TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025118696
公報種別
公開特許公報(A)
公開日
2025-08-13
出願番号
2025071540,2023543426
出願日
2025-04-23,2021-12-14
発明の名称
アシスタントコマンドの文脈的抑制
出願人
グーグル エルエルシー
,
Google LLC
代理人
個人
,
個人
,
個人
主分類
G10L
15/22 20060101AFI20250805BHJP(楽器;音響)
要約
【課題】文脈的オーディオデータに基づいてアシスタントコマンドの実行を抑制するための方法を提供する。
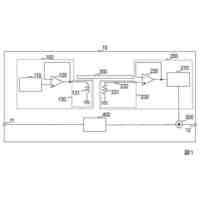
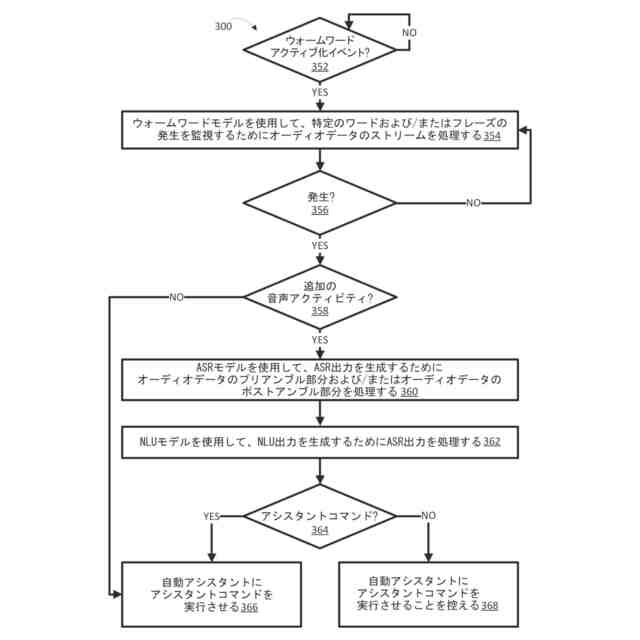
【解決手段】いくつかの実装形態は、ウォームワードモデルを使用して、アシスタントコマンドに関連付けられた特定のワードおよび/またはフレーズ(例えば、ウォームワード)に対応するオーディオデータの部分を決定するためにオーディオデータのストリームを処理し、自動音声認識(ASR)モデルを使用して、ASR出力を生成するために、(例えば、ウォームワードに先行する)オーディオデータのプリアンブル部分および/または(例えば、ウォームワードに続く)オーディオデータのポストアンブル部分)を処理し、ASR出力を処理することに基づいて、アシスタントコマンドが実行されることをユーザが意図していたかどうかを判定する。
【選択図】図1
特許請求の範囲
【請求項1】
1つまたは複数のプロセッサによって実装される方法であって、前記方法が、
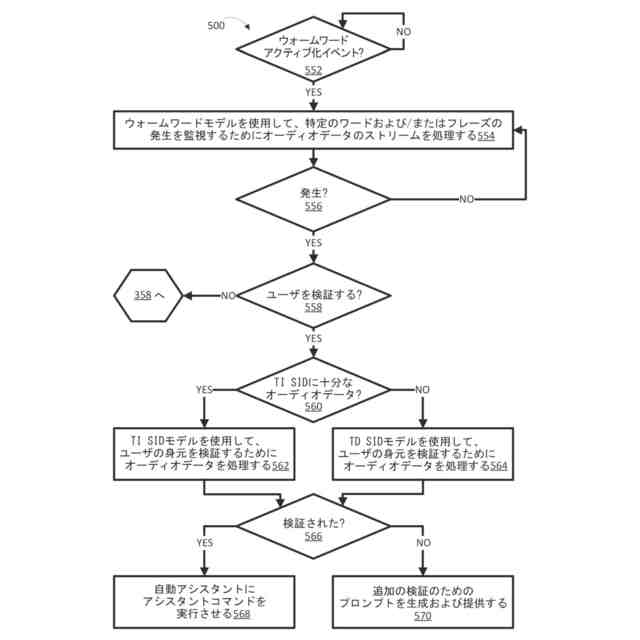
ウォームワードモデルを使用して、1つまたは複数の特定のワードまたはフレーズの発生を監視するためにオーディオデータのストリームを処理するステップであって、前記オーディオデータのストリームが、ユーザのクライアントデバイスの1つまたは複数のマイクロフォンによって生成され、前記1つまたは複数の特定のワードまたはフレーズの各々が、アシスタントコマンドに関連付けられる、ステップと、
前記オーディオデータの一部が前記特定のワードまたはフレーズのうちの1つまたは複数に対応すると判定したことに応答して、
自動音声認識(ASR)モデルを使用して、ASR出力を生成するために前記オーディオデータのプリアンブル部分および/または前記オーディオデータのポストアンブル部分を処理するステップであって、
前記オーディオデータの前記プリアンブル部分が、前記1つまたは複数の特定のワードまたはフレーズに対応する前記オーディオデータの前記一部に先行し、
前記オーディオデータの前記ポストアンブル部分が、前記1つまたは複数の特定のワードまたはフレーズに対応する前記オーディオデータの前記一部に続く、
ステップと、
前記ASR出力を処理することに基づいて、前記1つまたは複数の特定のワードまたはフレーズが前記アシスタントコマンドの実行を引き起こすことを前記ユーザが意図していたかどうかを判定するステップと、
前記1つまたは複数の特定のワードまたはフレーズが、前記特定のワードまたはフレーズのうちの1つまたは複数に関連付けられた前記アシスタントコマンドの実行を引き起こすことを、前記ユーザが意図していなかったと判定したことに応答して、
