TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025140985
公報種別
公開特許公報(A)
公開日
2025-09-29
出願番号
2024040664
出願日
2024-03-15
発明の名称
システム及びマイグレーション方法
出願人
日本電気株式会社
代理人
個人
,
個人
主分類
G06F
9/50 20060101AFI20250919BHJP(計算;計数)
要約
【課題】仮想マシンとGPUを連動してマイグレーションする技術を提供する。
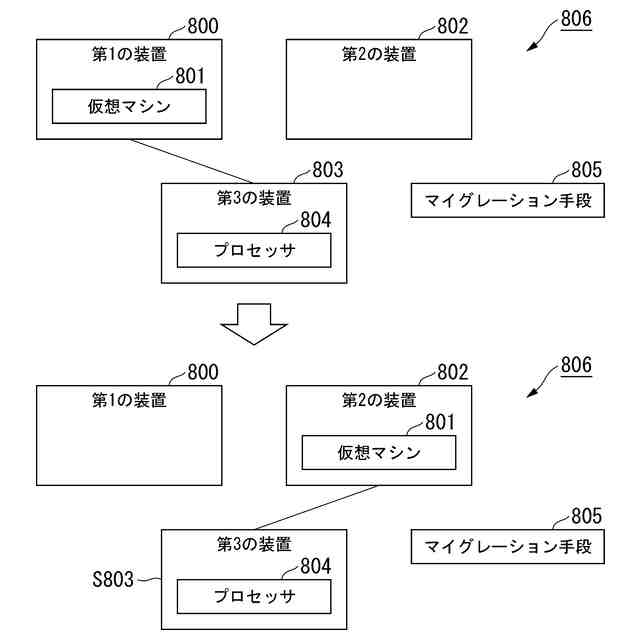
【解決手段】システムは、仮想マシンが稼働する第1の装置と、前記仮想マシンのマイグレーション先となる第2の装置と、前記第1の装置と接続し、前記仮想マシンに割り当てられたプロセッサを搭載する第3の装置と、前記第1の装置から第2の装置に前記仮想マシンをマイグレーションする手段と、を備え、前記マイグレーションする手段は、前記仮想マシンを前記第1の装置から前記第2の装置にマイグレーションする際に、前記第3の装置を前記第1の装置から切り離して、前記第2の装置に接続し、前記第2の装置にマイグレーションされた前記仮想マシンに前記プロセッサを割り当てて起動する。
【選択図】図10
特許請求の範囲
【請求項1】
仮想マシンが稼働する第1の装置と、
前記仮想マシンのマイグレーション先となる第2の装置と、
前記第1の装置と接続し、前記仮想マシンに割り当てられたプロセッサを搭載する第3の装置と、
前記第1の装置から前記第2の装置に前記仮想マシンをマイグレーションする手段と、
を備え、
前記マイグレーションする手段は、前記仮想マシンを前記第1の装置から前記第2の装置にマイグレーションする際に、前記第3の装置の接続先を前記第1の装置から前記第2の装置に切り替え、前記第2の装置にマイグレーションした前記仮想マシンに前記プロセッサを割り当てて起動する、
システム。
続きを表示(約 2,000 文字)
【請求項2】
前記第1の装置と前記第3の装置はPCIe over Ethernetで接続され、
前記マイグレーションする手段は、前記仮想マシンを前記第1の装置から前記第2の装置にマイグレーションする際に、前記第3の装置と前記第1の装置のPCIe over Ethernetによる接続を切断して、前記第3の装置と前記第2の装置をPCIe over Ethernetで接続する、
請求項1に記載のシステム。
【請求項3】
前記マイグレーションする手段は、
前記第3の装置のPCIe Expander Engineの接続先情報を、前記第1の装置から前記第2の装置へ書き換えることにより、前記第3の装置の接続先を前記第2の装置へ切り替える、
請求項2に記載のシステム。
