、請求項1に記載の実況音声生成システムにおいて、前記入力部1で取得した前記状況データによって第3発話データを生成する第3処理部30と、前記第2処理部20で生成される第2発話データ、及び前記第2発話データが生成される際の前記状況データを関連付けて記憶する第2発話データ記憶部5とを備え、前記音声生成部31では、前記第3発話データによる第3音声を生成し、前記音声出力部2では、前記音声生成部31で生成された前記第3音声を出力し、前記第3処理部30では、前記第2発話データ記憶部5に記憶されたデータを教師データとした第2AI処理6によって前記第3発話データを生成し、前記音声出力部2では、前記第1音声を、前記第2音声及び前記第3音声に優先して出力することを特徴とする。
請求項8記載の本発明は、請求項7に記載の実況音声生成システムにおいて、前記音声出力部2では、前記第1音声を出力している間は前記第3音声を出力しないことを特徴とする。
請求項9記載の本発明は、請求項7に記載の実況音声生成システムにおいて、前記第1音声を出力している間に、前記第3発話データが生成されると、生成された前記第3発話データによる前記第3音声を生成することなく、前記第3処理部30では、新たな前記状況データによる前記第3発話データを生成することを特徴とする。
請求項10記載の本発明は、請求項7に記載の実況音声生成システムにおいて、前記第1音声を出力している間に、前記第3音声が生成されると、生成された前記第3音声を前記音声出力部2から出力することなく、前記第3処理部30では、新たな前記状況データによる前記第3発話データを生成することを特徴とする。
請求項11記載の本発明は、請求項7に記載の実況音声生成システムにおいて、前記音声出力部2では、前記第3音声を出力している間に、前記第1音声を出力する際には、前記第3音声の出力を停止することを特徴とする。
請求項12記載の本発明は、請求項7に記載の実況音声生成システムにおいて、前記第3処理部30では、前記第1音声が出力されることをトリガーとして前記第3発話データを生成することを特徴とする。
請求項13記載の本発明の実況音声生成システムは、イベント状況について実況音声を出力する実況音声生成システムであって、コンピュータが、取得した状況データが第1発話データを選択するための条件に一致する場合には、一致する前記第1発話データを選択する第1処理ステップと、前記第1処理ステップで選択された前記第1発話データによる第1音声を生成する第1音声生成ステップと、前記第1音声生成ステップで生成された前記第1音声による出力を指示する第1音声出力指示ステップと、前記第1音声出力指示ステップで指示された前記第1音声を出力する音声出力ステップと、前記第1音声出力指示ステップによる指示が行われると、第1AI処理4によって第2発話データを生成する第2処理ステップと、前記第2処理ステップで生成された前記第2発話データによる第2音声を生成する第2音声生成ステップと、前記第1音声による出力が行われていなければ、前記第2音声生成ステップで生成された前記第2音声による出力指示を行う第2音声出力指示ステップとを実行し、前記第1音声による出力が行われていれば、前記第2音声生成ステップで生成された前記第2音声による出力を行うことなく、前記第2処理ステップで、新たな前記状況データによる前記第2発話データを生成することを特徴とする。
