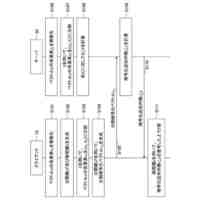
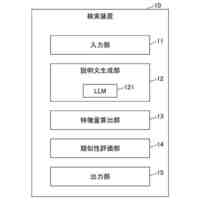
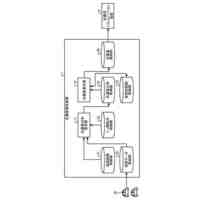
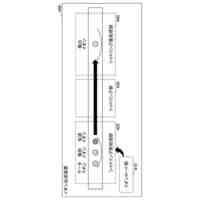
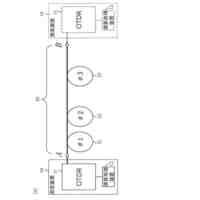
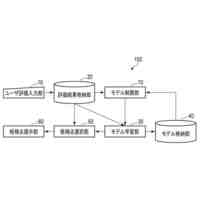
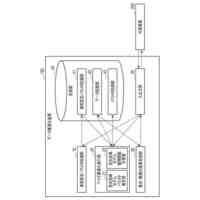
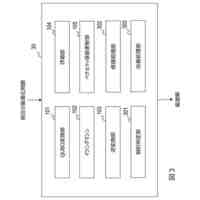
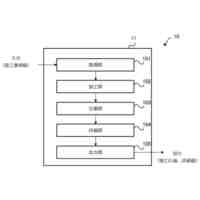
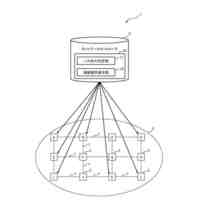
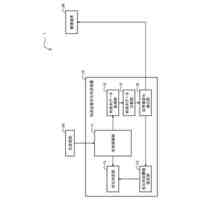
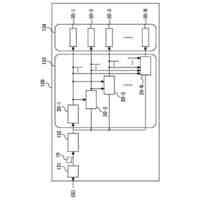
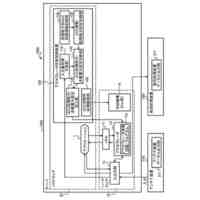
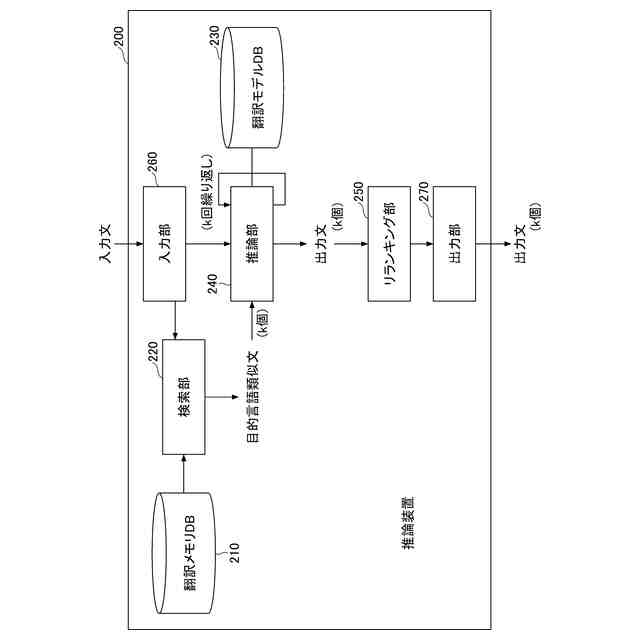
発明の詳細な説明【技術分野】 【0001】 本発明は、ニューラルネットワークを用いて機械翻訳を行う技術に関連するものである。 続きを表示(約 1,900 文字)【背景技術】 【0002】 高品質な対訳データの集合である翻訳メモリ(translation memory)を利用したニューラル機械翻訳に関する従来技術として、例えば非特許文献1、2に開示された技術がある。 【0003】 非特許文献1、2に開示された技術では、入力文と、翻訳メモリ中の原言語文との間の類似度に基づいて、入力文に類似する原言語文と対になる目的言語文を抽出し、当該目的言語文と入力文とを連結して翻訳モデルへの入力としている。このような処理により、ニューラル機械翻訳のアーキテクチャを変更することなく翻訳精度を向上させることができる。 【先行技術文献】 【非特許文献】 【0004】 Bram Bulte and Arda Tezcan. Neural fuzzy repair: Integrating fuzzy matches into neural machine translation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pp. 1800-1809, Florence, Italy, July 2019. Association for Computational Linguistics. Nabil Hossain, Marjan Ghazvininejad, and Luke Zettlemoyer. Simple and effective retrieve-edit-rerank text generation. