TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
公開番号
2025131875
公報種別
公開特許公報(A)
公開日
2025-09-09
出願番号
2025102590,2024531121
出願日
2025-06-18,2023-09-07
発明の名称
自己回帰生成ニューラルネットワークを使用するオーディオ生成
出願人
グーグル エルエルシー
,
Google LLC
代理人
個人
,
個人
,
個人
主分類
G10G
1/00 20060101AFI20250902BHJP(楽器;音響)
要約
【課題】オーディオ信号の予測を生成するための、コンピュータ記憶媒体にエンコードされたコンピュータプログラムを含む方法、システム、及び装置を提供する。
【解決手段】一実施形態に係る方法は、オーディオ信号を生成するための要求を受信することと、オーディオ信号のセマンティック表現を取得することと、1つまたは複数の生成ニューラルネットワークを使用して、かつ少なくともセマンティック表現を条件としてオーディオ信号の音響表現を生成することと、デコーダニューラルネットワークを使用して少なくとも音響表現を処理して、オーディオ信号の予測を生成することとを含む。
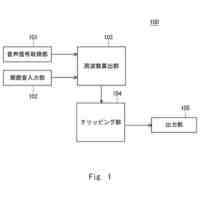
【選択図】図1
特許請求の範囲
【請求項1】
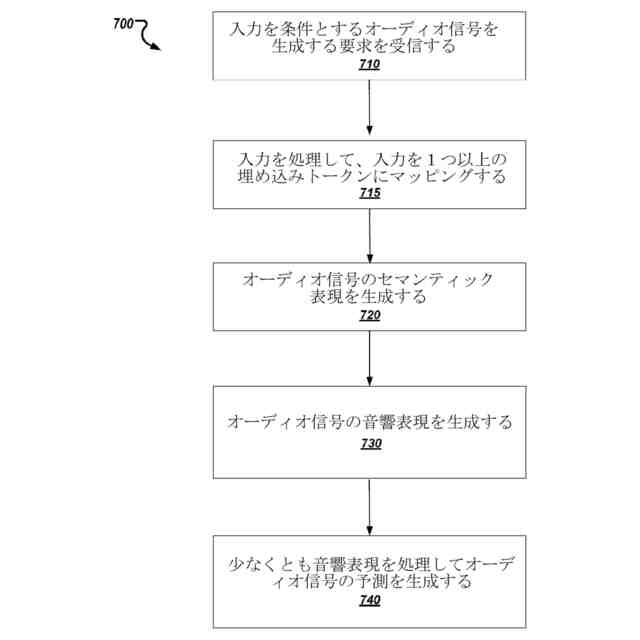
オーディオ信号の予測を生成するためのコンピュータ実装方法であって、
時間ウィンドウにまたがる複数の出力時間ステップの各々においてそれぞれのオーディオサンプルを有するオーディオ信号を生成するための要求を受信することと、
前記時間ウィンドウにまたがる複数の第1の時間ステップの各々においてそれぞれのセマンティックトークンを指定する前記オーディオ信号のセマンティック表現を取得することであって、各セマンティックトークンが、セマンティックトークンの語彙から選択され、対応する第1の時間ステップにおける前記オーディオ信号のセマンティックコンテンツを表す、前記取得することと、
1つまたは複数の生成ニューラルネットワークを使用して、かつ少なくとも前記セマンティック表現を条件として、前記オーディオ信号の音響表現を生成することであって、前記音響表現が、前記時間ウィンドウにまたがる複数の第2の時間ステップの各々において1つまたは複数のそれぞれの音響トークンのセットを指定し、第2の時間ステップの各々における前記1つまたは複数のそれぞれの音響トークンが、対応する第2の時間ステップにおける前記オーディオ信号の音響特性を表す、前記生成することと、
デコーダニューラルネットワークを使用して少なくとも前記音響表現を処理して前記オーディオ信号の前記予測を生成することと
を含む、方法。
続きを表示(約 2,100 文字)
【請求項2】