請求項14記載の本発明は、請求項13に記載の実況音声生成システムにおいて、前記第2音声出力指示ステップで前記第2音声による出力を行っている間に、前記第1音声出力指示ステップで前記第1音声による出力が指示されると、前記第2音声による出力を停止して前記第1音声による出力を行うことを特徴とする。
請求項15記載の本発明の実況音声生成システムは、イベント状況について実況音声を出力する実況音声生成システムであって、コンピュータが、取得した状況データが第1発話データを選択するための条件に一致する場合には、一致する前記第1発話データを選択する第1処理ステップと、前記第1処理ステップで選択された前記第1発話データによる第1音声を生成する第1音声生成ステップと、前記第1音声生成ステップで生成された前記第1音声による出力を指示する第1音声出力指示ステップと、前記第1音声出力指示ステップで指示された前記第1音声を出力する音声出力ステップと、前記第1音声出力指示ステップによる指示が行われると、第1AI処理4によって第2発話データを生成する第2処理ステップと、前記第2処理ステップで生成された前記第2発話データによる第2音声を生成する第2音声生成ステップと、前記第1音声出力指示ステップによる指示が行われると、第2AI処理6によって第3発話データを生成する第3処理ステップと、前記第3処理ステップで生成された前記第3発話データによる第3音声を生成する第3音声生成ステップと、前記第1音声による出力が行われていなければ、前記第3音声生成ステップで生成された前記第3音声による出力を行う第3音声出力指示ステップと前記第1音声による出力、及び前記第3音声による出力が行われていなければ、前記第2音声生成ステップで生成された前記第2音声による出力を行う第2音声出力指示ステップとを実行することを特徴とする。
請求項16記載の本発明は、請求項15に記載の実況音声生成システムにおいて、前記第1音声による出力が行われていれば、前記第2音声生成ステップで生成された前記第2音声による出力を行うことなく、前記第2処理ステップで、新たな前記状況データによる前記第2発話データを生成することを特徴とする。
請求項17記載の本発明は、請求項15に記載の実況音声生成システムにおいて、前記第1音声による出力が行われていれば、前記第3音声生成ステップで生成された前記第3音声による出力を行うことなく、前記第3処理ステップで、新たな前記状況データによる前記第3発話データを生成することを特徴とする。
請求項18記載の本発明は、請求項15に記載の実況音声生成システムにおいて、前記第3音声による出力が行われていれば、前記第2音声生成ステップで生成された前記第2音声による出力を行うことなく、前記第2処理ステップで、新たな前記状況データによる前記第2発話データを生成することを特徴とする。
請求項19記載の本発明は、請求項15に記載の実況音声生成システムにおいて、前記第2音声出力指示ステップで前記第2音声による出力を行っている間に、前記第1音声出力指示ステップで前記第1音声による出力が指示されると、前記第2音声による出力を停止して前記第1音声による出力を行うことを特徴とする。
