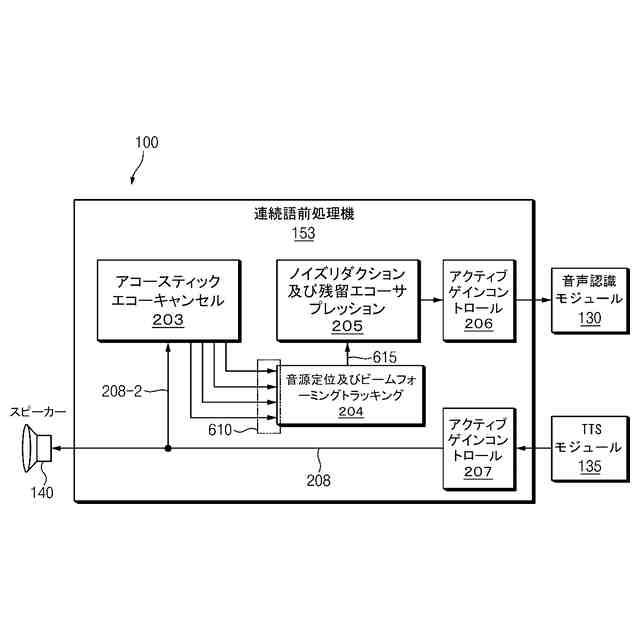
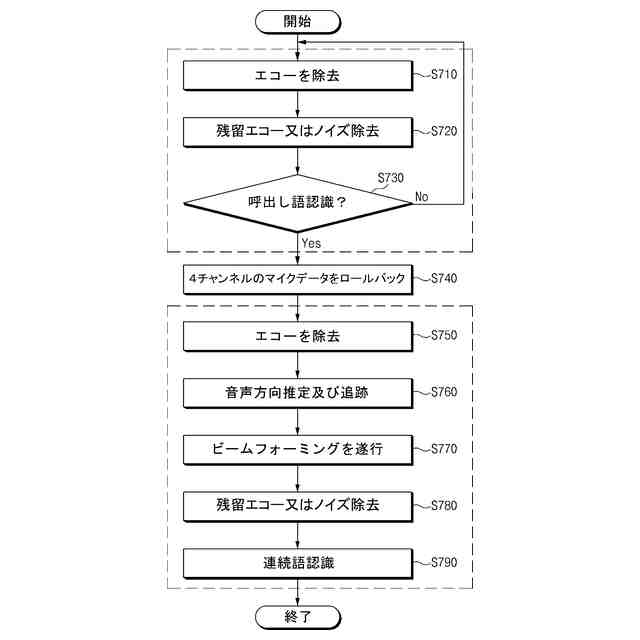
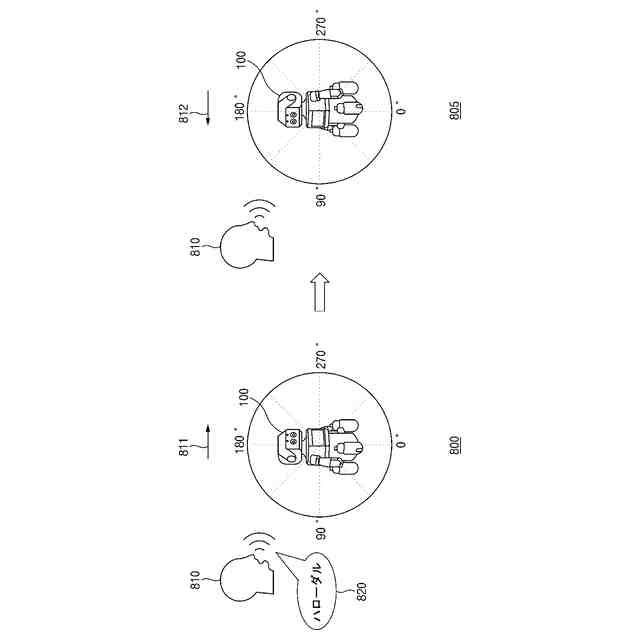
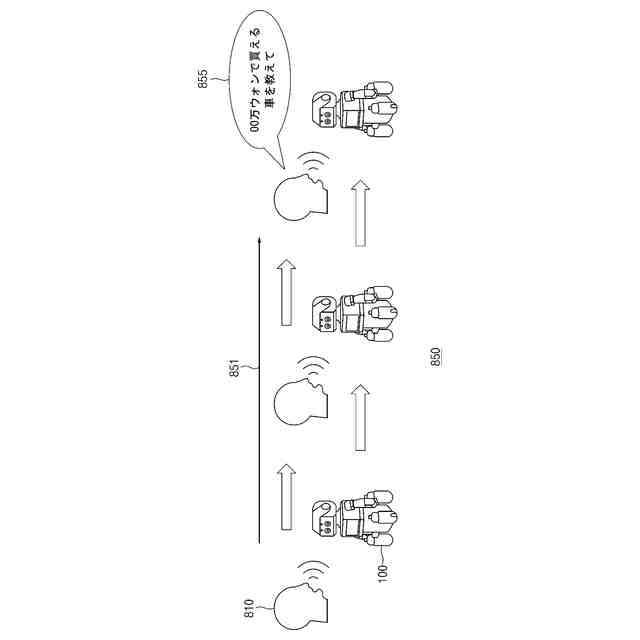
TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025131477
公報種別
公開特許公報(A)
公開日
2025-09-09
出願番号
2024106626
出願日
2024-07-02
発明の名称
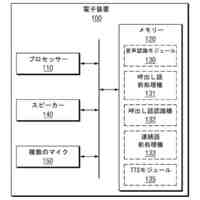
電子装置及びその動作方法
出願人
現代自動車株式会社
,
HYUNDAI MOTOR COMPANY
,
起亞株式会社
,
KIA CORPORATION
代理人
弁理士法人共生国際特許事務所
主分類
G10L
15/28 20130101AFI20250902BHJP(楽器;音響)
要約
【課題】呼び出し語を識別するための電子装置及びその動作方法を提供する。
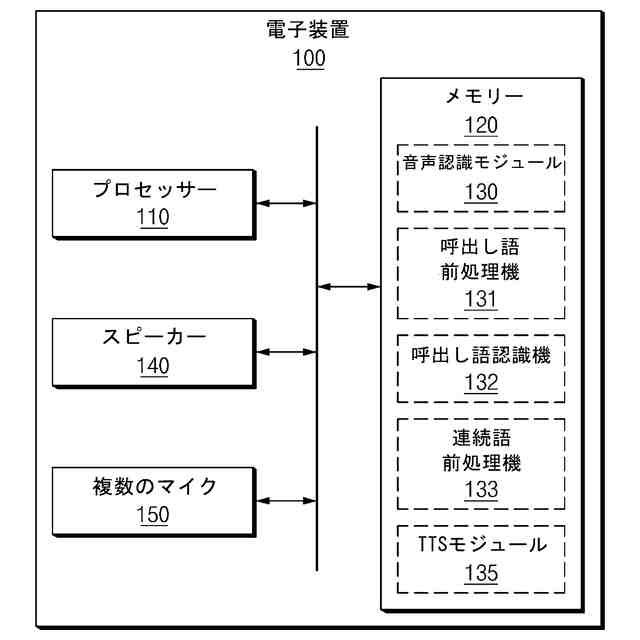
【解決手段】本発明の電子装置は、複数のマイクと、スピーカーと、プロセッサーと、メモリーと、を備え、プロセッサーは、複数のマイクを用いて複数の音声信号を獲得し、複数の音声信号を獲得する時間の流れに応じて、複数の音声信号のうちの第1マイクから獲得された第1音声信号に対する音声認識を行うことで、指定された呼び出し語を識別し、指定された呼び出し語の識別を完了した第1時点から指定された呼び出し語に対応する発話時間の前である第2時点を獲得し、複数の音声信号のうちの第2時点から獲得された一部分に対する音声認識を行うように構成される。
【選択図】図1
特許請求の範囲
【請求項1】
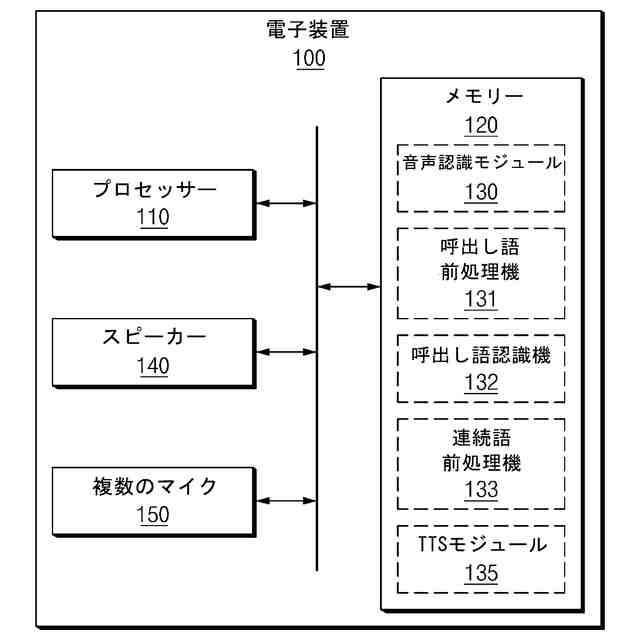
複数のマイクと、
スピーカーと、
プロセッサーと、
メモリーと、備え、
前記プロセッサーは、
前記複数のマイクを用いて複数の音声信号を獲得し、
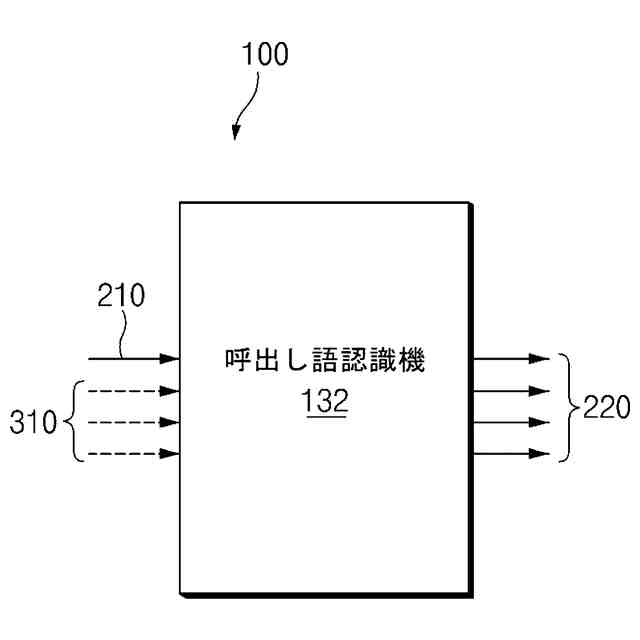
前記複数の音声信号を獲得する時間の流れに応じて、前記複数の音声信号のうちの第1マイクから獲得された第1音声信号に対する音声認識を行うことで、指定された呼び出し語(designated call word)を識別し、
前記指定された呼び出し語の識別を完了した第1時点(time point)から前記指定された呼び出し語に対応する発話(utterance)時間の前である第2時点を獲得し、