自動アシスタントに、前記特定のワードまたはフレーズのうちの1つまたは複数に関連付けられた前記アシスタントコマンドを実行させることを控えるステップと、
前記1つまたは複数の特定のワードまたはフレーズが、前記特定のワードまたはフレーズのうちの1つまたは複数に関連付けられた前記アシスタントコマンドの実行を引き起こすことを、前記ユーザが意図していたと判定したことに応答して、
前記自動アシスタントに、前記特定のワードまたはフレーズのうちの1つまたは複数に関連付けられた前記アシスタントコマンドを実行させるステップと
を含む、方法。
続きを表示(約 2,800 文字)
【請求項2】
ウォームワードアクティブ化イベントの発生を検出するステップと、
前記ウォームワードアクティブ化イベントの前記発生を検出したことに応答して、前記ウォームワードモデルを利用する1つまたは複数の現在休止中の自動アシスタント機能をアクティブ化するステップと
をさらに含み、
前記1つまたは複数の特定のワードまたはフレーズの前記発生を監視するために前記ウォームワードモデルを使用して前記オーディオデータのストリームを処理するステップが、前記ウォームワードモデルを利用する前記1つまたは複数の現在休止中の自動アシスタント機能をアクティブ化するステップに応答する、
請求項1に記載の方法。
【請求項3】
前記ウォームワードアクティブ化イベントが、前記クライアントデバイスにおいて受信される通話、前記クライアントデバイスにおいて受信されるテキストメッセージ、前記クライアントデバイスにおいて受信される電子メール、前記クライアントデバイスにおいて鳴るアラーム、前記クライアントデバイスにおいて鳴るタイマ、前記クライアントデバイスもしくは前記クライアントデバイスの環境内の追加のクライアントデバイスにおいて再生されるメディア、前記クライアントデバイスにおいて受信される通知、前記クライアントデバイスの場所、または前記クライアントデバイスにおいてアクセス可能なソフトウェアアプリケーションのうちの1つまたは複数を含む、請求項2に記載の方法。
【請求項4】
前記ASR出力を処理することに基づいて、前記1つまたは複数の特定のワードまたはフレーズが、前記1つまたは複数の特定のワードまたはフレーズに関連付けられた前記アシスタントコマンドの実行を引き起こすことを、前記ユーザが意図していたかどうかを判定するステップが、
自然言語理解(NLU)モデルを使用して、NLU出力を生成するために前記ASR出力を処理するステップであって、前記ASR出力が、前記オーディオデータの前記プリアンブル部分に基づくが、前記オーディオデータの前記ポストアンブル部分に基づかずに生成される、ステップと、
前記NLU出力に基づいて、前記1つまたは複数の特定のワードまたはフレーズが前記アシスタントコマンドの実行を引き起こすことを前記ユーザが意図していたかどうかを判定するステップと
を含む、請求項1から3のいずれか一項に記載の方法。
【請求項5】
前記1つまたは複数の特定のワードまたはフレーズが、前記特定のワードまたはフレーズのうちの1つまたは複数に関連付けられた前記アシスタントコマンドの実行を引き起こすことを、前記ユーザが意図していたかどうかを判定するのに、前記NLU出力が不十分であると判定したことに応答して、
前記ASRモデルを使用して、追加のASR出力を生成するために前記オーディオデータの前記ポストアンブル部分を処理するステップと、