請求項20記載の本発明は、請求項15に記載の実況音声生成システムにおいて、前記第3音声出力指示ステップで前記第3音声による出力を行っている間に、前記第1音声出力指示ステップで前記第1音声による出力が指示されると、前記第3音声による出力を停止して前記第1音声による出力を行うことを特徴とする。
【0007】
本発明によれば、第1発話データと第2発話データとを用いることで、リアルタイム性が要求される発話と柔軟性の高い発話とを実況音声として出力することができ、イベント状況をより深く理解することができ、第1音声を第2音声に優先して出力することで、ある程度定まった状況説明をタイムリーに確実に出力し、状況説明の必要が無い期間に柔軟性の高い発話を出力できるので、無音声の期間が少なく自然な実況音声を実現できる。
【図面の簡単な説明】
【0008】
本発明の一実施例における実況音声生成システムを機能実現手段で表したブロック図
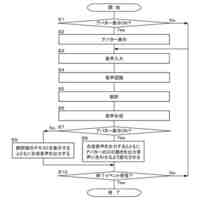
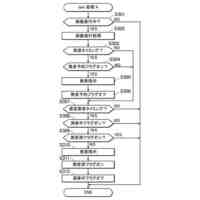
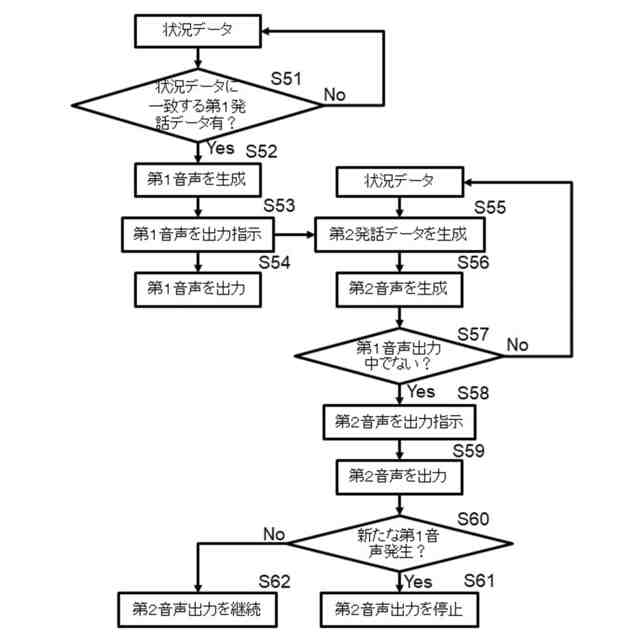
同実況音声生成システムでの処理流れを示すフロー図
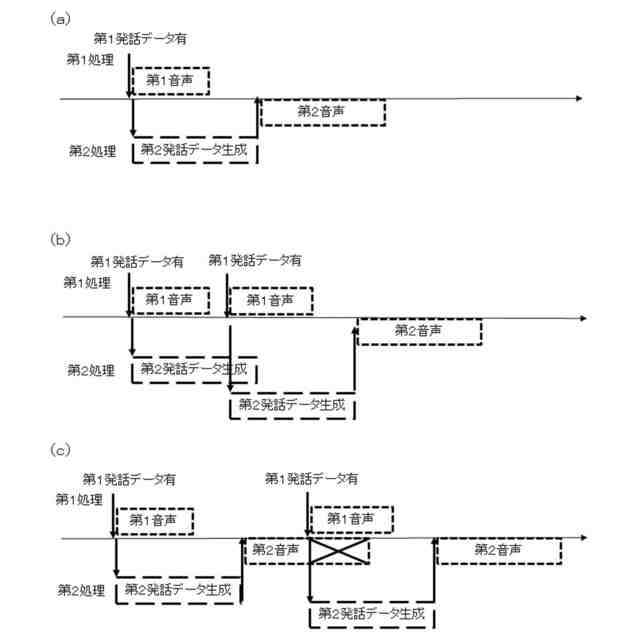
同実況音声生成システムでの処理を示す説明図
本発明の他の実施例における実況音声生成システムを機能実現手段で表したブロック図
同実況音声生成システムでの処理流れを示すフロー図
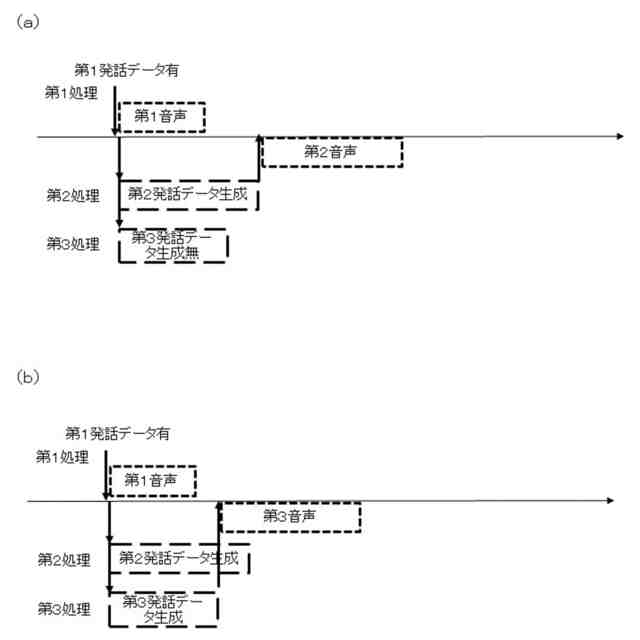
同実況音声生成システムでの第2処理と第3処理との関係を示す説明図
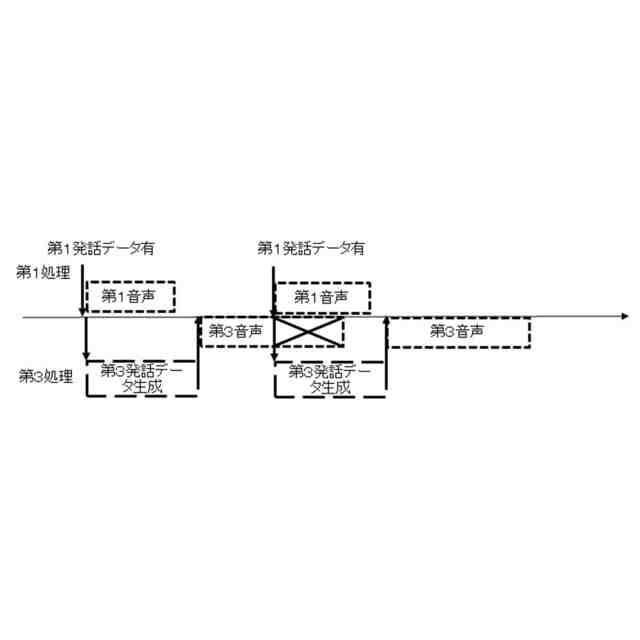
同実況音声生成システムでの第2処理の処理中に第1音声出力が発生した場合を示す説明図
同実況音声生成システムでの第3音声の出力中に第1音声出力が発生した場合を示す説明図
【発明を実施するための形態】
【0009】
本発明の第1の実施の形態による実況音声生成システムは、イベント状況についての状況データを取得する入力部と、入力部で取得した状況データによって第1発話データを選択する第1処理部と、入力部で取得した状況データによって第2発話データを生成する第2処理部と、第1処理部で選択される第1発話データ、及び第1発話データを選択するための状況データの条件を記憶する第1発話データ記憶部と、第1発話データによる第1音声及び第2発話データによる第2音声を生成する音声生成部と、音声生成部で生成された第1音声及び第2音声を出力する音声出力部とを備え、第1処理部では、第1発話データ記憶部から第1発話データを選択し、第2処理部では、第1AI処理によって第2発話データを生成し、音声出力部では、第1音声を、第2音声に優先して出力するものである。本実施の形態によれば、第1発話データ記憶部に記憶している第1発話データと、第1AI処理によって生成される第2発話データとを用いることで、リアルタイム性が要求される発話と柔軟性の高い発話とを実況音声として出力することができ、イベント状況をより深く理解することができる。また、本実施の形態によれば、第1音声を第2音声に優先して出力することで、ある程度定まった状況説明をタイムリーに確実に出力し、状況説明の必要が無い期間に柔軟性の高い発話を出力できるので、無音声の期間が少なく自然な実況音声を実現できる。
