TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025115376
公報種別
公開特許公報(A)
公開日
2025-08-06
出願番号
2024228579
出願日
2024-12-25
発明の名称
データ拡張方法、データ拡張装置及びコンピュータプログラム製品
出願人
株式会社NTTドコモ
代理人
インフォート弁理士法人
主分類
G06N
3/045 20230101AFI20250730BHJP(計算;計数)
要約
【課題】データ生成条件を、人手による定義やラベル付けを行うことなく自動的に生成し、自動的に生成されたデータ生成条件に基づいて、入力データから出力データを生成することで、データの拡張を可能にする。
【解決手段】データ拡張方法が、所定の分布曲線に対してサンプリングして、サンプリング点を取得するステップと、可逆的な変換を実施可能な第1のニューラルネットワークモデルは、サンプリング点に基づいて、第1の条件特徴ベクトルを生成するステップと、第2のニューラルネットワークモデルは、入力データと第1の条件特徴ベクトルとを入力として拡張データを生成するステップと、を含む。
【効果】煩雑さが削減され、データの多様性が向上する。
【選択図】図2
特許請求の範囲
【請求項1】
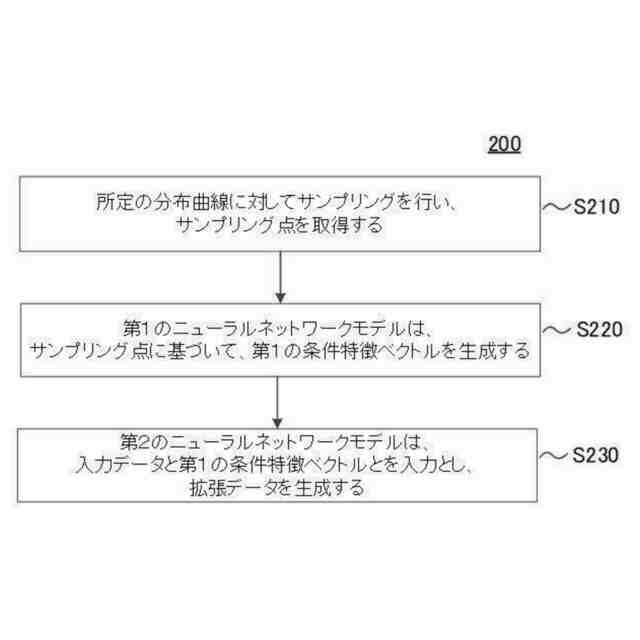
所定の分布曲線に対してサンプリングを行い、サンプリング点を取得するステップと、
可逆的な変換を実施可能な第1のニューラルネットワークモデルが、前記サンプリング点に基づいて、第1の条件特徴ベクトルを生成するステップと、
第2のニューラルネットワークモデルが、入力データと前記第1の条件特徴ベクトルとを入力とし、拡張データを生成するステップと、を含む、データ拡張方法。
続きを表示(約 980 文字)
【請求項2】
前記第2のニューラルネットワークモデルは、
第3のニューラルネットワークモデルが第1のデータと第2のデータとに基づいて第2の条件特徴ベクトルを生成する場合、前記第2のニューラルネットワークモデルが前記第1のデータと前記第2の条件特徴ベクトルとに基づいて前記第2のデータを生成できるようにトレーニングされる、請求項1に記載のデータ拡張方法。
【請求項3】
前記第1のニューラルネットワークモデルは、
第3のニューラルネットワークモデルが第1のデータと第2のデータとに基づいて第2の条件特徴ベクトルを生成する場合、前記第1のニューラルネットワークモデルが前記第2の条件特徴ベクトルを所定の分布曲線にマッピングできるようにトレーニングされる、請求項1に記載のデータ拡張方法。
【請求項4】
前記第1の条件特徴ベクトル又は前記第2の条件特徴ベクトルは、データのオフセットのタイプを示す、請求項1から3のいずれか一項に記載のデータ拡張方法。
【請求項5】
前記所定の分布曲線は、ガウス分布曲線である、請求項1から3のいずれか一項に記載のデータ拡張方法。
【請求項6】
前記第1のニューラルネットワークモデルは、1つ又は複数のカップリング層モデルを含む、請求項1から3のいずれか一項に記載のデータ拡張方法。
【請求項7】
前記入力データは、テキストデータであり、
前記拡張データは、前記テキストデータからオフセットされたオフセットテキストデータである、請求項1から3のいずれか一項に記載のデータ拡張方法。
【請求項8】
前記入力データは、画像データであり、
前記拡張データは、前記画像データからオフセットされたオフセット画像データである、請求項1から3のいずれか一項に記載のデータ拡張方法。
【請求項9】
前記第2のニューラルネットワークモデルは、自己回帰モデルを含む、請求項1から3のいずれか一項に記載のデータ拡張方法。
【請求項10】
前記第3のニューラルネットワークモデルは、特徴抽出器を含む、請求項2から3のいずれか一項に記載のデータ拡張方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本発明は、データ処理に関し、より具体的には、データ拡張方法、データ拡張装置及びコンピュータプログラム製品に関する。
続きを表示(約 1,300 文字)
【背景技術】
【0002】
現在、ディープラーニングモデル(Deep Learning Model)は多くの分野で成果を上げているが、ディープラーニングモデルのトレーニングは大量のラベル付きデータに依存し、ラベル付きデータの不足やデータの分布の不均衡によりディープラーニングモデルの性能低下の問題が発生してしまうことが多い。データ拡張(Data Augmentation)は、トレーニングデータを自動的に拡張する技術であり、ラベル付きデータを取得する際のコストを削減することで、ディープラーニングモデルの性能を向上させることができる。