前記追加のASR出力を処理することに基づいて、前記1つまたは複数の特定のワードまたはフレーズが、前記特定のワードまたはフレーズのうちの1つまたは複数に関連付けられた前記アシスタントコマンドの実行を引き起こすことを、前記ユーザが意図していたかどうかを判定するステップと
をさらに含む、請求項4に記載の方法。
【請求項6】
前記ASR出力を処理することに基づいて、前記1つまたは複数の特定のワードまたはフレーズが、前記特定のワードまたはフレーズのうちの1つまたは複数に関連付けられた前記アシスタントコマンドの実行を引き起こすことを、前記ユーザが意図していたかどうかを判定するステップが、
自然言語理解(NLU)モデルを使用して、NLU出力を生成するために前記ASR出力を処理するステップであって、前記ASR出力が、前記オーディオデータの前記プリアンブル部分と前記オーディオデータの前記ポストアンブル部分との両方に基づいて生成される、ステップと、
前記NLU出力に基づいて、前記1つまたは複数の特定のワードまたはフレーズが前記アシスタントコマンドの実行を引き起こすことを前記ユーザが意図していたかどうかを判定するステップと
を含む、請求項1から3のいずれか一項に記載の方法。
【請求項7】
前記1つまたは複数の特定のワードまたはフレーズが、前記特定のワードまたはフレーズのうちの1つまたは複数に関連付けられた前記アシスタントコマンドの実行を引き起こすことを、前記ユーザが意図していたかどうかを判定するのに、前記NLU出力が不十分であると判定したことに応答して、
前記ASRモデルを使用して、追加のASR出力を生成するために前記オーディオデータの追加のポストアンブル部分を処理するステップであって、前記オーディオデータの前記追加のポストアンブル部分が、前記オーディオデータの前記ポストアンブル部分に続く、ステップと、
前記追加のASR出力を処理することに基づいて、前記1つまたは複数の特定のワードまたはフレーズが、前記特定のワードまたはフレーズのうちの1つまたは複数に関連付けられた前記アシスタントコマンドの実行を引き起こすことを、前記ユーザが意図していたかどうかを判定するステップと
をさらに含む、請求項6に記載の方法。
【請求項8】
エンドポインティングモデルを使用して、前記オーディオデータのストリーム内に捕捉され、前記1つまたは複数の特定のワードまたはフレーズを含む口頭発話に対する複数のタイムスタンプを生成するために前記オーディオデータのストリームを処理するステップ
をさらに含む、請求項1から7のいずれか一項に記載の方法。
【請求項9】
前記複数のタイムスタンプが、少なくとも、前記ユーザが前記口頭発話を提供し始めた第1の時間に関連付けられた第1のタイムスタンプと、前記ユーザが前記口頭発話内に含まれる前記1つまたは複数の特定のワードまたはフレーズを提供し始めた前記第1の時間に続く第2の時間に関連付けられた第2のタイムスタンプと、前記ユーザが前記口頭発話内に含まれる前記1つまたは複数の特定のワードまたはフレーズを提供し終えた前記第2の時間に続く第3の時間に関連付けられた第3のタイムスタンプと、前記ユーザが前記口頭発話を提供し終えた前記第3の時間に続く第4の時間に関連付けられた第4のタイムスタンプとを含む、請求項8に記載の方法。
【請求項10】
