TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025124183
公報種別
公開特許公報(A)
公開日
2025-08-26
出願番号
2024020066
出願日
2024-02-14
発明の名称
データ評価方法、データ評価装置、および、プログラム
出願人
セイコーエプソン株式会社
代理人
個人
,
個人
,
個人
主分類
G06N
20/00 20190101AFI20250819BHJP(計算;計数)
要約
【課題】データの独自性を適切に評価するための技術を提供する。
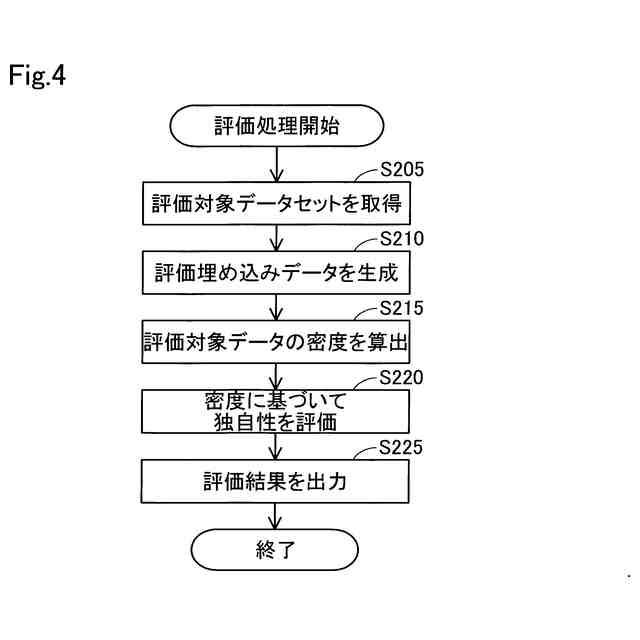
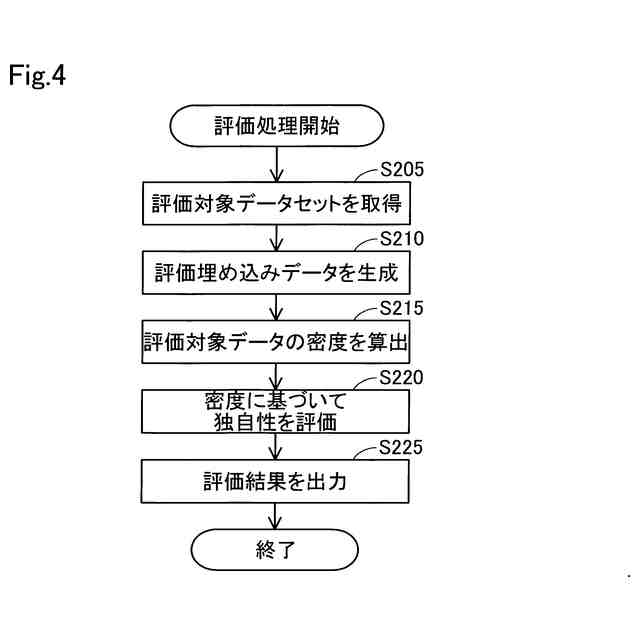
【解決手段】データ評価方法は、入力されるデータを埋め込み空間へ射影するように機械学習させた学習モデルに、評価対象データを入力することで、評価対象データが埋め込み空間へ射影された評価埋め込みデータを生成する生成工程と、評価埋め込みデータと、評価対象データの基準となる複数の基準データが埋め込み空間へ射影された基準埋め込みデータと、を用いて、各基準データが射影された埋め込み空間における評価対象データの密度を算出する算出工程と、密度に基づいて、評価対象データの独自性を評価する評価工程と、を備える。
【選択図】図4
特許請求の範囲
【請求項1】
入力されるデータを埋め込み空間へ射影するように機械学習させた学習モデルに、評価対象データを入力することで、前記評価対象データが前記埋め込み空間へ射影された評価埋め込みデータを生成する生成工程と、
前記評価埋め込みデータと、前記評価対象データの基準となる複数の基準データが前記埋め込み空間へ射影された基準埋め込みデータと、を用いて、各前記基準データが射影された前記埋め込み空間における前記評価対象データの密度を算出する算出工程と、
前記密度に基づいて、前記評価対象データの独自性を評価する評価工程と、を備える、データ評価方法。
続きを表示(約 1,200 文字)
【請求項2】
請求項1に記載のデータ評価方法であって、
前記学習モデルは、自己教師有り学習によって学習済みである、データ評価方法。
【請求項3】
請求項1に記載のデータ評価方法であって、
前記学習モデルは、前記複数の前記基準データの少なくとも一部を用いて学習済みである、データ評価方法。
【請求項4】
請求項1に記載のデータ評価方法であって、
前記学習モデルは、前記複数の前記基準データの全部を用いて学習済みである、データ評価方法。
