TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025135075
公報種別
公開特許公報(A)
公開日
2025-09-18
出願番号
2024032655
出願日
2024-03-05
発明の名称
情報処理システム、音声認識システム、情報処理方法、及びプログラム
出願人
株式会社リコー
代理人
個人
,
個人
主分類
G10L
15/22 20060101AFI20250910BHJP(楽器;音響)
要約
【課題】音声認識の精度向上に係る時間およびコストを低減させること。
【解決手段】本発明は、端末装置とネットワークを介して通信可能な情報処理システムであって、1人以上のユーザーにより発話された音声データの音声認識結果を取得する音声認識結果取得部と、前記音声認識結果と、前記1人以上のユーザーに関連付けられた固有語彙と、を自然言語処理のモデルである大規模言語モデルに送信し、前記大規模言語モデルが該固有語彙に基づいて前記音声認識結果を修正した修正後の音声認識結果を前記大規模言語モデルから取得する修正部と、取得した前記修正後の音声認識結果を、前記端末装置に対して送信する通信部と、を有する。
【選択図】図14
特許請求の範囲
【請求項1】
端末装置とネットワークを介して通信可能な情報処理システムであって、
1人以上のユーザーにより発話された音声データの音声認識結果を取得する音声認識結果取得部と、
前記音声認識結果と、前記1人以上のユーザーに関連付けられた固有語彙と、を自然言語処理のモデルである大規模言語モデルに送信し、前記大規模言語モデルが該固有語彙に基づいて前記音声認識結果を修正した修正後の音声認識結果を前記大規模言語モデルから取得する修正部と、
取得した前記修正後の音声認識結果を、前記端末装置に対して送信する通信部と、
を有する情報処理システム。
続きを表示(約 1,600 文字)
【請求項2】
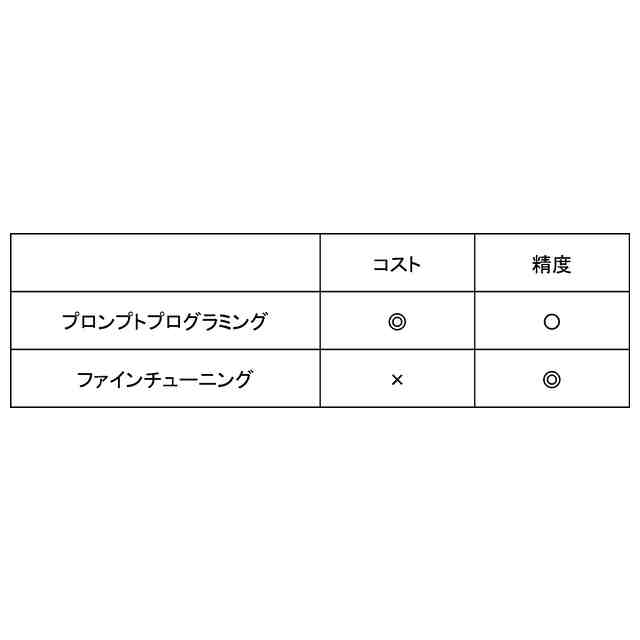
前記修正部は、前記大規模言語モデルに自然言語で処理の内容を通知するプロンプトプログラミングを用いて、前記音声認識結果取得部が取得した前記音声認識結果の修正を要求する、請求項1に記載の情報処理システム。
【請求項3】
前記音声認識結果取得部は、音声ファイルに含まれる全ての音声データの音声認識結果を取得し、