前記複数の音声信号のうちの前記第2時点から獲得された一部分に対する音声認識を行うように構成されることを特徴とする電子装置。
続きを表示(約 1,700 文字)
【請求項2】
前記プロセッサーは、
前記一部分に対する音声認識を行うことに基づいて、前記複数の音声信号の位相差(phase difference)を用いて前記複数の音声信号に関連する使用者の位置を追跡(track)し、
前記複数のマイクを用いて前記使用者の位置に向けてビームフォーミングを行うことで、獲得された前記複数の音声信号から前記使用者の発話に対応するターゲット音声が強化された(enhanced)第2音声信号を識別するように構成されることを特徴とする請求項1に記載の電子装置。
【請求項3】
前記プロセッサーは、
前記第2音声信号を識別したことに基づいて前記第2音声信号に含まれるノイズ信号を識別し、
前記ノイズ信号の振幅(amplitude)を減少させるように構成されることを特徴とする請求項2に記載の電子装置。
【請求項4】
前記プロセッサーは、
前記第2音声信号を識別したことに基づいて前記ターゲット音声を示すターゲット音声信号を識別し、
前記第2音声信号に含まれる前記ターゲット音声信号の振幅を増加させ、
前記ターゲット音声信号の振幅が増加した前記第2音声信号を用いて音声認識を行うように構成されることを特徴とする請求項2に記載の電子装置。
【請求項5】
前記プロセッサーは、
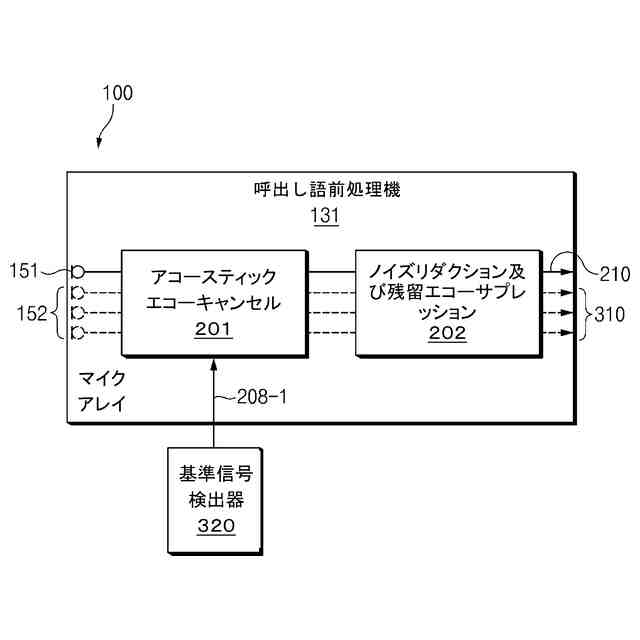
前記スピーカーから出力された基準信号(reference signal)を含む前記複数の音声信号のそれぞれにおいて前記基準信号の振幅を減少させ、
前記基準信号の振幅が減少した前記複数の音声信号の位相差を用いて前記使用者の位置を追跡するように構成されることを特徴とする請求項2に記載の電子装置。
【請求項6】
前記プロセッサーは、
前記第1音声信号内で、指定されたテキストを示す基準信号及び前記基準信号とは区分されるノイズ信号を識別し、
前記基準信号、前記ノイズ信号、又はこれらのいずれかの組み合わせの少なくとも一つの振幅を減少させ、
前記少なくとも一つの振幅が減少した前記第1音声信号を用いて前記指定された呼び出し語を識別するように構成されることを特徴とする請求項1に記載の電子装置。
【請求項7】
前記プロセッサーは、前記第1マイクから獲得された第1音声信号に対する音声認識を行う間に、前記複数の音声信号のうちの前記第1音声信号とは区分される他の音声信号に対する音声認識をバイパスするように構成されることを特徴とする請求項1に記載の電子装置。
【請求項8】
前記プロセッサーは、