【請求項5】
請求項1に記載のデータ評価方法であって、
前記生成工程に先立って、前記学習モデルに各前記基準データを入力することで、前記基準埋め込みデータを生成する事前生成工程を備える、データ評価方法。
【請求項6】
請求項1から5のいずれか一項に記載のデータ評価方法であって、
前記評価工程において、前記密度を正規化した結果に基づいて、前記独自性を評価する、データ評価方法。
【請求項7】
請求項6に記載のデータ評価方法であって、
前記評価工程において、正規化された前記密度が予め定められた閾値以上である場合に、前記評価対象データの前記独自性が低いと評価する、データ評価方法。
【請求項8】
入力されるデータの特徴を埋め込み空間へ射影するように機械学習させた学習モデルと、評価対象データの基準となる複数の基準データが前記学習モデルによって前記埋め込み空間へ射影された基準埋め込みデータと、を記憶する記憶部と、
プロセッサーと、を備え、
前記プロセッサーは、
前記評価対象データを取得する処理と、
前記評価対象データを前記学習モデルに入力することで、前記評価対象データが前記埋め込み空間へ射影された評価埋め込みデータを生成する処理と、
前記評価埋め込みデータと、前記基準埋め込みデータと、を用いて、各前記基準データが射影された前記埋め込み空間における前記評価対象データの密度を算出する処理と、
前記密度に基づいて、前記評価対象データの独自性を評価する処理と、を実行する、
データ評価装置。
【請求項9】
入力されるデータの特徴を埋め込み空間へ射影するように機械学習させた学習モデルに、評価対象データを入力することで、前記評価対象データが前記埋め込み空間へ射影された評価埋め込みデータを生成する機能と、
前記評価埋め込みデータと、前記評価対象データの基準となる複数の基準データが前記埋め込み空間へ射影された基準埋め込みデータと、を用いて、各前記基準データが射影された前記埋め込み空間における前記評価対象データの密度を算出する機能と、
前記密度に基づいて、前記評価対象データの独自性を評価する機能と、をコンピューターに実現させる、プログラム。
発明の詳細な説明
【技術分野】
【0001】
本開示は、データ評価方法、データ評価装置、および、プログラムに関する。
続きを表示(約 2,300 文字)
【背景技術】
【0002】
特許文献1には、映像を構成する複数の画像の中から一部の画像を選択する際に、撮影状況が近似している画像ほど選択される可能性を低くする技術が開示されている。
【先行技術文献】
【特許文献】
