TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025152621
公報種別
公開特許公報(A)
公開日
2025-10-10
出願番号
2024054598
出願日
2024-03-28
発明の名称
訓練データ生成プログラム、機械学習プログラム、推定プログラム、方法、及び装置
出願人
富士通株式会社
代理人
弁理士法人太陽国際特許事務所
主分類
G06N
20/00 20190101AFI20251002BHJP(計算;計数)
要約
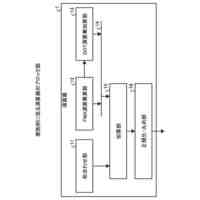
【課題】機械学習モデルの推定精度及び説明性を向上させることができる訓練データを効率的に生成する。
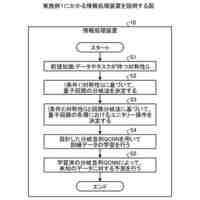
【解決手段】情報処理装置は、教師ラベルが付与された複数の文章の各々に含まれる単語の組み合わせから、単語の組み合わせと教師ラベルとの関連性を示す指標値が所定の条件を満たす単語の組み合わせを抽出し、抽出した単語の組み合わせが複数の文章の各々において、同じ文脈に含まれるか否かを判定し、同じ文脈に含まれると判定された単語の組み合わせの、複数の文章の各々における有無を特徴量として、教師ラベルと対応付けた訓練データを生成する。
【選択図】図4
特許請求の範囲
【請求項1】
教師ラベルが付与された複数の文章の各々に含まれる単語の組み合わせから、前記単語の組み合わせと前記教師ラベルとの関連性を示す指標値が所定の条件を満たす前記単語の組み合わせを抽出し、
抽出した前記単語の組み合わせが前記複数の文章の各々において、同じ文脈に含まれるか否かを判定し、
前記同じ文脈に含まれると判定された前記単語の組み合わせの、前記複数の文章の各々における有無を特徴量として、前記教師ラベルと対応付けた訓練データを生成する
ことを含む処理をコンピュータに実行させるための訓練データ生成プログラム。
続きを表示(約 1,500 文字)
【請求項2】
前記指標値は、前記教師ラベルの正例と負例とにおける前記単語の組み合わせの出現率の異なりの有意性を示す指標値である請求項1に記載の訓練データ生成プログラム。
【請求項3】
前記指標値は、カイ二乗値、正規化相互情報量、重み、信頼度、及び支持度の少なくとも1つを含む請求項2に記載の訓練データ生成プログラム。
【請求項4】
前記単語の組み合わせを抽出する処理は、前記単語の組み合わせについての前記指標値と、前記単語の組み合わせに含まれる各単語についての指標値との差分が大きい前記単語の組み合わせほど、抽出する優先度を高くすることを含む請求項1~請求項3のいずれか1項に記載の訓練データ生成プログラム。
【請求項5】
抽出した前記単語の組み合わせが前記同じ文脈に含まれるか否かを、大規模言語モデルを用いて判定する請求項1~請求項3のいずれか1項に記載の訓練データ生成プログラム。
【請求項6】
請求項1~請求項3のいずれか1項に記載の訓練データ生成プログラムにより生成された訓練データを用いて、推定対象の文章についての特徴量データが入力された場合に、タスクに応じた推定結果を出力する機械学習モデルを訓練することを含む処理をコンピュータに実行させるための機械学習プログラム。
【請求項7】
前記訓練データの特徴量として含まれる単語の組み合わせが、前記推定対象の文章において、同じ文脈に含まれるか否かを判定し、
同じ文脈に含まれると判定された前記単語の組み合わせの、前記推定対象の文章における有無を特徴量として含む特徴量データを生成し、
請求項6の機械学習プログラムにより訓練された前記機械学習モデルに前記特徴量データを入力して得られる前記タスクに関する前記推定結果を出力する
ことを含む処理をコンピュータに実行させるための推定プログラム。
【請求項8】
教師ラベルが付与された複数の文章の各々に含まれる単語の組み合わせから、前記単語の組み合わせと前記教師ラベルとの関連性を示す指標値が所定の条件を満たす前記単語の組み合わせを抽出し、
抽出した前記単語の組み合わせが前記複数の文章の各々において、同じ文脈に含まれるか否かを判定し、
前記同じ文脈に含まれると判定された前記単語の組み合わせの、前記複数の文章の各々における有無を特徴量として、前記教師ラベルと対応付けた訓練データを生成する