前記第1音声信号に対応する第1データセットを用いて前記第1音声信号に対する音声認識を行い、
前記他の音声信号に対する音声認識をバイパスする間に、指定されたデータサイズに基づいて前記他の音声信号に対応する他のデータセットの除去(deletion)を一時的に中止するように構成されることを特徴とする請求項7に記載の電子装置。
【請求項9】
前記プロセッサーは、
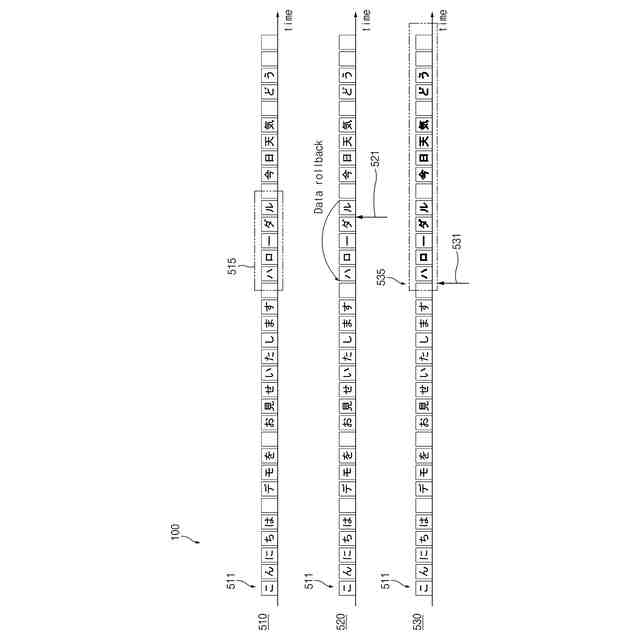
前記第1データセットから前記指定された呼び出し語に対応するテキストデータを識別し、
前記識別されたテキストデータに基づいて、前記第1データセットに対するロールバックと前記他のデータセットに対するロールバックとを行うことで前記第2時点を獲得し、
前記第2時点から前記第1データセット及び前記他のデータセット全体を用いて音声認識を行うように構成されることを特徴とする請求項8に記載の電子装置。
【請求項10】
前記プロセッサーは、
前記複数の音声信号に関連する使用者との距離に基づいて前記複数のマイクのうちの前記第1マイクを識別し、
前記第1マイクを用いて前記第1音声信号を獲得するように構成されることを特徴とする請求項1に記載の電子装置。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本発明は、電子装置及びその動作方法に関し、より詳しくは、音声信号を識別するための技術に関する。
続きを表示(約 4,300 文字)
【背景技術】
【0002】
音声認識サービスは、音声信号を電子装置が処理できるテキストや命令に変換する技術に基づくサービスを意味する。音声認識サービスには、使用者が音声で発話する内容を電子装置が処理して内容をテキストに変換するか又は音声命令を認識して特定の作業を行うようにする技術が主に使用されている。電子装置が音声認識サービスを提供するために使用者の位置を追跡するための音源方向推定(sound source localization)又はビームフォーミング(beamforming)技術が要求される。但し、使用者が移動しながら発話する場合、固定されたビームフォーミング方向によって音声認識の性能が急激に低下するという問題が発生する可能性がある。したがって、使用者の位置に応じて電子装置の位置及び/又は電子装置の方向を変更するための方案を研究する必要性がある。
【先行技術文献】
【特許文献】
【0003】
特開2022-128579号公報
【発明の概要】
【発明が解決しようとする課題】
【0004】
本発明は、上記従来技術に鑑みてなされたものであって、本発明の目的は、呼び出し語を識別するための電子装置及びその動作方法を提供することにある。