前記デコーダニューラルネットワークが、エンコーダニューラルネットワークによって生成された出力を使用して生成された音響表現から、前記デコーダニューラルネットワークによって生成された予測オーディオ信号の再構築品質を測定する目的で前記エンコーダニューラルネットワークと共同で訓練されているニューラルオーディオコーデックのデコーダニューラルネットワークである、請求項1に記載の方法。
【請求項3】
前記音響表現が、前記オーディオ信号を処理することによってエンコーダニューラルネットワークの出力から生成されるであろうグラウンドトゥルース音響表現の予測である、請求項1または2に記載の方法。
【請求項4】
前記エンコーダニューラルネットワークが、前記複数の第2の時間ステップの各々においてそれぞれの埋め込みを出力し、前記グラウンドトゥルース音響表現が、前記それぞれの埋め込みの各々に量子化を適用することによって生成される、請求項3に記載の方法。
【請求項5】
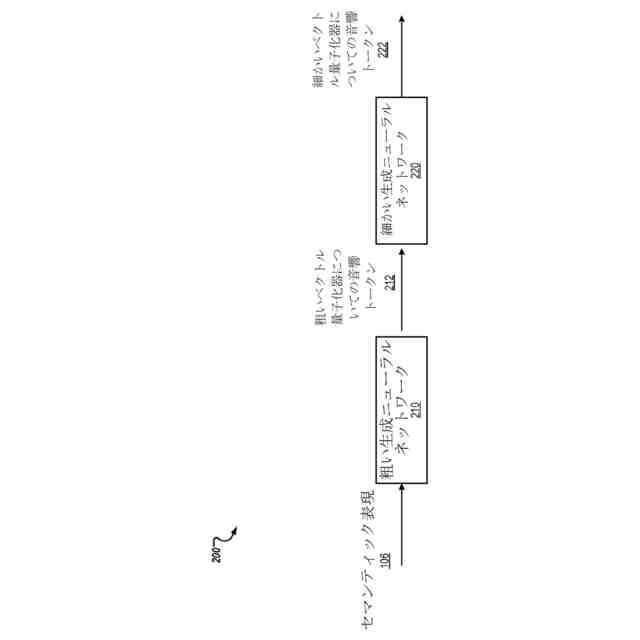
前記量子化が、各々がベクトル量子化器についての音響トークンの対応する語彙からそれぞれの音響トークンを生成する複数の前記ベクトル量子化器の階層を使用して各埋め込みをエンコードする残差ベクトル量子化であり、前記階層が、前記階層内の1つまたは複数の最初の位置にある1つまたは複数の粗いベクトル量子化器と、前記階層内の1つまたは複数の最後の位置にある1つまたは複数の細かい量子化器とを備え、
第2の時間ステップの各々における前記1つまたは複数のそれぞれの音響トークンのセットが、ベクトル量子化器ごとに、前記ベクトル量子化器の前記語彙から選択され、前記第2の時間ステップにおいて前記エンコーダニューラルネットワークによって生成されたグラウンドトゥルース埋め込みから前記ベクトル量子化器によって生成されるであろうグラウンドトゥルース音響トークンの予測であるそれぞれの音響トークンを含む、
請求項4に記載の方法。
【請求項6】
前記複数の第2の時間ステップの各々における前記1つまたは複数のそれぞれの音響トークンのセットが、前記第2の時間ステップにおける前記オーディオ信号の音響特性を表す埋め込みに適用された残差ベクトル量子化の出力の予測を集合的に表す複数の音響トークンを含み、
前記残差ベクトル量子化が、各々がベクトル量子化器についての音響トークンの対応する語彙からそれぞれの音響トークンを生成する複数の前記ベクトル量子化器の階層を使用して前記埋め込みをエンコードし、前記階層が、前記階層内の1つまたは複数の最初の位置にある1つまたは複数の粗いベクトル量子化器と、前記階層内の1つまたは複数の最後の位置にある1つまたは複数の細かいベクトル量子化器とを備え、
第2の時間ステップの各々における前記音響トークンのセットが、ベクトル量子化器ごとに、前記ベクトル量子化器の前記語彙から選択されたそれぞれの音響トークンを含む、
請求項1から5のいずれか一項に記載の方法。
【請求項7】