前記修正部は、前記全ての音声データが音声認識された全ての音声認識結果の修正を1回又は複数回に分けて前記大規模言語モデルに要求する、請求項1に記載の情報処理システム。
【請求項4】
前記音声認識結果取得部は、前記端末装置から送信された音声データがリアルタイムに音声認識された前記音声認識結果を取得し、
前記通信部は、前記音声認識結果が取得した前記音声認識結果を前記端末装置に送信し、
前記修正部は、前記通信部が前記音声認識結果を前記端末装置に送信した後に、前記1人以上のユーザーに関連付けられた固有語彙を用いて前記大規模言語モデルが前記音声認識結果を修正した修正後の音声認識結果を前記大規模言語モデルから受信し、
前記通信部は、前記修正部が取得した前記修正後の音声認識結果を前記端末装置に送信する、請求項1に記載の情報処理システム。
【請求項5】
前記修正部は、前記ユーザーに関連付けられた固有語彙及び音声認識結果と共に前記音声認識結果の修正要否を前記大規模言語モデルに問い合わせ、
修正が必要であるという応答を前記大規模言語モデルから受信した場合、
前記修正部は、前記1人以上のユーザーに関連付けられた固有語彙を用いて前記大規模言語モデルが前記音声認識結果を修正した修正後の音声認識結果を前記大規模言語モデルから受信する、請求項1に記載の情報処理システム。
【請求項6】
前記修正部は、前記大規模言語モデルによって修正が必要と判断された場合に、前記固有語彙に基づいて前記音声認識結果を修正し、前記修正が必要と判断されなかった場合に、前記固有語彙に基づいた前記音声認識結果の修正をしない、請求項5に記載の情報処理システム。
【請求項7】
前記情報処理システムは更に、前記1人以上のユーザーのうちの所定のユーザーと、前記端末装置に対して前記所定のユーザーが入力した前記固有語彙と、を関連付けて登録する固有語彙記憶部を有する、請求項1に記載の情報処理システム。
【請求項8】
前記音声認識結果取得部は、End-to-Endモデルで音声認識された前記音声認識結果を取得する、請求項1に記載の情報処理システム。
【請求項9】
端末装置と、情報処理システムと、前記情報処理システムと自然言語処理のモデルである大規模言語モデルを有する言語処理装置と、がネットワークを介してそれぞれ通信可能に接続された音声認識システムであって、
前記情報処理システムは、
1人以上のユーザーにより発話された音声データの音声認識結果を取得する音声認識結果取得部と、