【課題を解決するための手段】
【0005】
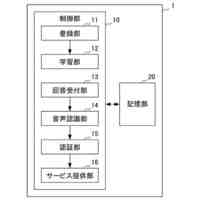
上記目的を達成するためになされた本発明の一態様による電子装置は、複数のマイクと、スピーカーと、プロセッサーと、メモリーと、を備え、前記プロセッサーは、前記複数のマイクを用いて複数の音声信号を獲得し、前記複数の音声信号を獲得する時間の流れに応じて、前記複数の音声信号のうちの第1マイクから獲得された第1音声信号に対する音声認識を行うことで、指定された呼び出し語(designated call word)を識別し、前記指定された呼び出し語の識別を完了した第1時点(time point)から前記指定された呼び出し語に対応する発話(utterance)時間の前である第2時点を獲得し、前記複数の音声信号のうちの前記第2時点から獲得された一部分に対する音声認識を行うように構成される。
【0006】
一実施形態において、前記プロセッサーは、前記一部分に対する音声認識を行うことに基づいて、前記複数の音声信号の位相差(phase difference)を用いて前記複数の音声信号に関連する使用者の位置を追跡(track)し、前記複数のマイクを用いて前記使用者の位置に向けてビームフォーミングを行うことで、獲得された前記複数の音声信号から前記使用者の発話に対応するターゲット音声が強化された(enhanced)第2音声信号を識別するように構成される。
一実施形態において、前記プロセッサーは、前記第2音声信号を識別したことに基づいて前記第2音声信号に含まれるノイズ信号を識別し、前記ノイズ信号の振幅(amplitude)を減少させるように構成される。
一実施形態において、前記プロセッサーは、前記第2音声信号を識別したことに基づいて前記ターゲット音声を示すターゲット音声信号を識別し、前記第2音声信号に含まれる前記ターゲット音声信号の振幅を増加させ、前記ターゲット音声信号の振幅が増加した前記第2音声信号を用いて音声認識を行うように構成される。
一実施形態において、前記プロセッサーは、前記スピーカーから出力された基準信号(reference signal)を含む前記複数の音声信号のそれぞれにおいて前記基準信号の振幅を減少させ、前記基準信号の振幅が減少した前記複数の音声信号の位相差を用いて前記使用者の位置を追跡するように構成される。
一実施形態において、前記プロセッサーは、前記第1音声信号内で、指定されたテキストを示す基準信号及び前記基準信号とは区分されるノイズ信号を識別し、前記基準信号、前記ノイズ信号、又はこれらのいずれかの組み合わせの少なくとも一つの振幅を減少させ、前記少なくとも一つの振幅が減少した前記第1音声信号を用いて前記指定された呼び出し語を識別するように構成される。