前記オーディオデータの前記プリアンブル部分が、前記第1のタイムスタンプと前記第2のタイムスタンプとの間の前記口頭発話に対応する任意のオーディオデータを含む、請求項9に記載の方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本願は、アシスタントコマンドの文脈的抑制に関する。
続きを表示(約 6,100 文字)
【背景技術】
【0002】
人間は、本明細書では「自動アシスタント」と呼ばれる(「チャットボット」、「対話型パーソナルアシスタント」、「インテリジェントパーソナルアシスタント」、「パーソナル音声アシスタント」、「会話型エージェント」などとも呼ばれる)対話型ソフトウェアアプリケーションを用いて人間対コンピュータのダイアログに参加し得る。例えば、人間(自動アシスタントと対話する場合、「ユーザ」と呼ばれる場合がある)は、場合によってはテキストに変換され、次いで処理され得る口頭の自然言語入力(すなわち、口頭発話)を自動アシスタントに提供し得、および/またはテキストの(例えば、タイプされた)自然言語入力を提供することによって提供し得る。自動アシスタントは、一般に、応答のユーザインターフェース出力(例えば、可聴および/または視覚的ユーザインターフェース出力)を提供することによって、スマートデバイスを制御することによって、および/または他のアクションを実行することによって、口頭発話に応答する。
【0003】
自動アシスタントは、典型的には、口頭発話を解釈して応答する際に、構成要素のパイプラインに依存する。例えば、自動音声認識(ASR)エンジンは、口頭発話の転写(すなわち、用語および/または他のトークンのシーケンス)などのASR出力を生成するために、ユーザの口頭発話に対応するオーディオデータを処理することができる。さらに、自然言語理解(NLU)エンジンは、口頭発話を提供する際のユーザの意図、およびオプションで意図に関連付けられたパラメータのためのスロット値などのNLU出力を生成するためにASR出力を処理することができる。さらに、NLU出力を処理し、口頭発話に対する応答コンテンツを取得するための構造化要求などのフルフィルメント出力を生成するために、フルフィルメントエンジンが使用され得る。
【0004】
場合によっては、構成要素のこのパイプラインが、バイパスされる可能性がある。例えば、いくつかの機械学習(ML)モデル(「ウォームワードモデル」とも呼ばれる)は、フルフィルメント出力に直接マッピングされる特定のワードおよび/またはフレーズ(「ウォームワード」とも呼ばれる)を検出するようにトレーニングされ得る。例えば、ユーザが音楽を聴いており、「音量を上げて」という口頭発話を提供した場合、これらのMLモデルのうちの1つまたは複数は、オーディオデータを処理し、いかなるASR出力および/またはNLU出力も生成することなく、音楽を再生しているデバイスの音量を上げさせる構造化要求を生成することができる。しかしながら、これらのウォームワードは、典型的には、日常会話において発生し得る一般的なワードおよび/またはフレーズである。結果として、これらのウォームワードに関連付けられたアシスタントコマンドは、ユーザによって意図せずにトリガされる場合があり、それによって、計算リソースを浪費する。さらに、これらの場合のうちのいくつかにおいて、ユーザは、これらのアシスタントコマンドを取り消さなければならない場合があり、それによって、さらなる計算リソースを浪費する。
【発明の概要】
【課題を解決するための手段】