【請求項4】
前記マイグレーションする手段は、
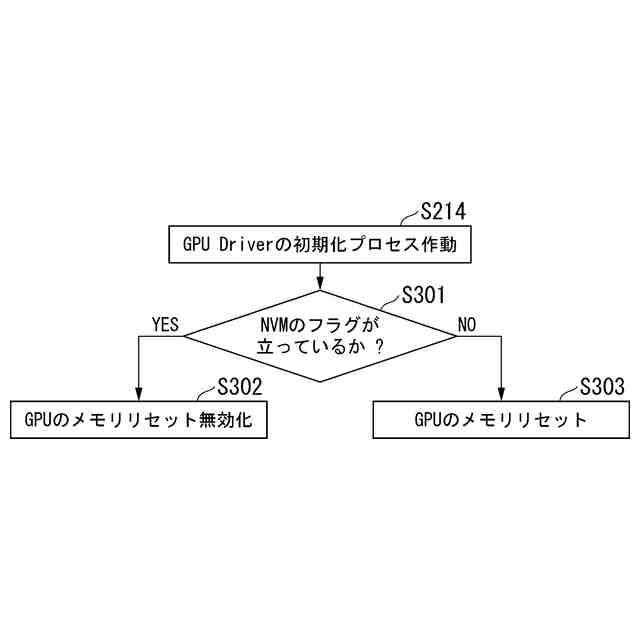
前記第2の装置の前記仮想マシンに前記プロセッサを割り当てて起動する際に、前記プロセッサのメモリのリセットを無効化して起動する
請求項1または請求項2に記載のシステム。
【請求項5】
前記マイグレーションする手段は、
マイグレーション前に前記第1の装置で前記仮想マシンが処理した処理結果の情報を、前記プロセッサのメモリにロードせずに、前記第2の装置で起動した前記仮想マシンに前記処理を実行させる、
請求項4に記載のシステム。
【請求項6】
前記システムは、前記第1の装置と前記第2の装置との両方からアクセス可能な記憶装置をさらに備え、
前記第1の装置の前記仮想マシンでは、LLMの学習処理が実行され、チェックポイントごとに前記学習処理の結果情報が前記記憶装置に記録され、
前記学習処理中に前記第1の装置が使用できない状況となると、前記マイグレーションする手段は、前記記憶装置に記録された前記結果情報を前記プロセッサのメモリにロードすることなく、前記第2の装置で前記学習処理を継続する、
請求項5に記載のシステム。
【請求項7】
前記マイグレーションする手段は、
前記第1の装置のハイパーバイザー、クラスタリングソフトウェアおよび接続手段と、
前記第2の装置のハイパーバイザー、クラスタリングソフトウェアおよび接続手段と、
前記第3の装置の接続手段と、
前記第1の装置の接続手段と前記第2の装置の接続手段と前記第3の装置の接続手段を制御する手段と、を含み、
前記仮想マシンを前記第1の装置から前記第2の装置にマイグレーションする際に、
前記第1の装置のクラスタリングソフトウェアは前記第1の装置のハイパーバイザーに前記仮想マシンの停止を指示するとともに、前記制御する手段に前記プロセッサの接続先の切り替えを指示し、
前記制御する手段は前記第3の装置の接続先を前記第1の装置から前記第2の装置に切り替えるとともに、前記プロセッサがマイグレーションの対象であることを示すフラグを前記第3の装置の接続手段に記録して、前記第2の装置のクラスタリングソフトウェアに前記プロセッサを前記仮想マシンへ割り当てることを指示し、
前記第2の装置のクラスタリングソフトウェアは前記プロセッサを前記仮想マシンに割り当てて、
前記第2の装置のハイパーバイザーが前記仮想マシンを起動し、
前記仮想マシンの起動時に、前記第2の装置の前記ハイパーバイザーは、前記第3の装置の接続手段を通じて前記プロセッサにアクセスする際に前記フラグの有無を確認し、フラグがあった場合、前記プロセッサのメモリのリセットを行わない、
請求項1に記載のシステム。
【請求項8】
前記マイグレーションする手段は、