一実施形態において、前記プロセッサーは、前記第1マイクから獲得された第1音声信号に対する音声認識を行う間に、前記複数の音声信号のうちの前記第1音声信号とは区分される他の音声信号に対する音声認識をバイパスするように構成される。
一実施形態において、前記プロセッサーは、前記第1音声信号に対応する第1データセットを用いて前記第1音声信号に対する音声認識を行い、前記他の音声信号に対する音声認識をバイパスする間に、指定されたデータサイズに基づいて前記他の音声信号に対応する他のデータセットの除去(deletion)を一時的に中止するように構成される。
一実施形態において、前記プロセッサーは、前記第1データセットから前記指定された呼び出し語に対応するテキストデータを識別し、前記識別されたテキストデータに基づいて、前記第1データセットに対するロールバックと前記他のデータセットに対するロールバックとを行うことで前記第2時点を獲得し、前記第2時点から前記第1データセット及び前記他のデータセット全体を用いて音声認識を行うように構成される。
一実施形態において、前記プロセッサーは、前記複数の音声信号に関連する使用者との距離に基づいて前記複数のマイクのうちの前記第1マイクを識別し、前記第1マイクを用いて前記第1音声信号を獲得するように構成される。
【0007】
上記目的を達成するためになされた本発明の一態様による電子装置の動作方法は、複数のマイクを用いて複数の音声信号を獲得する段階と、前記複数の音声信号を獲得する時間の流れに応じて、前記複数の音声信号のうちの第1マイクから獲得された第1音声信号に対する音声認識を行うことで、指定された呼び出し語(designated call word)を識別する段階と、前記指定された呼び出し語の識別を完了した第1時点(time point)から前記指定された呼び出し語に対応する発話(utterance)時間の前である第2時点を獲得する段階と、前記複数の音声信号のうちの前記第2時点から獲得された一部分に対する音声認識を行う段階と、を有する。
【0008】
一実施形態において、前記一部分に対する音声認識を行う段階は、前記一部分に対する音声認識を行うことに基づいて、前記複数の音声信号の位相差(phase difference)を用いて前記複数の音声信号に関連する使用者の位置を追跡(track)する段階と、前記複数のマイクを用いて前記使用者の位置に向けてビームフォーミングを行うことで、獲得された前記複数の音声信号から前記使用者の発話に対応するターゲット音声が強化された(enhanced)第2音声信号を識別する段階と、を含む。