【0003】
特開2022-161105号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
画像データセットのようなデータセットに関して、データセットに含まれるデータの多様性を制御するニーズが高まっている。例えば、特許文献1の技術では、単に撮影状況が近似している画像ほど選択される可能性が低くなるに留まり、選択された画像の多様性が高いとは限らない。選択された画像の多様性をより高めるためには、似通った画像が少ない独自性の高い画像を抽出することを要する。また、反対に、選択された画像の多様性をより低くするためには、独自性の低い画像を抽出することを要する。そのため、データの独自性を適切に評価する技術が望まれている。
【課題を解決するための手段】
【0005】
本開示の第1の形態によれば、データ評価方法が提供される。このデータ評価方法は、入力されるデータを埋め込み空間へ射影するように機械学習させた学習モデルに、評価対象データを入力することで、前記評価対象データが前記埋め込み空間へ射影された評価埋め込みデータを生成する生成工程と、前記評価埋め込みデータと、前記評価対象データの基準となる複数の基準データが前記埋め込み空間へ射影された基準埋め込みデータと、を用いて、各前記基準データが射影された前記埋め込み空間における前記評価対象データの密度を算出する算出工程と、前記密度に基づいて、前記評価対象データの独自性を評価する評価工程と、を備える。
【0006】
本開示の第2の形態によれば、データ評価装置が提供される。このデータ評価装置は、入力されるデータの特徴を埋め込み空間へ射影するように機械学習させた学習モデルと、評価対象データの基準となる複数の基準データが前記学習モデルによって前記埋め込み空間へ射影された基準埋め込みデータと、を記憶する記憶部と、プロセッサーと、を備える。前記プロセッサーは、前記評価対象データを取得する処理と、前記評価対象データを前記学習モデルに入力することで、前記評価対象データが前記埋め込み空間へ射影された評価埋め込みデータを生成する処理と、前記評価埋め込みデータと、前記基準埋め込みデータと、を用いて、各前記基準データが射影された前記埋め込み空間における前記評価対象データの密度を算出する処理と、前記密度に基づいて、前記評価対象データの独自性を評価する処理と、を実行する。
【0007】