前記第1の装置から前記第2の装置に前記仮想マシンと前記第3の装置に搭載された前記プロセッサ以外のIOデバイスをマイグレーションする、
請求項1又は請求項2に記載のシステム。
【請求項9】
前記IOデバイスは、NIC、ストレージ、USBボード、キャプチャボードの何れかである、
請求項8に記載のシステム。
【請求項10】
仮想マシンが稼働する第1の装置と、
前記仮想マシンのマイグレーション先となる第2の装置と、
前記第1の装置と接続し、前記仮想マシンに割り当てられたプロセッサを搭載する第3の装置と、を含むシステムにおいて、
前記仮想マシンを前記第1の装置から前記第2の装置にマイグレーションする際に、前記第3の装置の接続先を前記第1の装置から前記第2の装置に切り替え、前記第2の装置にマイグレーションした前記仮想マシンに前記プロセッサを割り当てて起動する、
マイグレーション方法。
発明の詳細な説明
【技術分野】
【0001】
本開示は、システム及びマイグレーション方法に関する。
続きを表示(約 4,100 文字)
【背景技術】
【0002】
OpenAI(登録商標)によるChatGPT(登録商標)の公開により、10-100Bパラメータの大規模言語モデル(以下、LLM(Large Language Models)と記載)が注目されている。OpenAI(登録商標)のGPT-3(登録商標)は175Bパラメータ、GPT-3.5は355Bパラメータと言われている。大量のパラメータを持つLLMの学習には、多数のGPU(Graphics Processing Unit)を用いて長時間の学習が必要になる。現実的には、学習時間に生じるメンテナンスや障害発生によるダウンタイムも考慮する必要がある。発生する障害には、電源断やディスクの故障等のハードウェア障害、ダウンやストール等のOS(Operating System)障害、ソフトウェア障害が挙げられ、サーバに障害が発生すると復旧するまで学習が中断される。より短時間で学習を完了させるために、システムの安定化と障害復旧時間を短縮する方法が求められている。
【0003】
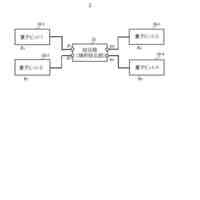
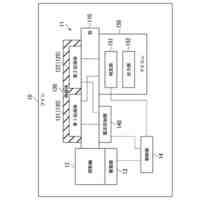
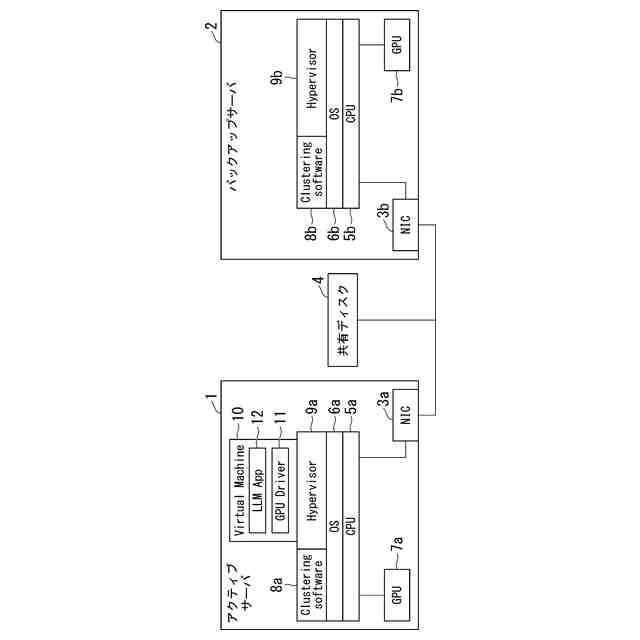
システムを安定化し、復旧時間を短縮する従来技術としてクラスタリングソフトウェアによるVirtual Machine(仮想マシン)のマイグレーションが挙げられる。クラスタリングソフトウェアとは、1台のアクティブサーバ、1台以上のバックアップサーバで構成されるクラスタ構成を制御するソフトウェアである。図1にシステム構成例を示す。