一実施形態において、前記第2音声信号を識別する段階は、前記第2音声信号に含まれるノイズ信号を識別する段階と、前記ノイズ信号の振幅を減少させる段階と、を含む。
一実施形態において、前記第2音声信号を識別する段階は、前記ターゲット音声を示すターゲット音声信号を識別する段階と、前記第2音声信号に含まれる前記ターゲット音声信号の振幅を増加させる段階と、前記ターゲット音声信号の振幅が増加した前記第2音声信号を用いて音声認識を行う段階と、を含む。
一実施形態において、前記使用者の位置を追跡する段階は、スピーカーから出力された基準信号(reference signal)を含む前記複数の音声信号のそれぞれにおいて前記基準信号の振幅を減少させる段階と、前記基準信号の振幅が減少した前記複数の音声信号の位相差を用いて前記使用者の位置を追跡する段階と、を含む。
一実施形態において、前記指定された呼び出し語を識別する段階は、前記第1音声信号内で、指定されたテキストを示す基準信号及び前記基準信号とは区分されるノイズ信号を識別する段階と、前記基準信号、前記ノイズ信号、又はこれらのいずれかの組み合わせの少なくとも一つの振幅を減少させる段階と、前記少なくとも一つの振幅が減少した前記第1音声信号を用いて前記指定された呼び出し語を識別する段階と、を含む。
一実施形態において、前記方法は、前記第1マイクから獲得された第1音声信号に対する音声認識を行う間に、前記複数の音声信号のうちの前記第1音声信号とは区分される他の音声信号に対する音声認識をバイパスする段階を更に含む。
一実施形態において、前記他の音声信号に対する音声認識をバイパスする段階は、前記第1音声信号に対応する第1データセットを用いて前記第1音声信号に対する音声認識を行う段階と、前記他の音声信号に対する音声認識をバイパスする間に、指定されたデータサイズに基づいて前記他の音声信号に対応する他のデータセットの除去(deletion)を一時的に中止する段階と、を含む。
一実施形態において、前記方法は、前記第1データセットから前記指定された呼び出し語に対応するテキストデータを識別する段階と、前記識別されたテキストデータに基づいて、前記第1データセットに対するロールバックと前記他のデータセットに対するロールバックとを行うことで前記第2時点を獲得する段階と、前記第2時点から前記第1データセット及び前記他のデータセット全体を用いて音声認識を行う段階と、を更に含む。
一実施形態において、前記方法は、前記複数の音声信号に関連する使用者との距離に基づいて前記複数のマイクのうちの前記第1マイクを識別する段階と、前記第1マイクを用いて前記第1音声信号を獲得する段階と、を更に含む。
【発明の効果】
【0009】
