TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025106595
公報種別
公開特許公報(A)
公開日
2025-07-15
出願番号
2025070071,2023151074
出願日
2025-04-22,2021-11-25
発明の名称
音声処理装置、音声処理方法、及び、プログラム
出願人
ソフトバンク株式会社
代理人
個人
,
個人
,
個人
,
個人
主分類
G10L
13/02 20130101AFI20250708BHJP(楽器;音響)
要約
【課題】聞き手のストレスの軽減を可能とすること。
【解決手段】音声処理システム1は、第1のユーザの発話音声の信号である発話音声信号
を取得する取得部と、前記発話音声信号に基づいて抽出される特徴量を音声認識モデルに
入力して、一以上の単語からなる単語列を含むテキストデータを生成する音声認識部と、
前記テキストデータに基づいて抽出される特徴量を音声合成モデルに入力して、合成音声
の信号である合成音声信号を生成する音声合成部と、第2のユーザに対して前記合成音声
を出力する音声出力部と、を備える。
【選択図】図4
特許請求の範囲
【請求項1】
第1のユーザの発話音声の信号である発話音声信号を取得する取得部と、
前記発話音声信号に基づいて抽出される特徴量を音声認識モデルに入力して、一以上の
単語からなる単語列を含むテキストデータを生成する音声認識部と、
前記テキストデータに基づいて抽出される特徴量を音声合成モデルに入力して、合成音
声の信号である合成音声信号を生成する音声合成部と、
第2のユーザに対して前記合成音声を出力する音声出力部と、
を備える音声処理システム。
続きを表示(約 2,100 文字)
【請求項2】
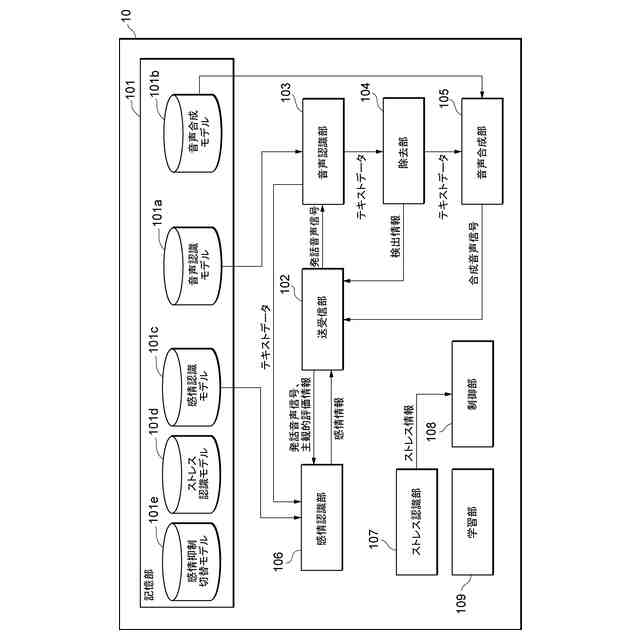
前記発話音声信号に対応する第1のユーザの感情情報を生成する感情認識部と、
前記第2のユーザに対して前記感情情報を表示する表示部と、を備え、
前記表示部は、前記音声出力部による前記合成音声の出力タイミングに合わせて、前記
合成音声に対応する前記感情情報を表示する、
請求項1に記載の音声処理システム。
【請求項3】
前記発話音声信号に対応する第1のユーザの感情情報を生成する感情認識部と、
前記感情情報に基づいて、前記音声出力部から前記合成音声又は前記発話音声のどちら