【0010】
本発明の第2の実施の形態は、第1の実施の形態による実況音声生成システムにおいて、音声出力部では、第1音声を出力している間は第2音声を出力しないものである。本実施の形態によれば、ある程度定まった状況説明をタイムリーに確実に出力することができる。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
個人
10デジタルサラウンドラジオ
14日前
三井化学株式会社
遮音構造体
2日前
三井化学株式会社
遮音構造体
23日前
矢崎総業株式会社
車両用対話システム
8日前
矢崎総業株式会社
車両用対話システム
8日前
矢崎総業株式会社
車両用対話システム
8日前
トヨタ自動車株式会社
音声制御装置
22日前
矢崎総業株式会社
車両用対話システム
8日前
矢崎総業株式会社
車両用対話システム
8日前
矢崎総業株式会社
車両用対話システム
8日前
株式会社第一興商
カラオケ装置
4日前
ヤマハ株式会社
鍵盤装置
3日前
ヤマハ株式会社
鍵盤楽器
22日前
株式会社しくみ
音声翻訳プログラム
24日前
学校法人 工学院大学
音響拡散パネル
3日前
株式会社Gottsu
サキソフォーン向けねじ込み式スクリュー
16日前
日本放送協会
音声認識装置およびプログラム
8日前
国立研究開発法人産業技術総合研究所
実況音声生成システム
今日
株式会社エクシング
携帯端末用プログラム、及び、カラオケシステム
8日前
株式会社田中
防音材を充填した金属パイプ
29日前
株式会社JVCケンウッド
情報処理装置、情報処理方法、及びプログラム
1日前
カシオ計算機株式会社
電子楽器、方法およびプログラム
16日前
アルプスアルパイン株式会社
音場制御システム及び音場制御方法
3日前
カシオ計算機株式会社
楽音処理装置、方法およびプログラム
16日前
日本放送協会
演奏箇所追跡装置及びそのプログラム
14日前
個人
レッスン楽譜、レッスン楽譜の表示方法、レッスン方法およびプログラム
7日前
株式会社コルグ
模倣音信号生成装置、電子楽器、非線形システム同定方法
7日前
ビーサイズ株式会社
情報処理装置、情報処理端末、情報処理方法、情報処理プログラム
14日前
カシオ計算機株式会社
センサ装置、電子機器、および電子楽器
22日前
Wovn Technologies株式会社
動画編集装置及びプログラム
14日前
BOLDLY株式会社
情報処理装置、サイレン音判定方法、サイレン音判定プログラム
7日前
株式会社コルグ
ピッチ表示装置、ピッチ表示制御装置、プログラム
1日前
ピクシーダストテクノロジーズ株式会社
吸音構造体、音響システム、および車両
3日前
カシオ計算機株式会社
情報処理装置、電子楽器、発音制御方法及びプログラム
16日前
株式会社博報堂
音声データ分析装置、音声データ分析方法およびコンピュータプログラム
24日前
ヤマハ株式会社
音声処理方法、音声処理システム、プログラムおよび音声処理ソフトウェア
15日前
続きを見る
他の特許を見る




 特許ウォッチ
特許ウォッチ