1つまたは複数の生成ニューラルネットワークを使用して、かつ少なくとも前記セマンティック表現を条件として、前記オーディオ信号の音響表現を生成することが、
第1の生成ニューラルネットワークを使用して、前記階層内の前記1つまたは複数の粗いベクトル量子化器の各々について、少なくとも前記セマンティック表現を条件として、前記ベクトル量子化器の前記第2の時間ステップの前記それぞれの音響トークンを生成することを含む、
請求項5または請求項6に記載の方法。
【請求項8】
前記第1の生成ニューラルネットワークが、第1の生成順序に従って前記音響トークンを自己回帰的に生成するように構成された自己回帰ニューラルネットワークであり、各特定の粗いベクトル量子化器についての各特定の第2の時間ステップにおける各特定の音響トークンが、少なくとも前記セマンティック表現、及び前記第1の生成順序で前記特定の音響トークンに先行する任意の音響トークンを条件とする、請求項7に記載の方法。
【請求項9】
各特定の粗いベクトル量子化器についての各特定の第2の時間ステップにおける各特定の音響トークンの前に、(i)前記特定の第2の時間ステップに先行する任意の第2の時間ステップにおける前記粗いベクトル量子化器のうちのいずれかについての任意の音響トークン、及び(ii)前記階層内の前記特定のベクトル量子化器に先行する任意の粗いベクトル量子化器の前記特定の第2の時間ステップにおける任意の音響トークンが前記第1の生成順序で先行する、請求項8に記載の方法。
【請求項10】
前記第1の生成ニューラルネットワークが、デコーダ専用のトランスフォーマアーキテクチャ、またはエンコーダ-デコーダのトランスフォーマアーキテクチャを有する、請求項6から9のいずれか一項に記載の方法。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
関連出願の相互参照
本出願は、2022年9月7日に出願された米国仮出願第63/404,528号及び2023年1月26日に出願された米国仮出願第63/441,412号に対する優先権を主張する。先行出願の開示は、本出願の開示の一部と見なされ、参照により本出願の開示に組み込まれる。
続きを表示(約 1,700 文字)
【背景技術】
【0002】
本明細書は、ニューラルネットワークを使用してオーディオを生成にすることに関する。
【0003】
ニューラルネットワークは、受信した入力に対する出力を予測するために1つまたは複数の非線形ユニットの層を使用する機械学習モデルである。一部のニューラルネットワークは、出力層に加えて1つまたは複数の隠し層を含む。各隠し層の出力は、ネットワーク内の次の層、つまり、次の隠し層または出力層への入力として使用される。ネットワークの各層は、それぞれのパラメータセットの現在の値の入力に従って、受信した入力から出力を生成する。
【発明の概要】
【0004】
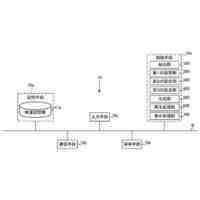
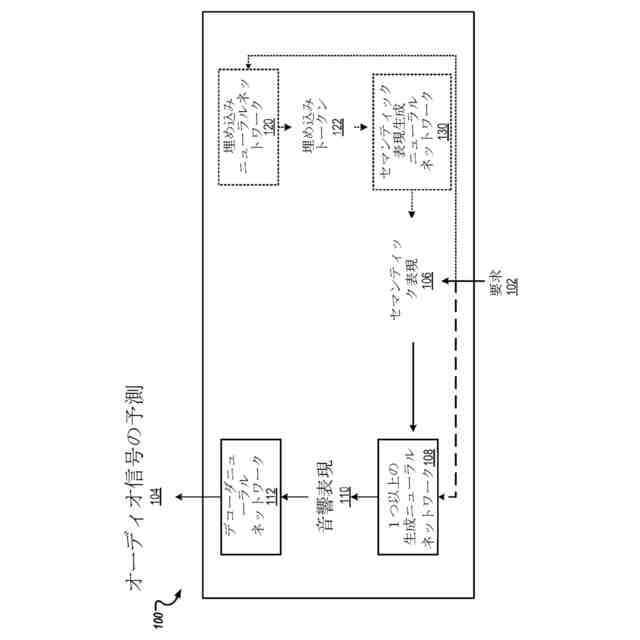