を出力するかを切り替える制御部と、
を備える請求項1又は2に記載の音声処理システム。
【請求項4】
前記感情認識部は、発話音声信号、当該発話音声信号から抽出した特徴量、当該発話音
声信号から生成したテキストデータ、当該テキストデータから抽出された特徴量、又はこ
れらの少なくとも二つの組み合わせを入力とし、当該発話音声信号の発話者の感情情報を
出力するよう機械学習された感情認識モデルに、前記取得部が取得した発話音声信号、当
該発話音声信号から抽出した音声特徴量、当該発話音声信号から生成したテキストデータ
、当該テキストデータに対応するテキスト特徴量、又はこれらの少なくとも二つの組み合
わせを入力することにより、前記取得部が取得した発話音声信号に対応する第1のユーザ
の感情情報を生成する、請求項2又は3に記載の音声処理システム。
【請求項5】
前記音声合成部は、前記感情認識部が生成した感情情報に基づいて、前記感情情報が示
す感情が前記合成音声に反映されるように、前記合成音声信号を生成する、請求項2から
請求項4のいずれかに記載の音声処理システム。
【請求項6】
前記第2のユーザのストレス状況に関するストレス情報を生成するストレス認識部と、
前記ストレス情報に基づいて、前記音声出力部から前記合成音声又は前記発話音声のど
ちらを出力するかを切り替える制御部と、
を備える請求項1又は2に記載の音声処理システム。
【請求項7】
前記第2のユーザによって入力される切り替え情報に基づいて、前記音声出力部から前
記合成音声又は前記発話音声のどちらを出力するかを切り替える制御部と、
前記第2のユーザによって入力された切り替え情報を、前記切り替え情報が入力された
際の発話音声信号と時間軸上で関連付けた情報を生成し、当該情報に基づいて、発話音声
信号、当該発話音声信号から抽出した特徴量、当該発話音声信号から生成したテキストデ
ータ、当該テキストデータから抽出された特徴量、又はこれらの少なくとも二つの組み合
わせを入力とし、前記合成音声と前記発話音声とを切り替えるタイミングを出力とする感
情抑制切替モデルを機械学習する学習部とを更に備え、
前記制御部は、前記感情抑制切替モデルに、前記取得部が取得した発話音声信号、当該
発話音声信号から抽出した特徴量、当該発話音声信号から生成したテキストデータ、当該
テキストデータから抽出された特徴量、又はこれらの少なくとも二つの組み合わせを入力