図1の例では、アクティブサーバ1とバックアップサーバ2が、Network Interface Card(NICと称する)3a、3bを介して、共有ディスク4に接続されている。アクティブサーバ1には、CPU5aおよびGPU7aが搭載されている。CPU5aでは、OS6aが稼働し、OS6aにはクラスタリングソフトウェア8aと仮想マシンを作成・実行するソフトウェアであるHypervisor(ハイパーバイザー)9aが実装されている。バックアップサーバ2についても同様に、CPU5bおよびGPU7bが搭載され、CPU5bではOS6bが稼働し、OS6bにはクラスタリングソフトウェア8bとHypervisor9bが実装されている。また、アクティブサーバ1にはHypervisor9aにVirtual Machine10が構築されており、Virtual Machine10には、GPU7aの初期化プロセスを実行するGPU Driver11や大規模学習を実行するためのLLMのApplication12が実装されている。
【0004】
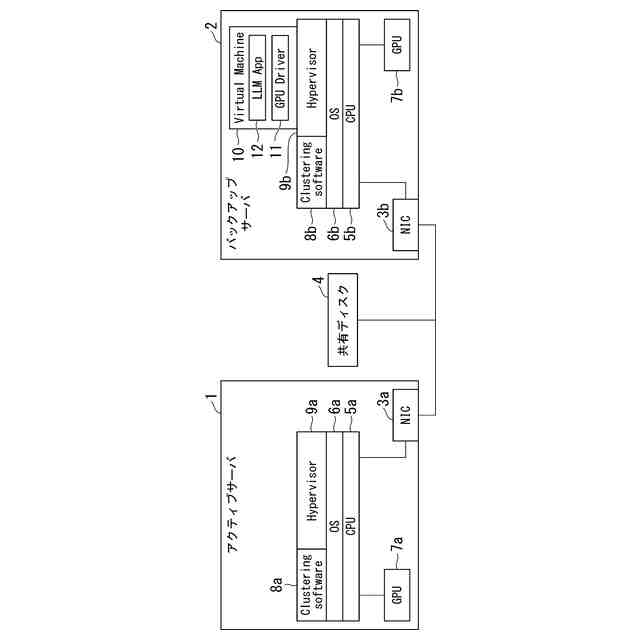
アクティブサーバ1に障害が発生すると、図2に示すようにVirtual Machine10を、共有ディスク4を介してバックアップサーバ2に引き継ぐことができる。その際、バックアップサーバ2に移行したVirtual Machine10の起動時にGPU Driver11による初期化プロセスが実行され、GPU7bのメモリはリセットされることで、アクティブサーバ1で学習した際のGPUデータが消去される。しかし、LLM Application12は共有ディスク4に学習中の途中結果をチェックポイントとしてファイルで保存できるため、バックアップサーバ2でLLM Application12が起動する時に共有ディスク4からチェックポイントファイルを取得し、GPU7bにデータをロードすることで、アクティブサーバ1で学習が中断された場合でも、バックアップサーバ2でチェックポイントから学習を再開できる。しかし、Virtual Machine10のマイグレーションだけでは、アクティブサーバ1とバックアップサーバ2の両方にGPUを用意する必要がある。そのため、バックアップサーバ2に装着されているGPU7bはアクティブサーバ1に障害が発生するまで待機する必要があり、データセンタ内のGPU総数に対するGPUの稼働率が低くなる。さらに、待機中のGPU7bも電力を消費するためコストが増加し、二酸化炭素排出量も増加する。
【0005】
また、Virtual Machine10をバックアップサーバ2への移行した後に起動する際、GPU7bの初期化プロセスが作動し、メモリがリセットされる。そのため、共有ディスク4からアクティブサーバ1での学習時のデータをGPU7bにロードする必要があり、マイグレーションに時間を要する。