【0005】
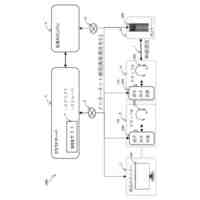
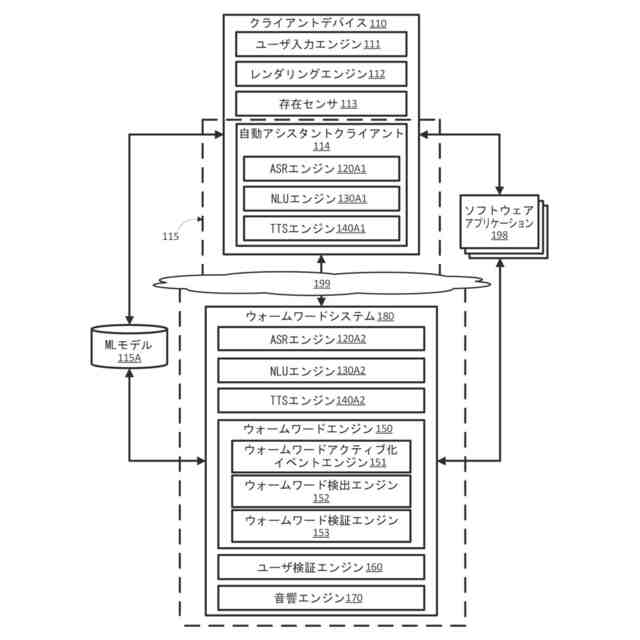
本明細書において開示される実装形態は、文脈的オーディオデータ、ならびに/または特定のワードおよび/もしくはフレーズのうちの1つもしくは複数を含む口頭発話を提供したユーザの身元に基づいて、1つまたは複数の特定のワードおよび/またはフレーズ(例えば、ウォームワード)に関連付けられたアシスタントコマンドの実行(遂行)を文脈的に抑制することに向けられている。いくつかの実装形態は、1つまたは複数のウォームワードモデルを使用して、アシスタントコマンドに関連付けられた特定のワードおよび/またはフレーズに対応するオーディオデータの部分を決定するために、オーディオデータのストリームを処理する。これらの実装形態のうちのいくつかは、自動音声認識(ASR)モデルを使用して、ASR出力を生成するために、オーディオデータのプリアンブル部分(例えば、特定のワードおよび/またはフレーズのうちの1つまたは複数に対応するオーディオデータの部分に先行するオーディオデータの部分)および/またはオーディオデータのポストアンブル部分(例えば、特定のワードおよび/またはフレーズのうちの1つまたは複数に対応するオーディオデータの部分に続くオーディオデータの部分)を処理する。さらに、これらの実装形態のうちのいくつかは、ASR出力を処理することに基づいて、オーディオデータ内に捕捉された口頭発話を提供したユーザが特定のワードまたはフレーズのうちの1つまたは複数に関連付けられるアシスタントコマンドが実行されることを意図していたかどうかを決定する。追加のまたは代替の実装形態は、オーディオデータのストリーム内に捕捉された口頭発話を提供したユーザを識別するのにオーディオデータが十分であるかどうかを決定するために、または口頭発話を提供したユーザがアシスタントコマンドの実行を引き起こす権限を与えられているかどうかを決定するために、話者識別(SID)モデルを使用してオーディオデータのストリームを処理することができる。
【0006】
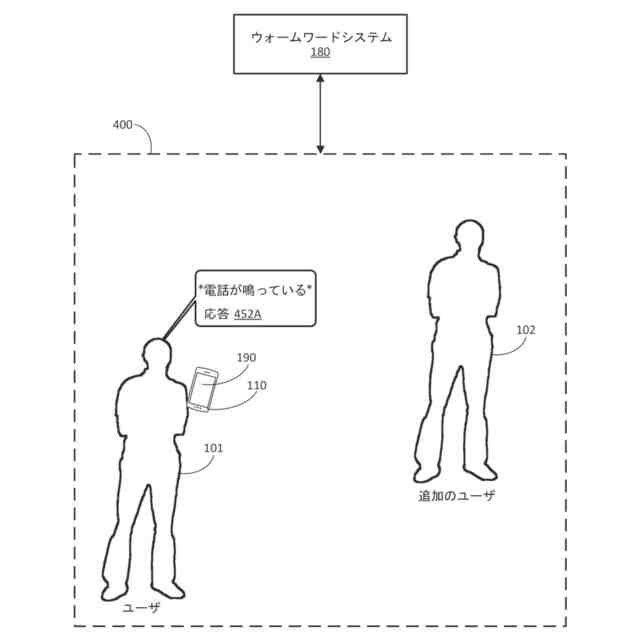
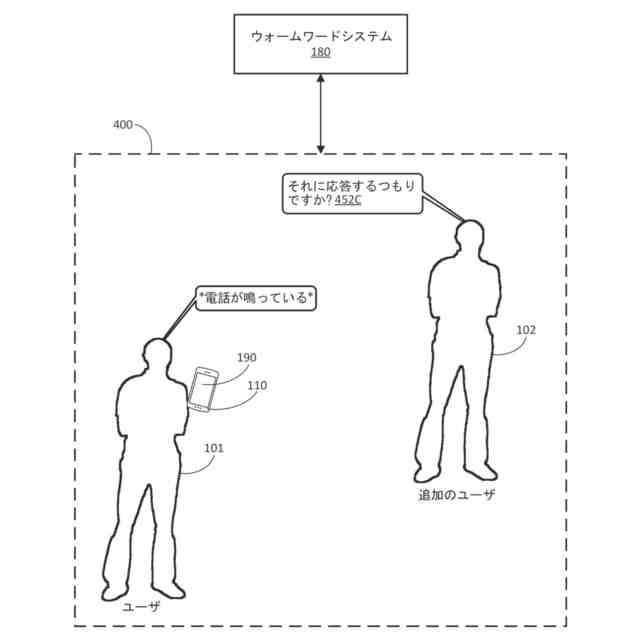
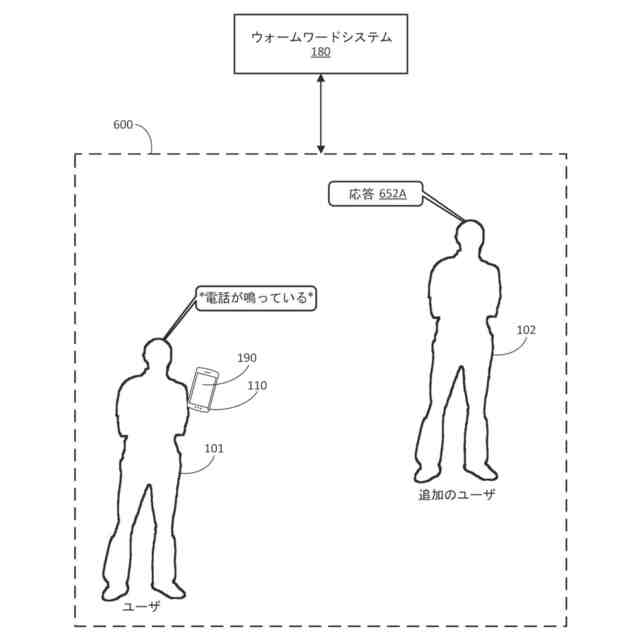
例えば、ユーザのクライアントデバイスにおいて通話が受信されたと仮定する。さらに、クライアントデバイスのユーザが、クライアントデバイスにおいて通話が受信されたことに応答して「応答して(answer)」という口頭発話を提供したと仮定する。この例において、「応答して」が、クライアントデバイス内に少なくとも部分的に実装された自動アシスタントに通話に応答させるアシスタントコマンドに関連付けられたウォームワードであると仮定すると、自動アシスタントは、1つまたは複数のウォームワードモデルを使用して「応答して」というウォームワードの発生を検出したことに基づいて、ユーザの代わりに通話に応答することができる。対照的に、クライアントデバイスにおいて通話が受信されたことに応答して、クライアントデバイスのユーザが代わりに「それには応答したくない(I don't want to answer that)」という口頭発話を提供したと仮定する。この例において、自動アシスタントは、自動アシスタントが、ウォームワードモデルのうちの1つまたは複数を使用して「応答して」というウォームワードの発生を検出したにもかかわらず、ユーザの代わりに通話に応答すべきではないと決定するために、文脈的オーディオデータを処理することができる。