本明細書は、1つまたは複数の生成ニューラルネットワークを使用してオーディオ信号を生成する、1つまたは複数の場所にある1つまたは複数のコンピュータ上でコンピュータプログラムとして実装されるシステムを説明する。
【0005】
一般に、出力オーディオ信号は、指定された時間ウィンドウにまたがる出力時間ステップのシーケンスのそれぞれにおける音波のサンプルを含む出力オーディオ例である。例えば、出力時間ステップは、指定された時間ウィンドウ内で一定の間隔で配置できる。
【0006】
所与の出力時間ステップにおけるオーディオサンプルは、音波の振幅値であるか、または圧縮、圧伸、もしくはその両方が行われた振幅値であり得る。例えば、オーディオサンプルは、未処理の振幅値、または振幅値のmu-law圧伸表現であり得る。
【0007】
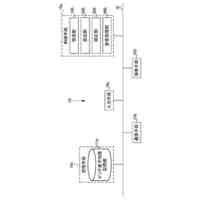
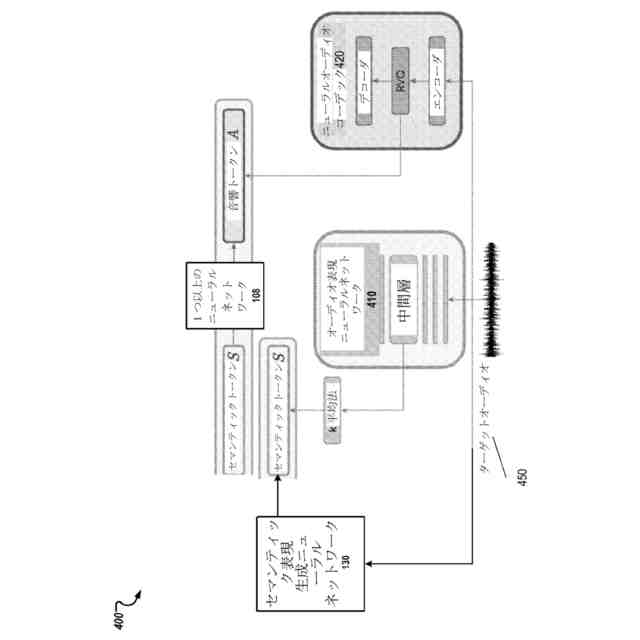
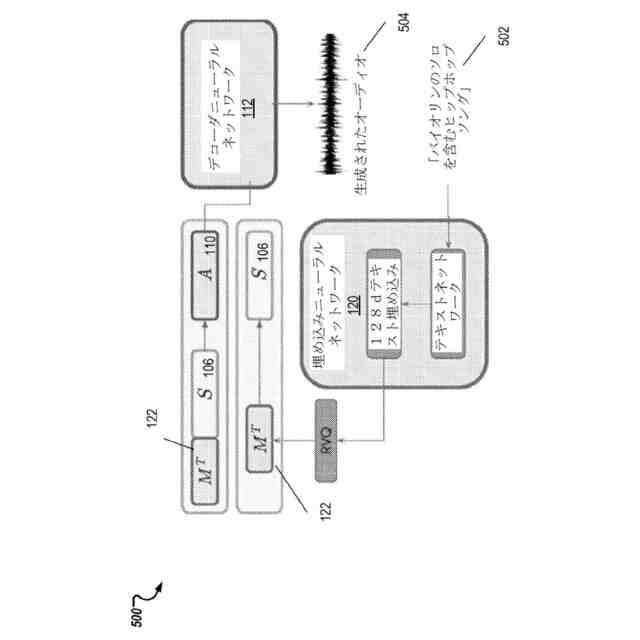
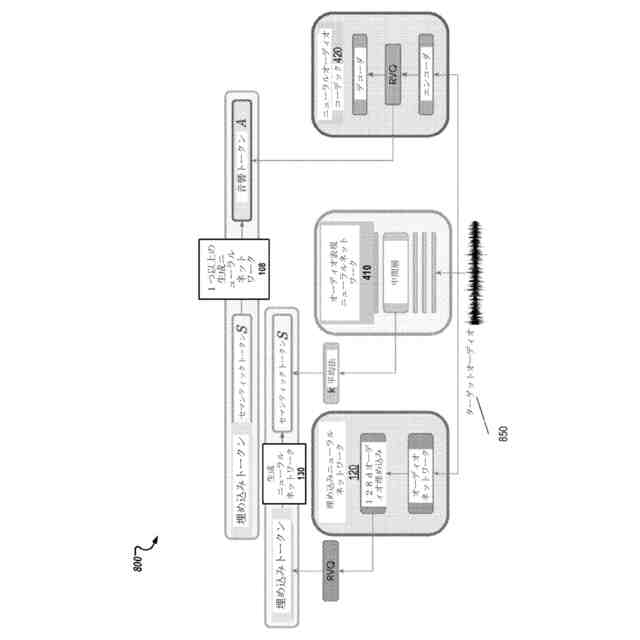
第1の態様によれば、オーディオ信号の予測を生成するための方法が提供され、方法は、時間ウィンドウにまたがる複数の出力時間ステップの各々においてそれぞれのオーディオサンプルを有するオーディオ信号を生成するための要求を受信することと、時間ウィンドウにまたがる複数の第1の時間ステップの各々においてそれぞれのセマンティックトークンを指定するオーディオ信号のセマンティック表現を取得することであって、各セマンティックトークンが、セマンティックトークンの語彙(a vocabulary of semantic tokens)から選択され、対応する第1の時間ステップにおけるオーディオ信号のセマンティックコンテンツを表す、取得することと、1つまたは複数の生成ニューラルネットワークを使用し、少なくともセマンティック表現を条件として、オーディオ信号の音響表現を生成することであって、音響表現が、時間ウィンドウにまたがる複数の第2の時間ステップの各々において1つまたは複数のそれぞれの音響トークンのセットを指定し、それぞれの第2の時間ステップにおける1つまたは複数のそれぞれの音響トークンが、対応する第2の時間ステップにおけるオーディオ信号の音響特性を表す、生成することと、デコーダニューラルネットワークを使用して少なくとも音響表現を処理してオーディオ信号の予測を生成することとを含む。
【0008】
いくつかの実施態様では、デコーダニューラルネットワークは、エンコーダニューラルネットワークによって生成された出力を使用して生成された音響表現から、デコーダニューラルネットワークによって生成された予測オーディオ信号の再構築品質を測定する目的でエンコーダニューラルネットワークと共同で訓練されているニューラルオーディオコーデックのデコーダニューラルネットワークである。