ことを含む処理をコンピュータが実行する訓練データ生成方法。
【請求項9】
請求項8に記載の訓練データ生成方法により生成された訓練データを用いて、推定対象の文章についての特徴量データが入力された場合に、タスクに応じた推定結果を出力する機械学習モデルを訓練することを含む処理をコンピュータが実行する機械学習方法。
【請求項10】
前記訓練データの特徴量として含まれる単語の組み合わせが、前記推定対象の文章において、同じ文脈に含まれるか否かを判定し、
同じ文脈に含まれると判定された前記単語の組み合わせの、前記推定対象の文章における有無を特徴量として含む特徴量データを生成し、
請求項9の機械学習方法により訓練された前記機械学習モデルに前記特徴量データを入力して得られる前記タスクに関する前記推定結果を出力する
ことを含む処理をコンピュータが実行する推定方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
開示の技術は、訓練データ生成プログラム、訓練データ生成方法、訓練データ生成装置、機械学習プログラム、機械学習方法、機械学習装置、推定プログラム、推定方法、及び推定装置に関する。
続きを表示(約 2,100 文字)
【背景技術】
【0002】
従来、例えば、プロジェクトに関する様々な数値データや、進捗状況を示す文章を品質保証の担当者が見て、プロジェクトの採算が悪化しているか否か等を予測又は判断し、プロジェクトの進捗等を是正することが行われている。また、プロジェクトに関する文章に特定の単語が存在するか否かをその文章の特徴量とし、機械学習モデルにより採算悪化を予測するシステムも存在する。この場合、機械学習モデルとして説明可能AI(Artificial Intelligence)を使用することで、採算が悪化しているプロジェクトの要因を分析するシステムも存在する。特定の単語は、事前に指定したり、自動で取得したりする。
【0003】
文章に含まれる単語を特徴量とする機械学習に関する技術として、例えば、既存のシソーラスを正解として用いて、多クラスの教師あり学習を行うことにより、テキストデータからの単語意味関係抽出を行う単語意味関係抽出装置が提案されている。この装置は、テキスト中の任意の単語ペアについて、複数種類の類似度を計算し、各類似度を要素とする素性ベクトルを生成する。また、この装置は、各単語ペアにシソーラスに基づいて単語意味関係の種別を示すラベルを付与する。そして、この装置は、素性ベクトルとラベルから単語意味関係識別用データを多クラスの識別問題として学習し、その単語意味関係識別用データによって2つの単語の単語間意味関係の識別を行う。
【0004】
また、例えば、自然言語からなる入力文に含まれる単語から、この単語の組み合わせに対する特徴量を抽出し、その特徴量に基づいて単語の上位概念を示す上位意味クラスを決定する単語意味付与装置特が提案されている。
【0005】
また、例えば、単語の複数のグループを含むラベル付きトレーニングデータを1つ以上のプロセッサを有するサーバで受信する方法が提案されている。また、この方法では、単語の各グループは述語を有し、各単語は一般的な単語の埋込み内容を有し、それらの述語の構文的文脈内の単語の複数のグループをサーバで抽出する。また、この方法は、一般的な単語の埋込み内容をサーバで連結することにより各単語の特徴を表す高次元ベクトル空間を作成する。また、この方法は、高次元ベクトル空間から低次元ベクトル空間への学習されたマッピング及び低次元ベクトル空間内の各可能なセマンティックフレームの学習された埋込み内容を有するモデルをサーバで取得する。そして、この方法は、保存するモデルをサーバによって出力し、モデルは入力に対する特定のセマンティックフレームを識別するように構成される。
【0006】
また、例えば、自動的テキスト解析、及びコ-パスに表れる単語を含む文脈の順位付けの方法が提案されている。この方法は、それぞれ出現頻度で、各単語について文脈に局所順位を付け、文脈について大域的順位を付け、文脈の単語に関する類似性を得るために対数順位比統計などの統計量を計算し、これに基づき文脈を順序付けする。
【先行技術文献】
【特許文献】
【0007】
国際公開第2014/033799号
特開2009-181408号公報