【0007】
いくつかの実装形態において、ウォームワードモデルのうちの1つまたは複数を利用する1つまたは複数の自動アシスタントの構成要素は、ウォームワードアクティブ化イベントの発生を検出したことに応答してアクティブ化され得る。ウォームワードアクティブ化イベントは、例えば、クライアントデバイスにおいて受信される通話、クライアントデバイスにおいて受信されるテキストメッセージ、クライアントデバイスにおいて受信される電子メール、クライアントデバイスにおいて鳴るアラームもしくはタイマ、クライアントデバイスもしくはクライアントデバイスの環境内の追加のクライアントデバイスにおいて再生されるメディア、クライアントデバイスにおいて受信される通知、クライアントデバイスの場所、クライアントデバイスにおいてアクセス可能なソフトウェアアプリケーション、および/またはクライアントデバイスもしくはクライアントデバイスと通信する追加のクライアントデバイスを制御させるために、ユーザが口頭発話を提供することができる、クライアントデバイスに関連付けられた他のイベントを含むことができる。特に、これらのホットワードアクティブ化イベントのうちのいくつかは、個別のイベント(例えば、クライアントデバイスにおいて受信される通知、クライアントデバイスにおいて受信されるテキストメッセージ、クライアントデバイスにおいて受信される電子メール、クライアントデバイスにおいて鳴るアラームまたはタイマなど)であり、一方、これらのウォームワードアクティブ化イベントのうちの他のいくつかは、連続的なイベント(例えば、クライアントデバイスにおいてアクセス可能なソフトウェアアプリケーション)である。さらに、これらのウォームワードアクティブ化イベントは、相互に排他的ではないことが留意されるべきである。別の言い方をすれば、1つまたは複数の自動アシスタント構成要素が複数の異種のウォームワードアクティブ化イベントに基づいてウォームワードをアクティブに監視しているように、所与の時点において複数のウォームワードアクティブ化イベントが検出され得る。
【0008】
本明細書で説明するウォームワードモデルは、検出されると、自動アシスタントに特定のワードおよび/またはフレーズのうちの1つまたは複数に関連付けられたアシスタントコマンドを実行させる1つまたは複数の特定のワードおよび/またはフレーズ(例えば、ウォームワード)を検出するようにトレーニングされた複数の異種のウォームワードモデル(例えば、オーディオキーワード分類モデル)を含むことができる。いくつかの実装形態において、所与のウォームワードモデルは、所与のウォームワードアクティブ化イベントに関連付けられたワードおよび/またはフレーズの特定のサブセットを検出するようにトレーニングされ得る。例えば、クライアントデバイスまたはクライアントデバイスと通信する別のクライアントデバイス(例えば、スマートスピーカ)において音楽が再生されていると仮定する。