前記音声認識結果と、前記1人以上のユーザーに関連付けられた固有語彙と、を前記言語処理装置に送信し、前記言語処理装置の前記大規模言語モデルが該固有語彙に基づいて前記音声認識結果を修正した修正後の音声認識結果を前記言語処理装置から取得する修正部と、
取得した前記修正後の音声認識結果を前記端末装置に対して送信する通信部と、を有し、
前記端末装置は、
前記情報処理システムから受信した前記修正後の音声認識結果を表示部に表示させる表示制御部を有する音声認識システム。
【請求項10】
前記大規模言語モデルは、前記音声認識結果取得部が取得した前記音声認識結果に含まれる1つ以上の文字を、前記固有語彙に含まれる文字列で修正する、請求項9に記載の音声認識システム。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本発明は、情報処理システム、音声認識システム、情報処理方法、及びプログラムに関する。
続きを表示(約 2,400 文字)
【背景技術】
【0002】
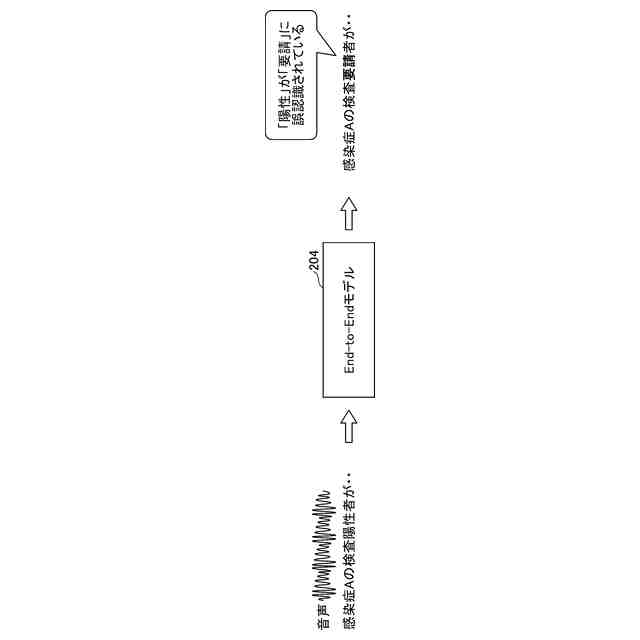
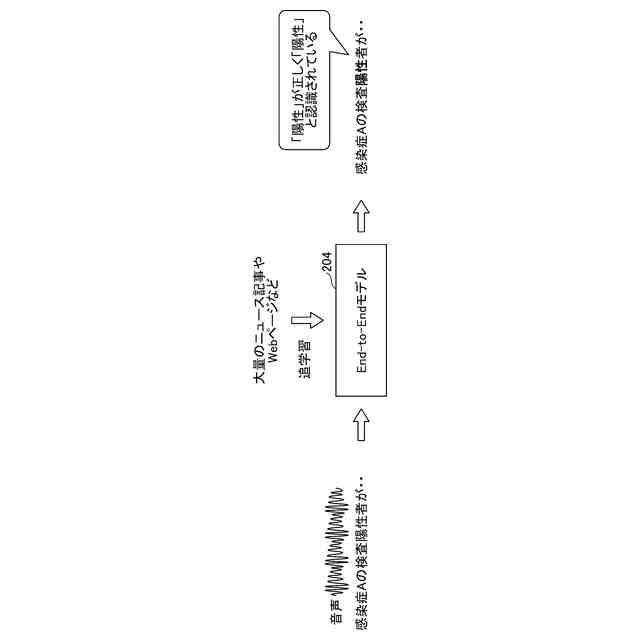
高精度かつ頑健性に優れた音声認識モデルとして、End-to-Endモデルが知られている。End-to-Endモデルは従来のDNN-HMMモデル又はGMM-HMMモデルのように、音響モデル/言語モデル/発音辞書に機能が分割されておらず、1つのネットワークで音声データを文字データに直接変換する構成であるため、高度な属人的スキルも必要としないメリットがある。
【0003】
音声認識結果は必ずしも発話どおりに変換されるものではないため、音声認識結果を補正する技術が知られている(例えば特許文献1参照)。特許文献1には、ユーザーが発話した音声データを認識した結果を、発話内容が分類されたカテゴリに対応するカテゴリ辞書に基づいて修正する技術が開示されている。
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら、従来の技術では、音声認識の精度を向上させるために時間およびコストがかかってしまう。
【0005】
本発明は、上記課題に鑑み、音声認識の精度向上に係る時間およびコストを低減させることを目的とする。
【課題を解決するための手段】
【0006】