【発明の概要】
【課題を解決するための手段】
【0003】
本開示は、データ生成条件を自動的に生成し、自動的に生成されたデータ生成条件に基づいて入力データから出力データを生成できるようにすることで、人間が大きく関与することなくデータの拡張を可能にする、データ拡張方法、データ拡張装置、コンピュータプログラム製品、及び非一時的なコンピュータ読み取り可能な記憶媒体に関する。
【0004】
本開示の一態様によれば、データ拡張方法が提供される。当該方法は、所定の分布曲線に対してサンプリングを行い、サンプリング点を取得するステップと、可逆的な変換を実施可能な第1のニューラルネットワークモデルが、サンプリング点に基づいて、第1の条件特徴ベクトルを生成するステップと、第2のニューラルネットワークモデルが、入力データと第1の条件特徴ベクトルとを入力とし、拡張データを生成するステップと、を含む。
【0005】
本開示の一実施例によれば、第2のニューラルネットワークモデルは、第3のニューラルネットワークモデルが第1のデータと第2のデータとに基づいて、第2の条件特徴ベクトルを生成する場合、第1のデータと第2の条件特徴ベクトルとから第2のデータを生成できるようにトレーニングされる。
【0006】
本開示の一実施例によれば、第1のニューラルネットワークモデルは、第3のニューラルネットワークモデルが第1のデータと第2のデータとに基づいて第2の条件特徴ベクトルを生成する場合、第1のニューラルネットワークモデルが第2の条件特徴ベクトルを所定の分布曲線にマッピングできるようにトレーニングされる。
【0007】
本開示の一実施例によれば、第1の条件特徴ベクトル又は第2の条件特徴ベクトルは、データのオフセットのタイプを示す。
【0008】
本開示の一実施例によれば、所定の分布曲線は、ガウス分布曲線である。
【0009】
本開示の一実施例によれば、第1のニューラルネットワークモデルは、1つ又は複数のカップリング層モデル(Coupling Layer Model)を含む。
【0010】
本開示の一実施例によれば、入力データは、テキストデータであり、拡張データは、テキストデータからオフセットされたオフセットテキストデータである。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
株式会社NTTドコモ
制御装置および制御方法
3日前
株式会社NTTドコモ
情報処理装置及び情報処理方法
13日前
株式会社NTTドコモ
情報処理装置および情報処理方法
18日前
株式会社NTTドコモ
真実性評価装置及び真実性評価方法
16日前
株式会社NTTドコモ
道路状態評価装置及び道路状態評価方法
11日前
株式会社NTTドコモ
モード変換器、モード変換構造、伝送線路
3日前
株式会社NTTドコモ
無線通信装置、逆特性計算方法、およびプログラム
2日前
株式会社NTTドコモ
端末
5日前
株式会社NTTドコモ
送信システム、受信システム、チャネル合成システム
17日前
株式会社NTTドコモ
通信装置
5日前
株式会社NTTドコモ
データ拡張方法、データ拡張装置及びコンピュータプログラム製品
4日前
株式会社NTTドコモ
データ処理方法、データ処理装置及びコンピュータプログラム製品
4日前
株式会社NTTドコモ
端末及び通信方法
5日前
株式会社NTTドコモ
端末、通信方法及び通信システム
5日前
株式会社NTTドコモ
端末、基地局、通信システム及び通信方法
5日前
株式会社NTTドコモ
無線通信ネットワークにおけるネットワーク側機器によって実行される方法及びネットワーク側機器
24日前
AGC株式会社
アンテナユニット、およびアンテナユニットの製造方法
16日前
個人
対話装置
1か月前
個人
裁判のAI化
24日前
個人
情報処理装置
1か月前
個人
フラワーコートA
3日前
個人
情報処理システム
1か月前
個人
検査システム
1か月前
個人
情報処理装置
1か月前
個人
記入設定プラグイン
1か月前
個人
介護情報提供システム
10日前
個人
設計支援システム
16日前
個人
設計支援システム
16日前
個人
不動産売買システム
1か月前
個人
情報入力装置
1か月前
株式会社サタケ
籾摺・調製設備
1か月前
キヤノン電子株式会社
携帯装置
1か月前
個人
物価スライド機能付生命保険
1か月前
株式会社カクシン
支援装置
19日前
個人
アンケート支援システム
5日前
個人
備蓄品の管理方法
1か月前
続きを見る
他の特許を見る



 特許ウォッチ
特許ウォッチ