この例において、所与のウォームワードモデルは、音楽を一時停止させ得る「一時停止(pause)」ウォームワード、音楽を一時停止した後に再開させ得る「再開(resume)」ウォームワード、音楽の音量を上げさせ得る「音量を上げる(volume up)」ウォームワード、音楽の音量を下げさせ得る「音量を下げる(volume down)」ウォームワード、音楽を次の曲にスキップさせ得る「次の(next)」ウォームワード、ならびに音楽に関連付けられた他の特定のワードおよび/またはフレーズに関するものなどの、音楽を制御することに関連付けられたアシスタントコマンドを実行させる特定のワードおよび/またはフレーズのサブセットを検出するようにトレーニングされ得る。したがって、この例において、音楽がクライアントデバイスまたはクライアントデバイスと通信する別のクライアントデバイスにおいて再生されていると判定したことに応答して、所与のウォームワードモデルを利用する現在休止中のアシスタント機能のうちの1つまたは複数がアクティブ化され得る。
【0009】
追加のまたは代替の実装形態において、所与のウォームワードアクティブ化イベントに関連付けられたワードおよび/またはフレーズのサブセット検出するように複数のウォームワードモデルがトレーニングされ得る。上記の例を続けると、第1のウォームワードモデルは、「一時停止(pause)」のウォームワードおよび「再開(resume)」のウォームワードなどの1つまたは複数の第1の特定のワードおよび/またはフレーズを検出するようにトレーニングされ得、第2のウォームワードモデルは、「音量を上げる(volume up)」のウォームワードおよび「音量を下げる(volume down)」のウォームワードなどの1つまたは複数の第2の特定のワードおよび/またはフレーズを検出するようにトレーニングされ得、第3のウォームワードモデルは、「次の(next)」のウォームワード、ならびに音楽ウォームワードアクティブ化イベントに関連付けられた他の特定のワードおよび/またはフレーズに関するものなどの1つまたは複数の第3の特定のワードおよび/またはフレーズを検出するようにトレーニングされ得る。したがって、この例において、少なくとも第1のウォームワードモデル、第2のウォームワードモデル、および第3のウォームワードモデルを利用する現在休止中のアシスタント機能のうちの1つまたは複数が、クライアントデバイスまたはクライアントデバイスと通信する別のクライアントデバイスにおいて音楽が再生されていると判定したことに応答してアクティブ化され得る。
【0010】
いくつかの実装形態において、特定のワードおよび/またはフレーズのうちの1つまたは複数がオーディオデータのストリーム内で検出されたことに応答して、オーディオデータのプリアンブル部分および/またはオーディオデータのポストアンブル部分は、口頭発話を提供したユーザが、実際に、特定のワードおよび/またはフレーズのうちの検出された1つまたは複数に関連付けられたアシスタントコマンドが実行されることを意図していたかどうかを判定するために処理され得る。例えば、ユーザのクライアントデバイスにおいて通話が受信されたと再び仮定し、クライアントデバイスにおいて通話が受信されたことに応答してクライアントデバイスのユーザが「それには応答したくない(I don't want to answer that)」という口頭発話を提供したと仮定する。この例において、オーディオデータのプリアンブル部分(例えば、「したくない(I don't want to)」に応答する)」は、クライアントデバイスのオーディオバッファから取得され得、ASR出力を生成するために、ASRモデルを使用して処理され得る。