上記課題に鑑み、本発明は、端末装置とネットワークを介して通信可能な情報処理システムであって、1人以上のユーザーにより発話された音声データの音声認識結果を取得する音声認識結果取得部と、前記音声認識結果と、前記1人以上のユーザーに関連付けられた固有語彙と、を自然言語処理のモデルである大規模言語モデルに送信し、前記大規模言語モデルが該固有語彙に基づいて前記音声認識結果を修正した修正後の音声認識結果を前記大規模言語モデルから取得する修正部と、取得した前記修正後の音声認識結果を、前記端末装置に対して送信する通信部と、を有する。
【発明の効果】
【0007】
固有語彙を大規模言語モデルに送信して修正後の音声認識結果を得るので、音声認識の精度向上に係る時間およびコストを低減させることができる。
【図面の簡単な説明】
【0008】
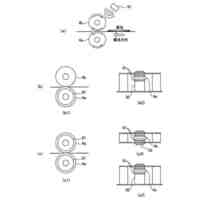
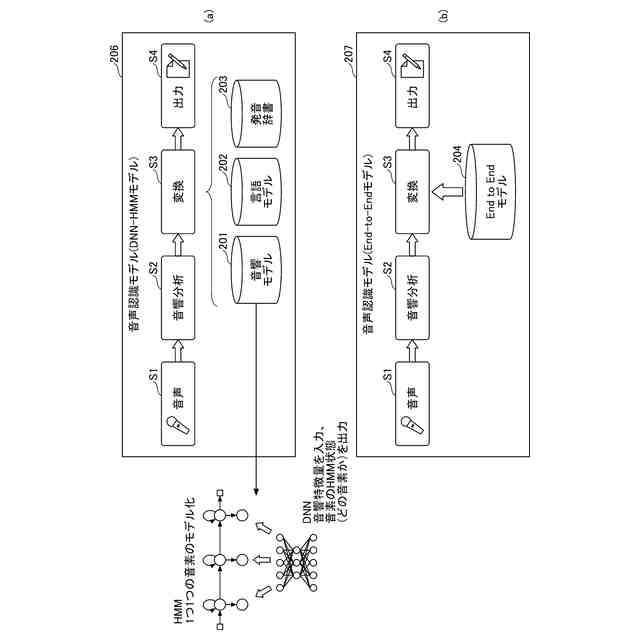
DNN-HMMモデル及びEnd-to-Endモデルを説明する図である。
End-to-Endモデルを固有語彙に対応させる必要性を説明する図である。
End-to-Endモデルの追学習を模式的に説明する図である。
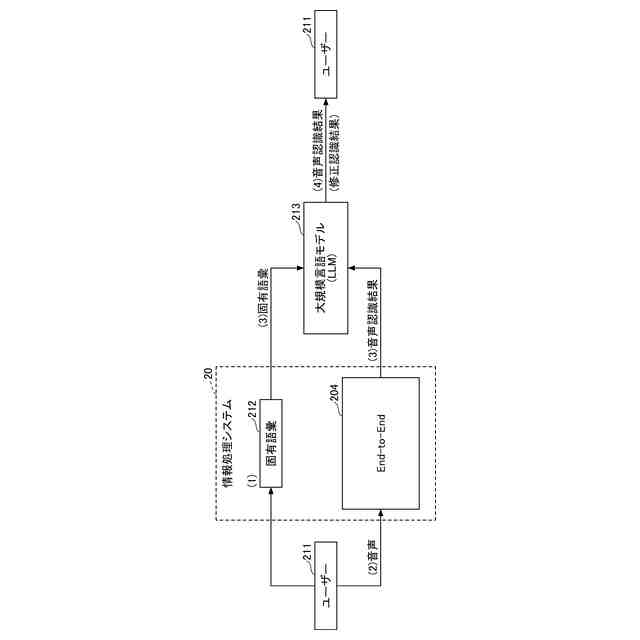
End-to-Endモデルによる音声認識結果を大規模言語モデルがユーザーの語彙で修正する方法を説明する図である。
固有語彙に対応する2つの方法(プロンプトプログラミング、ファインチューニング)を比較して説明する図である。
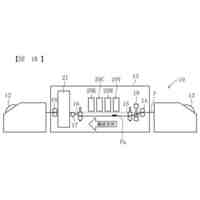
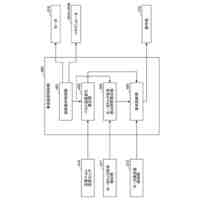
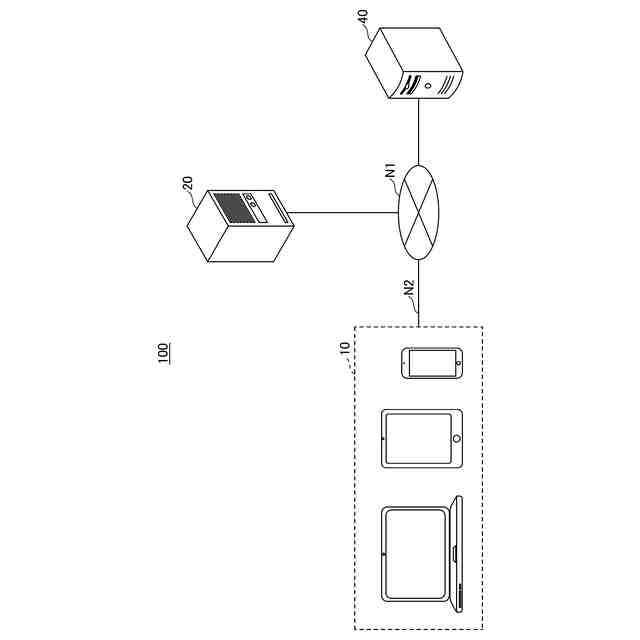
音声認識システムの一例のシステム構成を示す図である。
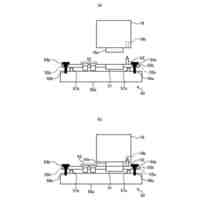
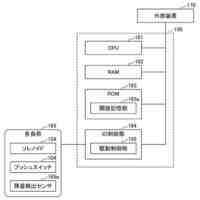
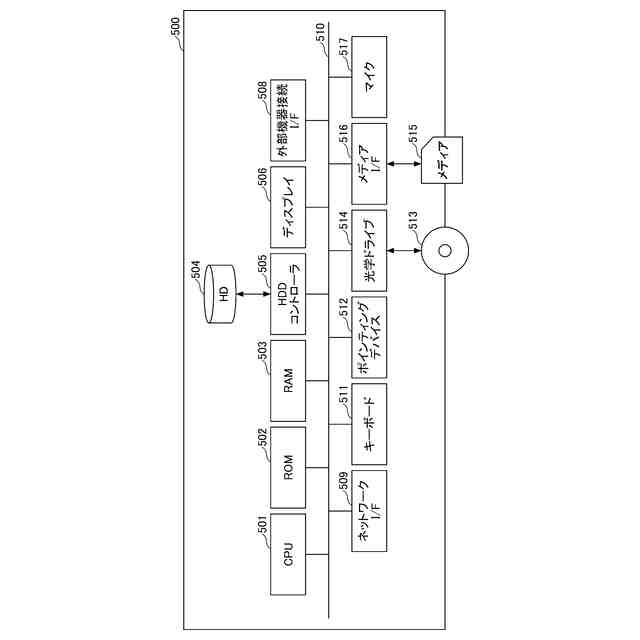
情報処理システム又はユーザー端末の一例のハードウェア構成を示す図である。
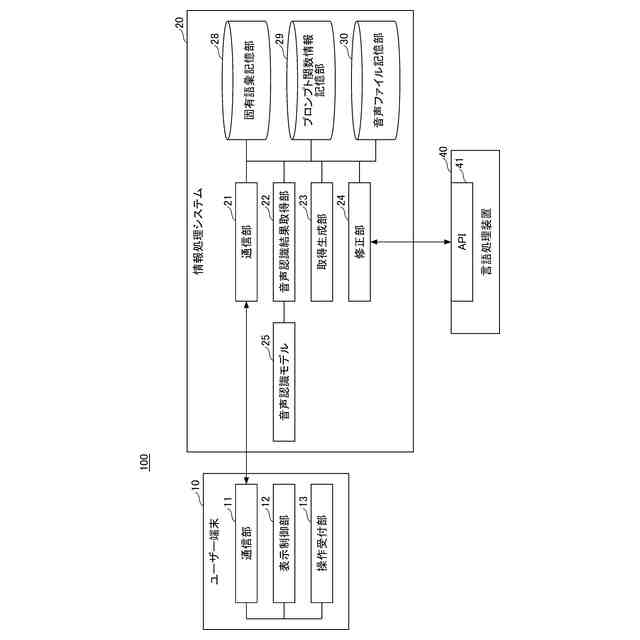
情報処理システム、及びユーザー端末の一例の機能構成を示す図である。