本発明によれば、複数のマイクの少なくとも一つのマイクを用いて呼び出し語を識別することができる。また、呼び出し語を識別した場合、複数のマイク全体を用いて音声認識を行うことができる。更に、呼び出し語を識別した場合、呼び出し語が発生した位置に基づいて電子装置の位置を変更することができる。
【0010】
その他、本明細書を通して直接的又は間接的に把握される多様な効果を提供することができる。
【図面の簡単な説明】
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
現代自動車株式会社
電子装置及びその動作方法
22日前
個人
破裂爆発波動体感バルーン
1か月前
株式会社白鳩
音漏れ抑制マスク
28日前
株式会社白鳩
音漏れ抑制マスク
28日前
積水化学工業株式会社
吸音構造体
1か月前
株式会社イシダ
商品処理装置
1か月前
株式会社豊田中央研究所
吸音構造体
2日前
株式会社東芝
吸音装置
今日
川崎重工業株式会社
表面材
1か月前
日本音響エンジニアリング株式会社
騒音低減装置
1か月前
ヤマハ株式会社
リード
1か月前
株式会社フジタ
環境音快音化システム
1か月前
株式会社イノアックコーポレーション
吸音材
21日前
個人
歌唱技術表示装置および歌唱技術表示方法
1か月前
NOK株式会社
吸音構造体
1か月前
株式会社第一興商
カラオケ装置
22日前
株式会社第一興商
カラオケ装置
1か月前
KDDI株式会社
認証装置、認証方法及び認証プログラム
21日前
株式会社第一興商
カラオケ装置
1か月前
カシオ計算機株式会社
減音器具
今日
カシオ計算機株式会社
減音器具
今日
株式会社第一興商
カラオケ装置
2日前
中原大學
能動騒音除去機能を持つレンジフード
2日前
株式会社エクシング
端末装置、及び、端末装置用プログラム
1か月前
シャープ株式会社
電子機器および電子機器の制御方法
1か月前
トヨタ自動車株式会社
防音カバー
1か月前
個人
楽曲検索装置、楽曲検索方法、及び楽曲検索プログラム
1か月前
マツダ株式会社
内燃機関の吸気音増幅装置
1か月前
トヨタ自動車株式会社
電気自動車
22日前
株式会社JVCケンウッド
クリッピング装置及びクリッピング方法
2日前
株式会社麗光
防音積層体とその製造に用いる遮音膜、および遮音膜シート
1か月前
富士通株式会社
情報処理プログラム、情報処理方法及び情報処理装置
1か月前
ローランド株式会社
打楽器および打面の形成方法
29日前
株式会社東芝
吸音装置及び音響メタマテリアル
今日
宮澤フル-ト製造株式会社
タンポ及び木管楽器
1か月前
カシオ計算機株式会社
制御装置、方法およびプログラム
2日前
続きを見る
他の特許を見る


 特許ウォッチ
特許ウォッチ