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 2532-2538, Online, July 2020. Association for Computational Linguistics. 【発明の概要】 【発明が解決しようとする課題】 【0005】 言語対あるいは翻訳対象領域によっては、十分な量の対訳データが存在しない場合がある。翻訳メモリとして十分な量の対訳データが存在しない場合、非特許文献1、2に開示された手法を適用することができない。 【0006】 本発明は上記の点に鑑みてなされたものであり、翻訳メモリとして対訳データを用いることなく、原言語入力文と、当該原言語入力文に類似する目的言語文とを用いた翻訳を行うための技術を提供することを目的とする。 【課題を解決するための手段】 【0007】 開示の技術によれば、原言語入力文をクエリとした言語横断検索を行うことにより、目的言語文の集合から前記原言語入力文に類似する複数の類似訳文を抽出する検索部と、 前記原言語入力文と前記複数の類似訳文における各類似訳文とを用いて翻訳を行うことにより、複数の出力候補文を生成する推論部と、 前記複数の出力候補文に対するリランキングを行うリランキング部と を備える推論装置が提供される。 【発明の効果】 【0008】 開示の技術によれば、翻訳メモリとして対訳データを用いることなく、原言語入力文と、当該原言語入力文に類似する目的言語文とを用いた翻訳を行うことが可能となる。 【図面の簡単な説明】 【0009】 入力文と目的言語文の対を翻訳モデルへ入力する様子を示す図である。 訓練装置100の構成例を示す図である。 訓練装置100の動作例を説明するためのフローチャートである。 推論装置200の構成例を示す図である。 推論装置200の動作例を説明するためのフローチャートである。 推論処理の流れを示す図である。 実験で用いた訓練文、開発文、テスト文、及び、翻訳メモリ(目的言語文)それぞれについての文数を示す図である。 類似訳文検索法とリランキング法の違いによる翻訳精度の比較を示す図である。 装置のハードウェア構成例を示す図である。 【発明を実施するための形態】 【0010】 以下、図面を参照して本発明の実施の形態(本実施の形態)を説明する。以下で説明する実施の形態は一例に過ぎず、本発明が適用される実施の形態は、以下の実施の形態に限られるわけではない。 (【0011】以降は省略されています)
特許ウォッチbot のツイートを見る
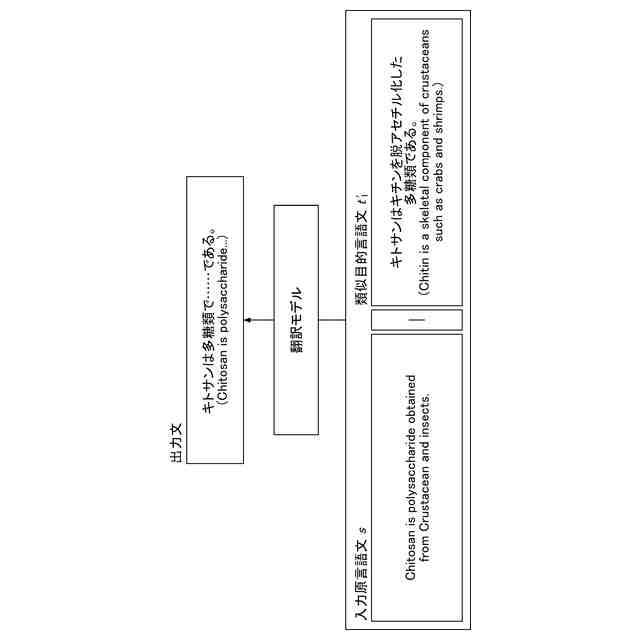
この特許をJ-PlatPat(特許庁公式サイト)で参照する






 特許ウォッチ
特許ウォッチ