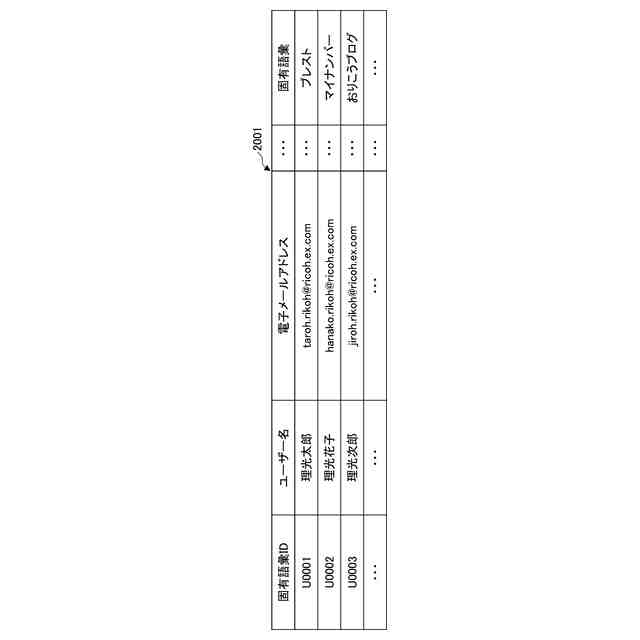
固有語彙記憶部に記憶されている固有語彙管理テーブルの一例を示す概念図である。
大規模言語モデルについて詳細に説明する図である。
音声認識で起こりやすい誤認識の例と、大規模言語モデルによる修正例を説明する図である。
リアルタイム認識と一括認識を対比して説明する図である。
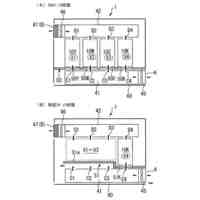
音声認識システムが音声認識した音声認識結果(文字データ)を言語処理装置40が修正する処理を説明するシーケンス図である(一括処理)。
音声認識システムが音声認識した音声認識結果(文字データ)を言語処理装置が修正する処理を説明するフローチャートの一例である。
ユーザーが図22の固有語彙入力画面で登録した固有語彙の一例を示す図である。
情報処理システムが音声認識することで生成した音声認識結果(文字データ)の一例を示す図である。
「check_prompt」関数の一例を示す図である。
「correction_prompt」関数の一例を示す図である。
言語処理装置に送信されるcheck_promptの一例を示す図である。
「correction_prompt」関数により生成されるcorrection_promptプロンプトの一例を示す図である。
correction_promptに対して言語処理装置が返した応答メッセージの一例を示す図である。
ユーザー端末が表示する固有語彙入力画面の一例を示す図である。
ユーザー端末が音声認識結果(文字データ)を表示する音声認識画面の一例を示す図である。
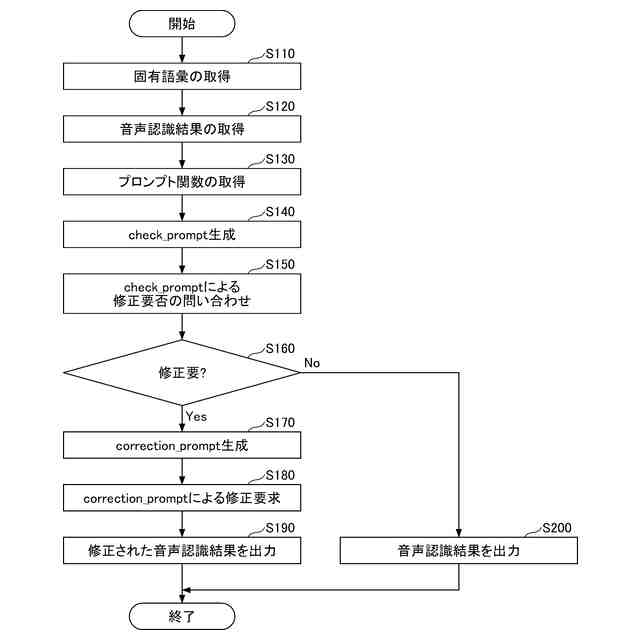
音声認識と音声認識結果(文字データ)の修正の流れを説明するフローチャートの一例である。
音声認識システムが音声認識した音声認識結果(文字データ)を言語処理装置が修正する処理を説明するシーケンス図の一例である(リアルタイム認識)。
ユーザー端末が音声認識結果(文字データ)を表示する音声認識画面の一例を示す図である。
【発明を実施するための形態】
【0009】
以下、本発明を実施するための形態の一例として音声認識システムと、音声認識システムが行う情報処理方法について図面を参照しながら説明する。
【0010】
<音声認識モデル>