米国特許出願公開第2016/0239739号明細書
米国特許出願公開第2005/0049867号明細書
【発明の概要】
【発明が解決しようとする課題】
【0008】
しかし、文章に特定の単語が存在するか否かをその文章の特徴量とする場合のように、単語1つ1つを特徴量とするだけでは、機械学習モデルによる推定精度が向上しない場合や、説明性が低い推定結果となる場合が多い。これは、例えば、採算悪化を示す単語として、「遅延」を特定の単語として指定したとしても、「遅延」が「発生」したのか「解消」したのかを判別することが困難なためである。
【0009】
そこで、複数の単語の組み合わせが文章内に同時に出現するか否かを特徴量とすることが考えられる。しかし、関係のない文章からそれぞれ抽出された単語の組み合わせは、機械学習モデルの推定精度や説明性の向上に寄与しないため、訓練データに用いる特徴量からは除外することが望ましい。すなわち、同じ文脈内に出現する単語の組み合わせを特徴量として使うことが望ましい。
【0010】
しかし、単語の組み合わせが同じ文脈に含まれるか否かを判定することは容易ではない。例えば、文章を句点で1文毎に区切り、1文内に単語の組み合わせが出現する場合には、その単語の組み合わせは同じ文脈に含まれると判定することも考えられる。ただし、単語の組み合わせに含まれる各単語が、複数の文にまたがって出現しても、同じ文脈で使われている場合もあるため、この判定方法では十分ではない。また、全単語の組み合わせについて、同じ文脈に含まれるか否かを判定することは、処理時間の面からも現実的ではない。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
富士通株式会社
半導体装置
8日前
富士通株式会社
行列演算回路
18日前
富士通株式会社
周波数変換器
21日前
富士通株式会社
メッシュ微細化
9日前
富士通株式会社
半導体デバイス
8日前
富士通株式会社
演算器及び演算方法
9日前
富士通株式会社
ポイントクラウド分類
3日前
富士通株式会社
冷却装置及び電子機器
18日前
富士通株式会社
アレイアンテナモジュール
10日前
富士通株式会社
電子機器筐体及び電子機器
7日前
富士通株式会社
光送信器及び光トランシーバ
7日前
富士通株式会社
基板及びこれを備えた電子装置
10日前
富士通株式会社
演算処理装置及び演算処理方法
29日前
富士通株式会社
通信制御装置及び移動中継装置
15日前
富士通株式会社
テキスト案内される画像エディタ
3日前
富士通株式会社
動的多次元メディアコンテンツ投影
28日前
富士通株式会社
メモリ管理装置及びメモリ管理方法
2日前
富士通株式会社
異常予測方法および異常予測プログラム
28日前
富士通株式会社
管理装置、管理方法、および管理プログラム
16日前
富士通株式会社
演算システムおよび演算システムの制御方法
1か月前
富士通株式会社
生成人工知能を使用したデータセット符号化
1か月前
富士通株式会社
交通シミュレーションのための方法および装置
28日前
富士通株式会社
予測プログラム、予測方法および情報処理装置
1か月前
富士通株式会社
シストリック型の演算アレイ装置及び制御方法
1か月前
富士通株式会社
生成プログラム、生成方法および情報処理装置
1日前
富士通株式会社
プログラム、情報処理方法および情報処理装置
14日前
富士通株式会社
出張情報受付方法および出張情報受付プログラム
7日前
富士通株式会社
演算装置、情報処理装置及び演算装置の制御方法
1か月前
富士通株式会社
プログラム、データ処理装置及びデータ処理方法
8日前
富士通株式会社
探索プログラム、探索方法、および情報処理装置
7日前
富士通株式会社
制御プログラム、制御方法、および情報処理装置
16日前
富士通株式会社
キャッシュ装置およびキャッシュ装置の制御方法
8日前
富士通株式会社
プログラム、データ処理方法およびデータ処理装置
1日前
富士通株式会社
並列コンピューティング・カテゴリー分けプロセス
3日前
富士通株式会社
レース内容再現方法およびレース内容再現プログラム
1か月前
富士通株式会社
情報処理プログラム、情報処理装置及び情報処理方法
1か月前
続きを見る
他の特許を見る










 特許ウォッチ
特許ウォッチ