することにより、前記合成音声と前記発話音声とを切り替えるタイミングを生成する、請
求項1から請求項6のいずれかに記載の音声処理システム。
【請求項8】
第1のユーザの発話音声の信号である発話音声信号を取得する取得部と、
前記発話音声信号に基づいて抽出される特徴量を音声認識モデルに入力して、一以上の
単語からなる単語列を含むテキストデータを生成する音声認識部と、
前記テキストデータに基づいて抽出される特徴量を音声合成モデルに入力して、第2の
ユーザに対して出力される合成音声の信号である合成音声信号を生成する音声合成部と、
を備える音声処理装置。
【請求項9】
前記発話音声信号に対応する第1のユーザの感情情報を生成する感情認識部と、
前記感情情報を、前記感情情報に対応する発話音声信号及び/又は合成音声信号と時間
軸上で関連付けして、外部装置に対して送信する送信部とを備える、
請求項8に記載の音声処理装置。
【請求項10】
第1のユーザの発話音声の信号である発話音声信号を取得する工程と、
前記発話音声信号に基づいて抽出される特徴量を音声認識モデルに入力して、一以上の
単語からなる単語列を含むテキストデータを生成する工程と、
前記テキストデータに基づいて抽出される特徴量を音声合成モデルに入力して、合成音
声の信号である合成音声信号を生成する工程と、
第2のユーザに対して前記合成音声を出力する工程と、
を含む音声処理方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本発明は、音声処理システム、音声処理装置及び音声処理方法に関する。
続きを表示(約 2,200 文字)
【背景技術】
【0002】
従来、顧客満足度(Customer Satisfaction:CS)向上のために、顧客の苦情等に対
してオペレータが電話で応対する各種のコールセンターが運用されている。このような顧
客応対業務では、顧客がオペレータに対して威圧的な言動や理不尽な要求を行う「カスタ
マーハラスメント」により、オペレータの精神不調を招いたり、オペレータの離職率が高
くなったりすることが問題視されている。
【0003】
近年、このようなカスタマーハラスメントから、企業側が従業員であるオペレータを守
るための音声変換システムも検討されている。例えば、特許文献1では、入力音声信号か
ら音量及びピッチ変動量を算出し、音量及びピッチ変動量が所定値を超える場合に、音量