まず、図1を参照して、音声認識モデルについて説明する。図1(a)はDNN-HMMモデルを採用した音声認識モデル206における音声認識の流れを示し、図1(b)はEnd-to-Endモデルを採用した音声認識モデル207の認識の流れを示す。なお、以下に示す各ステップ番号(S1,S2,S3,S4)で示される処理は、図1(a)、(b)の各ステップ番号にそれぞれ対応する処理である。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
株式会社リコー
綴じ装置
27日前
株式会社リコー
画像形成装置
19日前
株式会社リコー
液体塗布装置
4日前
株式会社リコー
画像形成装置
今日
株式会社リコー
画像形成装置
今日
株式会社リコー
映像表示装置
21日前
株式会社リコー
印刷システム
今日
株式会社リコー
画像形成装置
18日前
株式会社リコー
画像形成装置
27日前
株式会社リコー
履帯式走行体
28日前
株式会社リコー
画像形成装置
今日
株式会社リコー
画像形成装置
11日前
株式会社リコー
画像形成装置
3日前
株式会社リコー
拡張アンテナ装置
3日前
株式会社リコー
投薬管理システム
19日前
株式会社リコー
画像投射システム
11日前
株式会社リコー
情報処理システム
21日前
株式会社リコー
印刷応答補償機構
4日前
株式会社リコー
マーキングシステム
3日前
株式会社リコー
電極及びその製造方法
今日
株式会社リコー
測定装置および測定方法
20日前
株式会社リコー
測定装置および測定方法
20日前
株式会社リコー
測定装置および測定方法
20日前
株式会社リコー
多孔質構造体の製造方法
今日
株式会社リコー
定着装置及び画像形成装置
10日前
株式会社リコー
定着装置及び画像形成装置
4日前
株式会社リコー
液体塗布装置および洗浄方法
今日
株式会社リコー
塗装システム、及び塗装方法
今日
株式会社リコー
ファイル分析・保存システム
今日
株式会社リコー
測定装置および状態測定方法
20日前
株式会社リコー
液吐出装置、及び液吐出方法
4日前
株式会社リコー
樹脂粒子およびその製造方法
19日前
株式会社リコー
センサ素子及びセンサアレイ
10日前
株式会社リコー
センサ素子及びセンサアレイ
10日前
株式会社リコー
パルスバルブおよび塗布装置
今日
株式会社リコー
画像形成装置及び画像形成方法
19日前
続きを見る
他の特許を見る
 特許ウォッチ
特許ウォッチ