【0006】
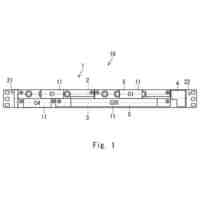
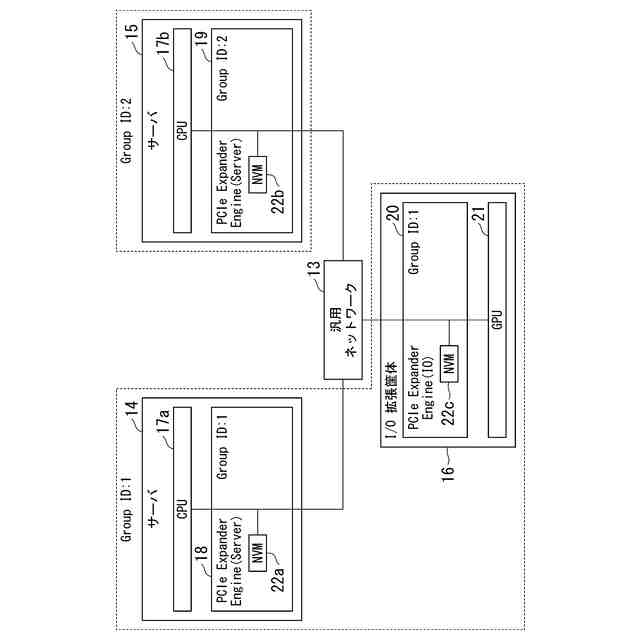
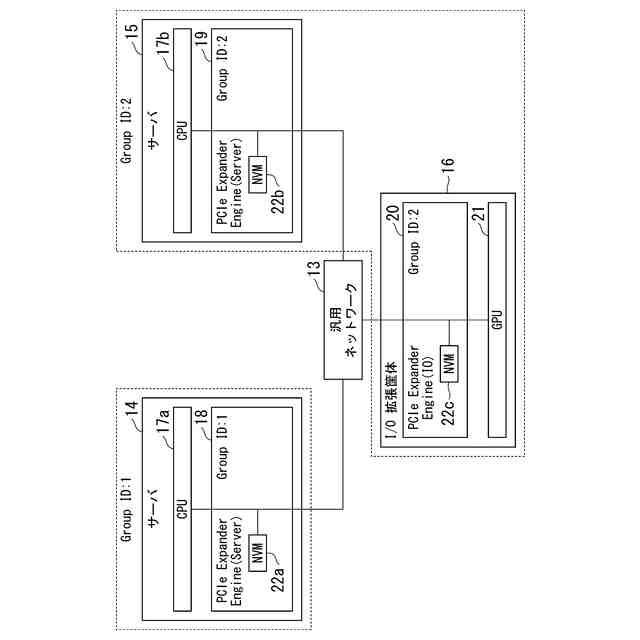
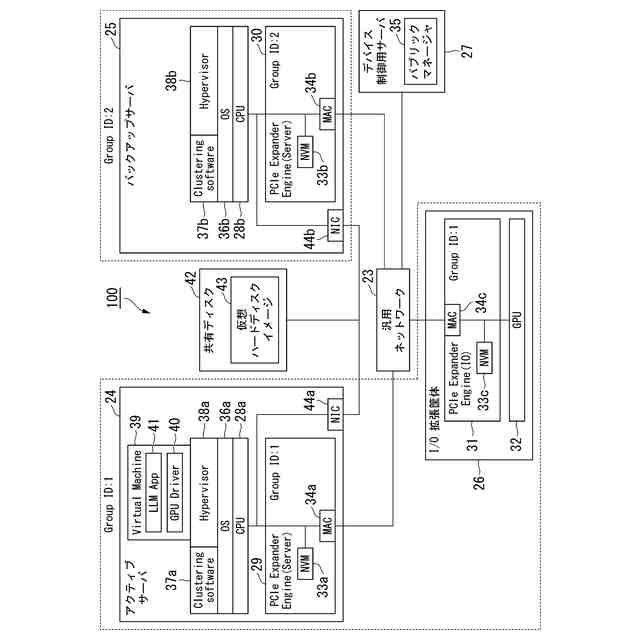
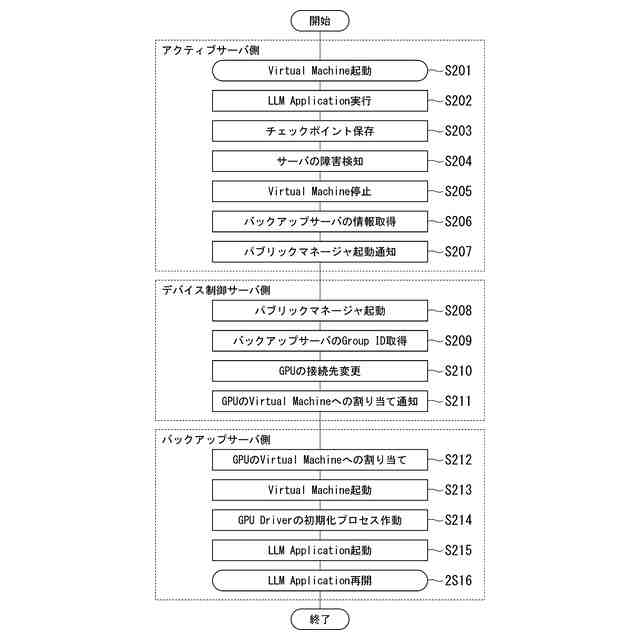
GPUのコストを削減する方法として、MR-IOV(Multi Root I/O Virtualization)によってGPUを搭載したデバイスを共有する方法が挙げられる。MR-IOVは専用のPCIe(Peripheral Component Interconnect Express) Switchを使用し、複数OS間でPCIeデバイスを共有することができる規格である。しかし、専用のPCIe Switchは高価であり、汎用性に欠ける。安価なEthernet Switchを用いて実現可能な方法として、PCIe over Ethernet技術によるGPUのマイグレーションが挙げられる。PCIe over Ethernet技術は、サーバ内部の様々なPCIeデバイスの接続に用いられているPCIeのインターコネクトをEthernetのような汎用ネットワークに拡張することができる技術である。図3にシステム構成例を示す。サーバ14には、CPU17a、PCIe Expander Engine(Server)(以下、EE(Server)と記載)18が搭載され、EE(Server)18はNVM(不揮発メモリ)22aを有している。同様に、サーバ15には、CPU17b、EE(Server)19が搭載され、EE(Server)19はNVM22bを有している。I/O拡張筐体16は、GPU21と、PCIe Expander Engine(IO)(以下、EE(IO)と記載)20が搭載され、EE(IO)20はNVM22cを有している。EE(Server)18、19はサーバ側の機能を持ち、EE(IO)20はI/O側の機能を持つ。サーバ14、15とI/O拡張筐体16は汎用ネットワーク13に接続されている。EE(Server)18、19、EE(IO)20は、汎用ネットワーク13を介して互いに通信を行う。EthernetでPCIeのパケットを転送する場合、PCIeのパケットをEthernetのフレームにカプセル化して転送を行う。NVM22a~22cはGroup IDを保持し、同じGroup IDを保持するEE(Server)とEE(IO)間で接続する。例えば、図3の例では、NVM22aとNVM22cがGroup ID=1を保持し、NVM22bがGroup ID=2を保持するため、EE(Server)18とEE(IO)20が接続される。