及びピッチ変動量が所定内に収まるように音量及びピッチを変換して出力するように制御
することが記載されている。
【先行技術文献】
【特許文献】
【0004】
特開2004-252085号公報
【発明の概要】
【発明が解決しようとする課題】
【0005】
しかしながら、例えば、特許文献1に記載の方法で話し手の発話音声を変換するだけで
は、話し手(第1のユーザ)の感情が十分に抑制されず、聞き手(第2のユーザ)のスト
レスを十分に軽減できない恐れがある。一方、聞き手のストレスを軽減するために、聞き
手に出力される話し手の発話音声を変換すると、聞き手が話し手の感情を十分に認識でき
ず、聞き手が適切な応対を行うことができない恐れもある。
【0006】
そこで、本発明は、聞き手のストレスの十分な軽減、及び/又は、聞き手の適切な応対
を可能とする音声処理システム、音声処理装置及び音声処理方法を提供する。
【課題を解決するための手段】
【0007】
本発明の一つの態様に係る音声処理システムは、第1のユーザの発話音声の信号である
発話音声信号を取得する取得部と、前記発話音声信号に基づいて抽出される特徴量を音声
認識モデルに入力して、一以上の単語からなる単語列を含むテキストデータを生成する音
声認識部と、前記テキストデータに基づいて抽出される特徴量を音声合成モデルに入力し
て、合成音声の信号である合成音声信号を生成する音声合成部と、第2のユーザに対して
前記合成音声を出力する音声出力部と、を備える。
【0008】
この態様によれば、第1のユーザの発話音声信号に基づいてテキストデータを生成し、
当該テキストデータに基づいて生成される合成音声を第2のユーザに出力する。このため
、第1のユーザの発話音声に含まれる顧客の感情を十分に抑制した合成音声を第2のユー
ザに聞かせることができ、第1のユーザの感情的発話に起因する第2のユーザのストレス
を十分に軽減できる。
【0009】
上記音声処理システムにおいて、前記感情認識部は、発話音声信号、当該発話音声信号
から抽出した特徴量、当該発話音声信号から生成したテキストデータ、当該テキストデー
タから抽出された特徴量、又はこれらの少なくとも二つの組み合わせを入力とし、当該発
話音声信号の発話者の感情情報を出力するよう機械学習された感情認識モデルに、前記取
得部が取得した発話音声信号、当該発話音声信号から抽出した音声特徴量、当該発話音声
信号から生成したテキストデータ、当該テキストデータに対応するテキスト特徴量、又は