【0009】
いくつかの実施態様では、音響表現は、オーディオ信号を処理することによってエンコーダニューラルネットワークの出力から生成されるであろうグラウンドトゥルース音響表現の予測である。
【0010】
いくつかの実施態様では、エンコーダニューラルネットワークは、複数の第2の時間ステップの各々においてそれぞれの埋め込みを出力し、グラウンドトゥルース音響表現は、それぞれの埋め込みの各々に量子化を適用することによって生成される。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
グーグル エルエルシー
データ依存の不規則な演算のためのプログラム可能なアクセラレータ
13日前
個人
破裂爆発波動体感バルーン
1か月前
株式会社白鳩
音漏れ抑制マスク
27日前
株式会社白鳩
音漏れ抑制マスク
27日前
株式会社豊田中央研究所
吸音構造体
1日前
株式会社イシダ
商品処理装置
1か月前
ヤマハ株式会社
リード
1か月前
川崎重工業株式会社
表面材
29日前
日本音響エンジニアリング株式会社
騒音低減装置
1か月前
株式会社フジタ
環境音快音化システム
1か月前
株式会社イノアックコーポレーション
吸音材
20日前
個人
歌唱技術表示装置および歌唱技術表示方法
1か月前
NOK株式会社
吸音構造体
1か月前
株式会社第一興商
カラオケ装置
1か月前
株式会社第一興商
カラオケ装置
21日前
KDDI株式会社
認証装置、認証方法及び認証プログラム
20日前
株式会社第一興商
カラオケ装置
29日前
株式会社第一興商
カラオケ装置
1日前
トヨタ自動車株式会社
防音カバー
1か月前
中原大學
能動騒音除去機能を持つレンジフード
1日前
株式会社エクシング
端末装置、及び、端末装置用プログラム
1か月前
個人
楽曲検索装置、楽曲検索方法、及び楽曲検索プログラム
1か月前
シャープ株式会社
電子機器および電子機器の制御方法
1か月前
マツダ株式会社
内燃機関の吸気音増幅装置
1か月前
株式会社JVCケンウッド
クリッピング装置及びクリッピング方法
1日前
株式会社麗光
防音積層体とその製造に用いる遮音膜、および遮音膜シート
1か月前
トヨタ自動車株式会社
電気自動車
21日前
富士通株式会社
情報処理プログラム、情報処理方法及び情報処理装置
1か月前
宮澤フル-ト製造株式会社
タンポ及び木管楽器
1か月前
ローランド株式会社
打楽器および打面の形成方法
28日前
カシオ計算機株式会社
演奏装置、方法およびプログラム
1か月前
カシオ計算機株式会社
制御装置、方法およびプログラム
1日前
カシオ計算機株式会社
制御装置、方法およびプログラム
1日前
株式会社SOKEN
吸音構造体
1か月前
ローランド株式会社
打楽器および取付部材の取付方法
28日前
本田技研工業株式会社
音声認識装置、音声認識方法、及びプログラム
1日前
続きを見る
他の特許を見る



 特許ウォッチ
特許ウォッチ