汎用ネットワーク3にEthernetを使用する場合、VLANの設定を使用し、設定することができる。例えば、EE(IO)20のGroup IDを、稼働中のサーバのEE(server)18のGroup ID=1から移行先のサーバのEE(Server)19のGroup ID=2に変更することで図4に示すように、I/O拡張筐体16の接続先をサーバ14からサーバ15に変更することができる。
【0007】
例えば、サーバ14にて、I/O拡張筐体16のGPU21が割り当てられた仮想マシンが稼働しているとする。その仮想マシンのアプリケーションがLLMの大規模学習を実行しているときにサーバ14に障害が発生したとすると、LLMの大規模学習を継続するためには、Virtual MachineとGPUを連動してマイグレーションする必要がある。サーバ14からサーバ15への仮想マシンのマイグレーションとともに、EE(IO)20のGroup IDを1から2へ変更することにより、GPUのマイグレーションが可能であると考えられる。しかし、クラスタリングソフトウェアによる仮想マシンのマイグレーションはソフトウェア領域、PCIe over Ethernet技術はハードウェア領域で個々に確立されている技術である。領域の離れた技術をシステムとして一体的に機能させるためにはVirtual Machineやデバイスを監視し、連携させる必要がある。より具体的には、LLM等の大規模学習中に発生し得るメンテナンスや障害発生等を見込んだトータルの学習時間を短縮するためには、クラスタリングソフトウェアによるマイグレーションとPCIe over Ethernetで接続されたI/O拡張筐体16の接続先の切り替えを連動させる仕組みが必要である。しかし、このような仕組みは確立されていない。
【0008】
例えば、特許文献1には、ネットワークサービスを提供するシステムにおいて、当該サービスの機能を実現している仮想マシンを別のハードウェアに自動で移行させることにより、ハードウェアの障害発生時やメンテナンス時にもネットワークサービスを継続できるようにするシステムが開示されている。しかし、この技術はクラスタリングソフトウェアによるマイグレーションとネットワークを介して接続されたデバイス(上記例のI/O拡張筐体16)の切り替えを連動させるものではない。
【先行技術文献】
【特許文献】
【0009】
国際公開第2022/172063号
【発明の概要】
【発明が解決しようとする課題】
【0010】
仮想マシンのマイグレーションと、仮想マシンとネットワークを介して接続されているデバイスの接続先をマイグレーション後の仮想マシンへ切り替える処理と、を連動させる方法を提供することを目的の一つとする。
【課題を解決するための手段】