本開示の第3の形態によれば、プログラムが提供される。このプログラムは、入力されるデータの特徴を埋め込み空間へ射影するように機械学習させた学習モデルに、評価対象データを入力することで、前記評価対象データが前記埋め込み空間へ射影された評価埋め込みデータを生成する機能と、前記評価埋め込みデータと、前記評価対象データの基準となる複数の基準データが前記埋め込み空間へ射影された基準埋め込みデータと、を用いて、各前記基準データが射影された前記埋め込み空間における前記評価対象データの密度を算出する機能と、前記密度に基づいて、前記評価対象データの独自性を評価する機能と、をコンピューターに実現させる。
【図面の簡単な説明】
【0008】
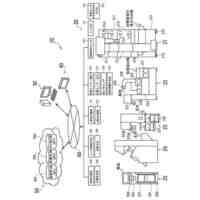
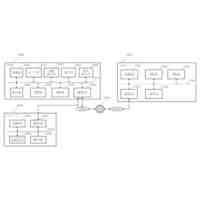
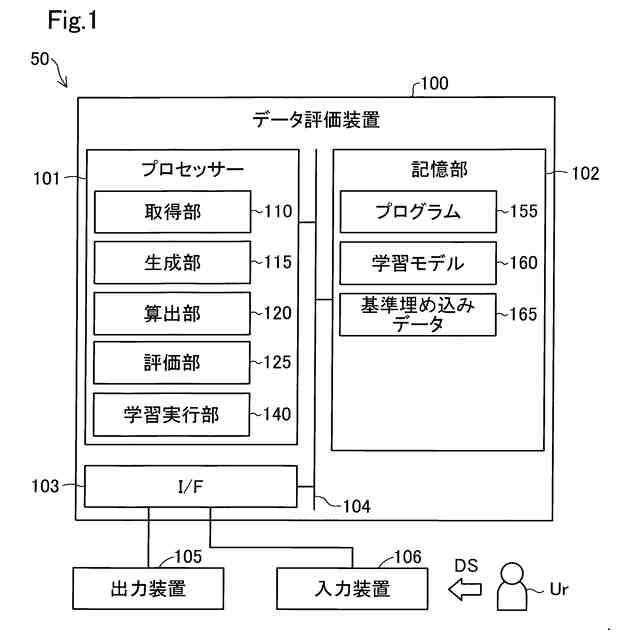
データ処理システムの概略構成を示すブロック図である。
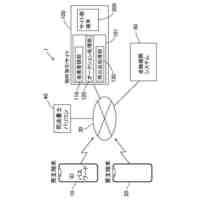
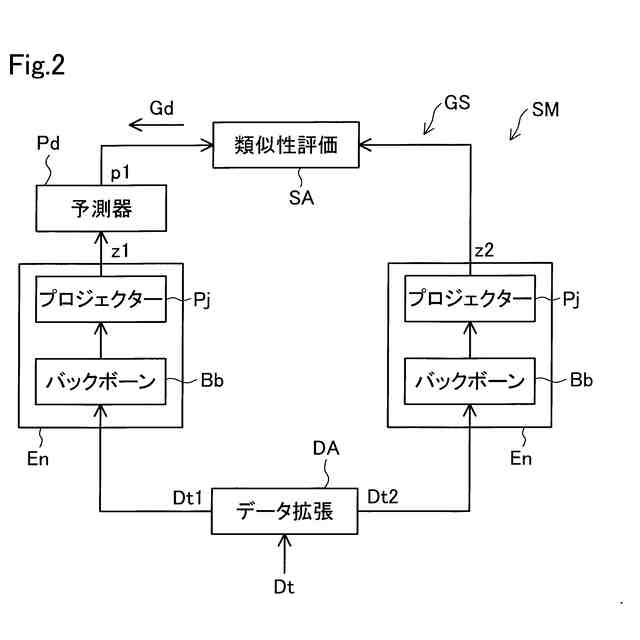
学習モデルの学習手法を説明する概念図である。
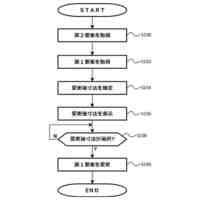
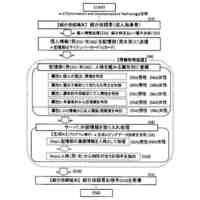
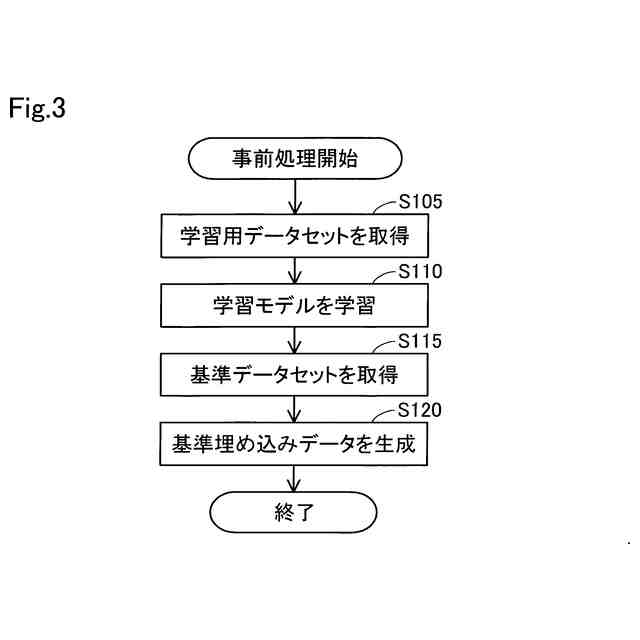
事前処理のフローチャートである。
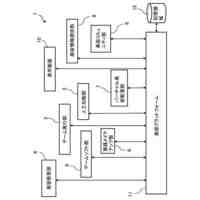
評価処理のフローチャートである。
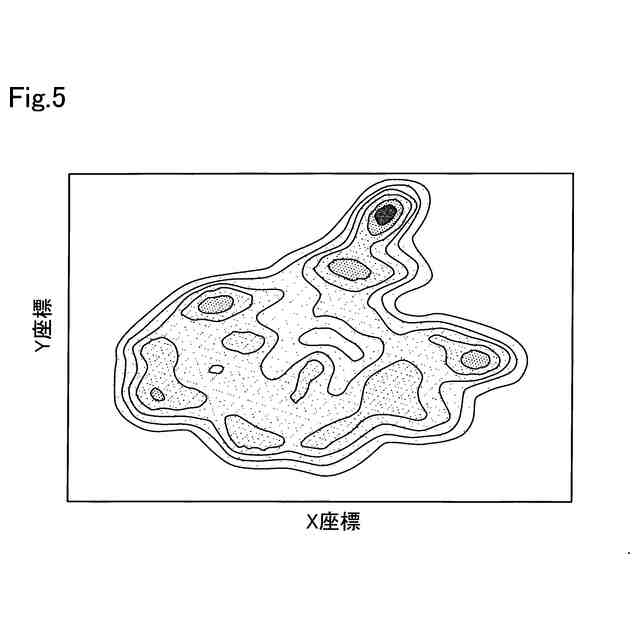
確率密度関数の例を示す説明図である。
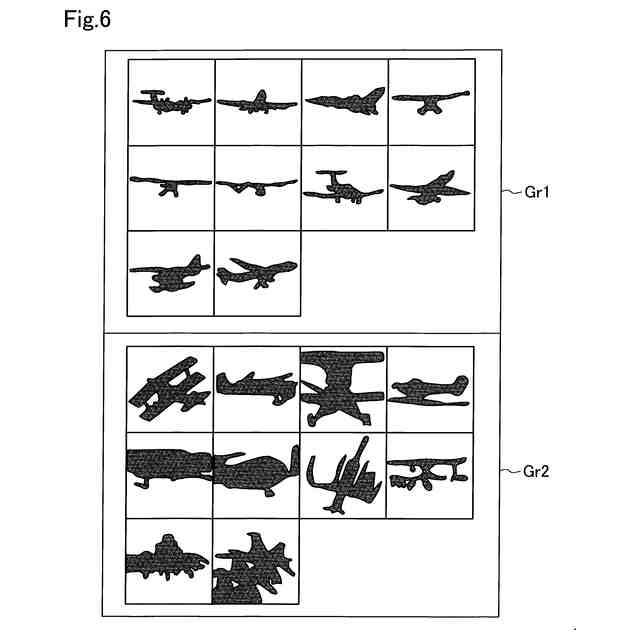
評価対象データの評価結果の例を示す説明図である。
【発明を実施するための形態】
【0009】
A.第1実施形態:
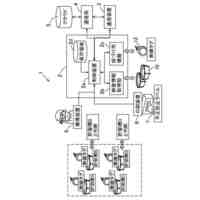
図1は、第1実施形態におけるデータ処理システム50の概略構成を示すブロック図である。データ処理システム50は、画像データやスペクトルデータや文字列データといった種々のデータの独自性を評価するために用いられる。
【0010】