これらの少なくとも二つの組み合わせを入力することにより、前記取得部が取得した発話
音声信号に対応する第1のユーザの感情情報を生成してもよい。
【図面の簡単な説明】
【0010】
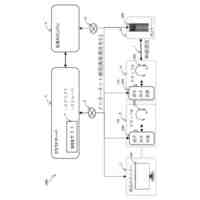
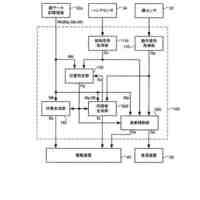
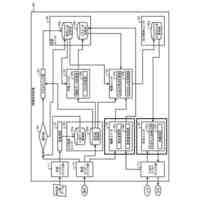
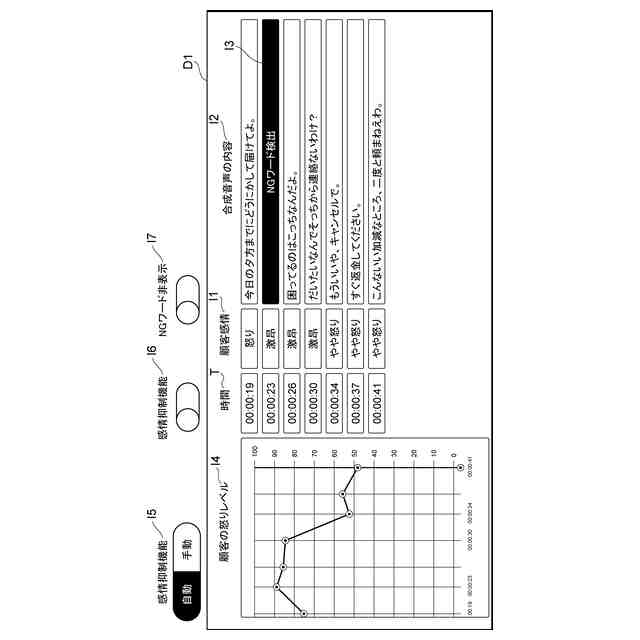
本実施形態に係る音声処理システム1の概略の一例を示す図である。
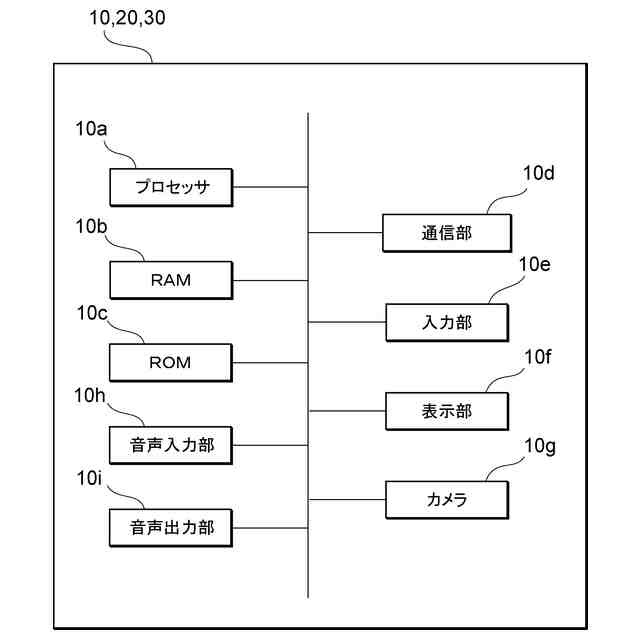
本実施形態に係る音声処理システム1を構成する各装置の物理構成の一例を示す図である。
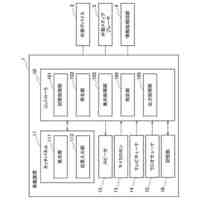
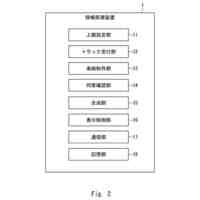
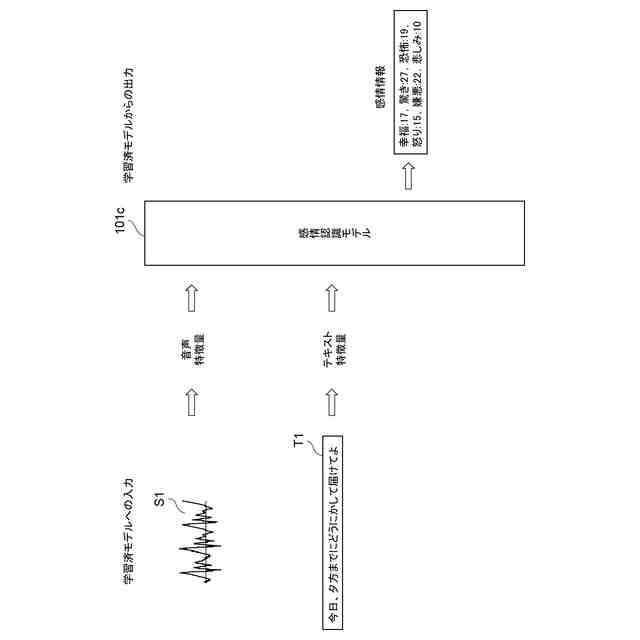
本実施形態に係る音声処理装置10の機能構成の一例を示す図である。
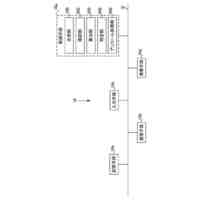
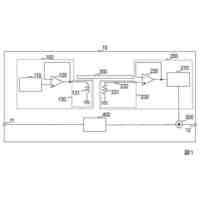
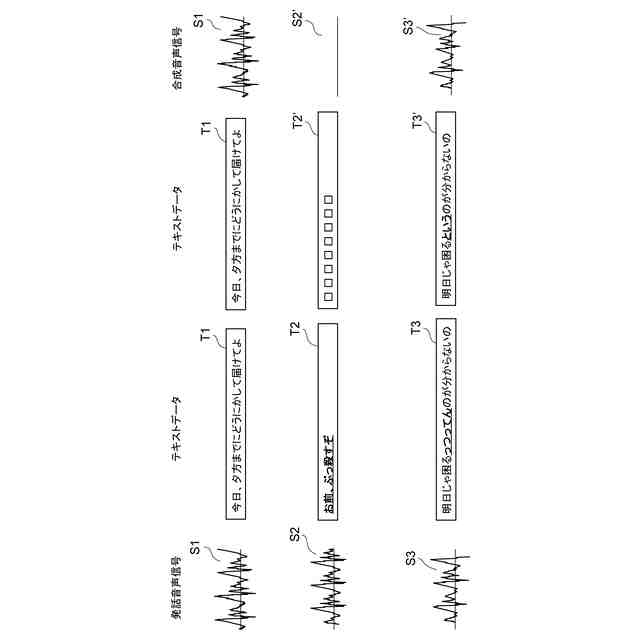
本実施形態に係る合成音声信号の生成の一例を示す図である。
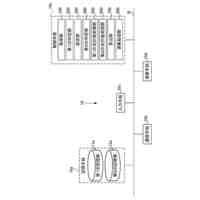
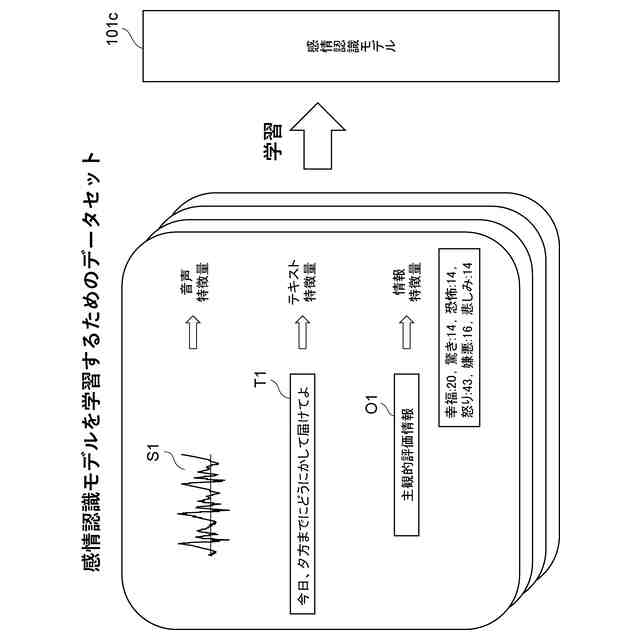
本実施形態に係る顧客の感情情報の生成の一例を示す図である。
本実施形態に係る顧客の感情情報の生成の一例を示す図である。
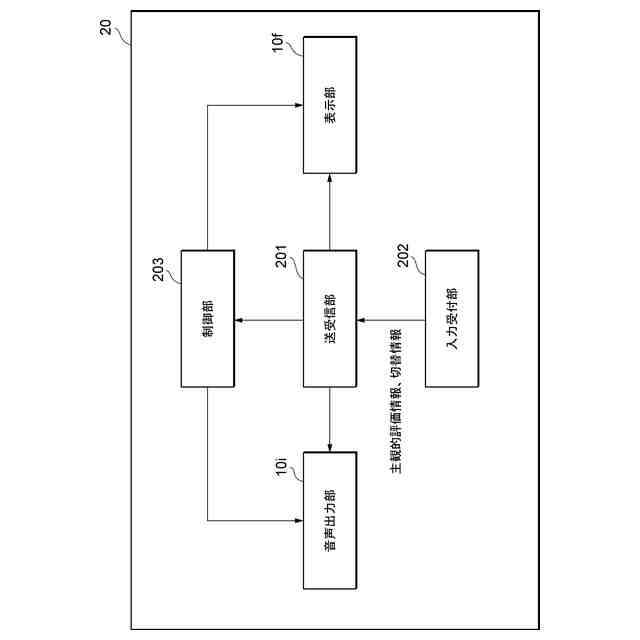
本実施形態に係るオペレータ端末20の機能構成の一例を示す図である。
本実施形態に係る画面D1の一例を示す図である。
本実施形態に係る画面D2の一例を示す図である。
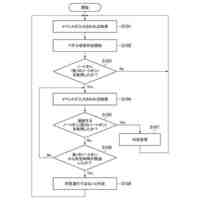
本実施形態に係る感情抑制動作の一例を示すフローチャートである。