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
日本電気株式会社
分析装置
1日前
日本電気株式会社
マルチバンドバラン
19日前
日本電気株式会社
量子回路装置と制御方法
1日前
日本電気株式会社
量子回路装置と制御方法
1日前
日本電気株式会社
検知装置および検知方法
1日前
日本電気株式会社
端末装置および無線通信方法
12日前
日本電気株式会社
機器冷却装置及びその冷却方法
13日前
日本電気株式会社
プログラム、算出装置、及び方法
13日前
日本電気株式会社
推定装置、推定方法及びプログラム
4日前
日本電気株式会社
推定装置、推定方法及びプログラム
4日前
日本電気株式会社
ピーク抑圧装置及びピーク抑圧方法
11日前
日本電気株式会社
システム及びマイグレーション方法
1日前
日本電気株式会社
処理装置、処理方法、及びプログラム
1日前
日本電気株式会社
通信システム及びパケット順序補正方法
12日前
日本電気株式会社
予測システム、予測方法及びプログラム
4日前
日本電気株式会社
管理システム、管理方法及びプログラム
11日前
日本電気株式会社
情報処理システム、処理方法、プログラム
1日前
日本電気株式会社
映像伝送装置、映像伝送方法、プログラム
1日前
日本電気株式会社
映像処理装置、映像処理方法、プログラム
1日前
日本電気株式会社
処理システム、処理方法およびプログラム
4日前
日本電気株式会社
人数計数装置、人数計数方法及びプログラム
11日前
日本電気株式会社
情報処理装置、情報処理方法及びプログラム
4日前
日本電気株式会社
処理システム、処理方法、およびプログラム
1日前
日本電気株式会社
処理システム、処理方法、およびプログラム
1日前
日本電気株式会社
情報処理装置、情報処理方法、及びプログラム
1日前
日本電気株式会社
ファン、制御方法、通知方法およびプログラム
1日前
日本電気株式会社
情報処理装置、情報処理方法およびプログラム
11日前
日本電気株式会社
情報処理装置、情報処理方法、及びプログラム
11日前
日本電気株式会社
情報処理装置、情報処理方法、及びプログラム
1日前
日本電気株式会社
DMA転送方法、DMA転送装置、プログラム
11日前
日本電気株式会社
情報処理装置、情報処理方法、及びプログラム
1日前
日本電気株式会社
販売促進装置、販売促進方法、及びプログラム
11日前
日本電気株式会社
認証システム、認証装置、方法及びプログラム
1日前
日本電気株式会社
情報処理装置、情報処理方法、及びプログラム
11日前
日本電気株式会社
情報処理装置、情報処理方法、及びプログラム
11日前
日本電気株式会社
情報処理装置、情報処理方法、及びプログラム
11日前
続きを見る
他の特許を見る


 特許ウォッチ
特許ウォッチ