データの独自性は、そのデータが属するデータ群における、そのデータに類似する他のデータの個数の少なさの度合いを表す。データの独自性は、そのデータが属するデータ群において、予め定められた程度以上にそのデータに類似する他のデータの個数が多いほど高い。一般的に、データ同士が類似するか否かは、データ間の距離や、データ同士の類似度に基づいて評価可能である。この場合、データ間の距離としては、例えば、ユークリッド距離やマンハッタン距離を使用可能である。また、類似度としては、例えば、コサイン類似度や、交差エントロピーに基づく類似度を使用可能である。また、各データの独自性は、各データの多様性と相関する。具体的には、データ群により独自性の高いデータがより多く含まれることは、そのデータ群に含まれる各データの多様性がより高いことを意味する。以下では、各データの多様性がより高いデータ群や、各データの多様性がより高いデータセットのことを、単に、「多様性が高いデータ群」や「多様性が高いデータセット」ともいう。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
個人
裁判のAI化
1か月前
個人
情報処理システム
1か月前
個人
フラワーコートA
25日前
個人
工程設計支援装置
17日前
個人
情報処理装置
2か月前
個人
記入設定プラグイン
2か月前
個人
検査システム
1か月前
個人
介護情報提供システム
1か月前
個人
設計支援システム
1か月前
個人
携帯情報端末装置
18日前
個人
設計支援システム
1か月前
株式会社サタケ
籾摺・調製設備
1か月前
個人
不動産売買システム
2か月前
キヤノン電子株式会社
携帯装置
1か月前
個人
結婚相手紹介支援システム
14日前
株式会社カクシン
支援装置
1か月前
個人
備蓄品の管理方法
1か月前
株式会社アジラ
進入判定装置
3日前
個人
パスポートレス入出国システム
3日前
個人
アンケート支援システム
27日前
個人
ジェスチャーパッドのガイド部材
1か月前
サクサ株式会社
中継装置
28日前
サクサ株式会社
中継装置
1か月前
キヤノン株式会社
情報処理装置
1か月前
キヤノン株式会社
情報処理装置
1か月前
個人
食事受注会計処理システム
4日前
株式会社BONNOU
管理装置
2か月前
大阪瓦斯株式会社
住宅設備機器
11日前
東洋電装株式会社
操作装置
1か月前
株式会社ワコム
電子消去具
2か月前
株式会社アジラ
移動方向推定装置
26日前
株式会社やよい
美容支援システム
7日前
個人
リテールレボリューションAIタグ
24日前
アスエネ株式会社
排水量管理方法
1か月前
キヤノン電子株式会社
名刺管理システム
1か月前
ホシデン株式会社
タッチ入力装置
2か月前
続きを見る
他の特許を見る


 特許ウォッチ
特許ウォッチ