本実施形態に係る感情抑制機能の自動切り替え動作を示すフローチャートである。
本実施形態の変更例に係る合成音声信号の生成の一例を示す図である。
本実施形態に係る画面D3の一例を示す図である。
【発明を実施するための形態】
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
ソフトバンク株式会社
移動通信システム
2日前
ソフトバンク株式会社
移動通信システム
2日前
ソフトバンク株式会社
移動通信システム
2日前
ソフトバンク株式会社
光電変換装置及び飛行体
1日前
ソフトバンク株式会社
拘束具、電池システム、及び飛行体
27日前
ソフトバンク株式会社
情報処理装置、情報処理方法および情報処理プログラム
6日前
ソフトバンク株式会社
音声処理装置、音声処理方法、及び、プログラム
22日前
個人
弦楽器用押弦補助具及び弦楽器
1か月前
富士フイルム株式会社
消音器
5日前
三井化学株式会社
遮音構造体
1か月前
三井化学株式会社
遮音構造体
1か月前
三井化学株式会社
遮音構造体
1か月前
三井化学株式会社
吸音構造体
29日前
林テレンプ株式会社
防音カバー
1か月前
株式会社ドクター中松創研
歌及び歌の制作方法
1か月前
積水化学工業株式会社
吸音構造体
1日前
ヤマハ株式会社
弦楽器用の支持装置
5日前
富士フイルム株式会社
消音器付き風路
5日前
株式会社総合車両製作所
吸音パネル
28日前
株式会社JVCケンウッド
車載装置
1か月前
株式会社レゾナック
吸音材及び車両部材
21日前
個人
電気自動車等の「接近音」における最適な「音の種類」
1か月前
株式会社HOWA
遮音構造
1か月前
カシオ計算機株式会社
楽器
1か月前
個人
電子管楽器
1か月前
株式会社JVCケンウッド
情報処理装置及び情報処理方法
29日前
株式会社第一興商
カラオケ装置
28日前
株式会社第一興商
カラオケ装置
29日前
株式会社第一興商
カラオケ装置
14日前
有限会社舞システム企画
介護情報生成システム
5日前
ヤマハ株式会社
鍵盤装置
6日前
ヤマハ株式会社
連打判定装置および方法、プログラム
15日前
株式会社コルグ
電子楽器用アナログエフェクタ
27日前
シャープ株式会社
制御装置、電気機器、およびシステム
8日前
ヤマハ株式会社
発音制御装置
1か月前
川上産業株式会社
吸音シート
1か月前
続きを見る
他の特許を見る



 特許ウォッチ
特許ウォッチ