さらに、ASR出力は、NLU出力を生成するためにNLUモデルを使用して処理され得る。この例において、ASR出力および/またはNLU出力は、ユーザが、ユーザの代わりに自動アシスタントに通話に応答させる「応答する」を意図していないことを示す。それらの実装形態のいくつかのバージョンにおいて、1つまたは複数の特定のワードおよび/またはフレーズに対応する(例えば、「応答する」に対応する)オーディオデータの部分は、追加的または代替的に、ASR出力とNLU出力とを生成するためにオーディオデータのプリアンブル部分ともに処理され得る。それらの実装形態のいくつかのバージョンにおいて、オーディオデータのポストアンブル部分(例えば、「それに(that)」に対応する)は、追加的または代替的に、ASR出力とNLU出力とを生成するために、オーディオデータのプリアンブル部分、ならびに/または特定のワードおよび/もしくはフレーズのうちの1つまたは複数に対応するオーディオデータの部分とともに処理され得る。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
富士フイルム株式会社
消音器
17日前
三井化学株式会社
遮音構造体
1か月前
三井化学株式会社
吸音構造体
1か月前
三井化学株式会社
遮音構造体
1か月前
林テレンプ株式会社
防音カバー
1か月前
積水化学工業株式会社
吸音構造体
13日前
ヤマハ株式会社
弦楽器用の支持装置
17日前
株式会社イシダ
商品処理装置
4日前
富士フイルム株式会社
消音器付き風路
17日前
ヤマハ株式会社
リード
11日前
株式会社総合車両製作所
吸音パネル
1か月前
株式会社レゾナック
吸音材及び車両部材
1か月前
NOK株式会社
吸音構造体
3日前
個人
電子管楽器
1か月前
株式会社第一興商
カラオケ装置
1か月前
株式会社JVCケンウッド
情報処理装置及び情報処理方法
1か月前
株式会社第一興商
カラオケ装置
5日前
株式会社第一興商
カラオケ装置
26日前
株式会社第一興商
カラオケ装置
1か月前
株式会社コルグ
電子楽器用アナログエフェクタ
1か月前
ヤマハ株式会社
鍵盤装置
18日前
株式会社エクシング
端末装置、及び、端末装置用プログラム
11日前
シャープ株式会社
電子機器および電子機器の制御方法
6日前
有限会社舞システム企画
介護情報生成システム
17日前
トヨタ自動車株式会社
防音カバー
5日前
ヤマハ株式会社
連打判定装置および方法、プログラム
27日前
シャープ株式会社
制御装置、電気機器、およびシステム
20日前
トヨタ自動車株式会社
制御装置
21日前
AOBAENERGY株式会社
サービス提供機器
1か月前
株式会社麗光
防音積層体とその製造に用いる遮音膜、および遮音膜シート
10日前
富士通株式会社
情報処理プログラム、情報処理方法及び情報処理装置
6日前
本田技研工業株式会社
音声認識方法および音声認識装置
19日前
井関農機株式会社
作業車の操縦者用騒音低減装置
1か月前
コニカミノルタ株式会社
音声変換装置、音声変換方法および音声変換プログラム
25日前
ローランド株式会社
鍵盤装置および鍵の揺動の規制方法
1か月前
ローランド株式会社
鍵盤装置および押鍵情報の検出方法
1か月前
続きを見る
他の特許を見る





 特許ウォッチ
特許ウォッチ