TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025139845
公報種別
公開特許公報(A)
公開日
2025-09-29
出願番号
2024038898
出願日
2024-03-13
発明の名称
音声認識装置、音声認識方法、及びプログラム
出願人
本田技研工業株式会社
代理人
個人
,
個人
,
個人
主分類
G10L
15/16 20060101AFI20250919BHJP(楽器;音響)
要約
【課題】音声認識の精度を更に向上させることができる音声認識装置、音声認識方法、及びプログラムを提供する。
【解決手段】音声認識装置は、音声ストリームのフレームを取得する取得部と、ストリーミングエンコーダを用いて、前記フレームから第1特徴を生成するストリーミング特徴生成部と、ストリーミングデコーダを用いて、前記第1特徴から第1文字を生成するストリーミング文字生成部と、ノンストリーミングエンコーダを用いて、複数の前記フレームのそれぞれの前記第1特徴を合わせた第1特徴列から、第2特徴列を生成するノンストリーミング特徴生成部と、複数のノンストリーミングデコーダを用いて、前記第2特徴列から第2文字列を生成するストリーミング文字生成部と、前記第1特徴列及び前記第2特徴列に基づいて、前記ストリーミングエンコーダと前記ノンストリーミングエンコーダとの間で知識蒸留を行う学習部と、を備える。
【選択図】図3
特許請求の範囲
【請求項1】
音声ストリームの単位時間あたりのフレームを取得する取得部と、
ストリーミングエンコーダを用いて、前記フレームから第1特徴を生成するストリーミング特徴生成部と、
ストリーミングデコーダを用いて、前記第1特徴から第1文字を生成するストリーミング文字生成部と、
ノンストリーミングエンコーダを用いて、複数の前記フレームのそれぞれの前記第1特徴を合わせた第1特徴列から、第2特徴列を生成するノンストリーミング特徴生成部と、
複数のノンストリーミングデコーダを用いて、前記第2特徴列から第2文字列を生成するストリーミング文字生成部と、
前記第1特徴列及び前記第2特徴列に基づいて、前記ストリーミングエンコーダと前記ノンストリーミングエンコーダとの間で知識蒸留を行う学習部と、
を備える音声認識装置。
続きを表示(約 1,200 文字)
【請求項2】
前記学習部は、前記第1特徴列が前記第2特徴列に類似するように、前記ストリーミングエンコーダと前記ノンストリーミングエンコーダとの間で前記知識蒸留を行う、
請求項1に記載の音声認識装置。
【請求項3】
前記学習部は、更に、複数の前記第1特徴のそれぞれから生成された前記第1文字を時系列に並べた第1文字列の尤度と、前記第2特徴列から生成された前記第2文字列の尤度とに基づいて、前記ストリーミングデコーダと前記複数のノンストリーミングデコーダとの間で前記知識蒸留を行う、
請求項1又は2に記載の音声認識装置。
【請求項4】
前記ストリーミングデコーダには、前記第1文字を予測する予測器が少なくとも含まれており、
前記複数のノンストリーミングデコーダには、アテンション機構を含むデコーダであるアテンションデコーダが少なくとも含まれており、
前記学習部は、前記予測器によって予測される前記第1文字を時系列に並べた前記第1文字列の尤度が前記アテンションデコーダによって出力される前記第2文字列の尤度に類似するように、前記予測器と前記アテンションデコーダとの間で前記知識蒸留を行う、
請求項3に記載の音声認識装置。
【請求項5】
音声ストリームの単位時間あたりのフレームを取得すること、
ストリーミングエンコーダを用いて、前記フレームから第1特徴を生成すること、
ストリーミングデコーダを用いて、前記第1特徴から第1文字を生成すること、
ノンストリーミングエンコーダを用いて、複数の前記フレームのそれぞれの前記第1特徴を合わせた第1特徴列から、第2特徴列を生成すること、
複数のノンストリーミングデコーダを用いて、前記第2特徴列から第2文字列を生成すること、
前記第1特徴列及び前記第2特徴列に基づいて、前記ストリーミングエンコーダと前記ノンストリーミングエンコーダとの間で知識蒸留を行うこと、
を含む音声認識方法。
【請求項6】
コンピュータに実行させるためのプログラムであって、
音声ストリームの単位時間あたりのフレームを取得すること、
ストリーミングエンコーダを用いて、前記フレームから第1特徴を生成すること、
ストリーミングデコーダを用いて、前記第1特徴から第1文字を生成すること、
ノンストリーミングエンコーダを用いて、複数の前記フレームのそれぞれの前記第1特徴を合わせた第1特徴列から、第2特徴列を生成すること、
複数のノンストリーミングデコーダを用いて、前記第2特徴列から第2文字列を生成すること、
前記第1特徴列及び前記第2特徴列に基づいて、前記ストリーミングエンコーダと前記ノンストリーミングエンコーダとの間で知識蒸留を行うこと、
を含むプログラム。
発明の詳細な説明
【技術分野】
【0001】
本発明は、音声認識装置、音声認識方法、及びプログラムに関する。
続きを表示(約 2,100 文字)
【背景技術】
【0002】
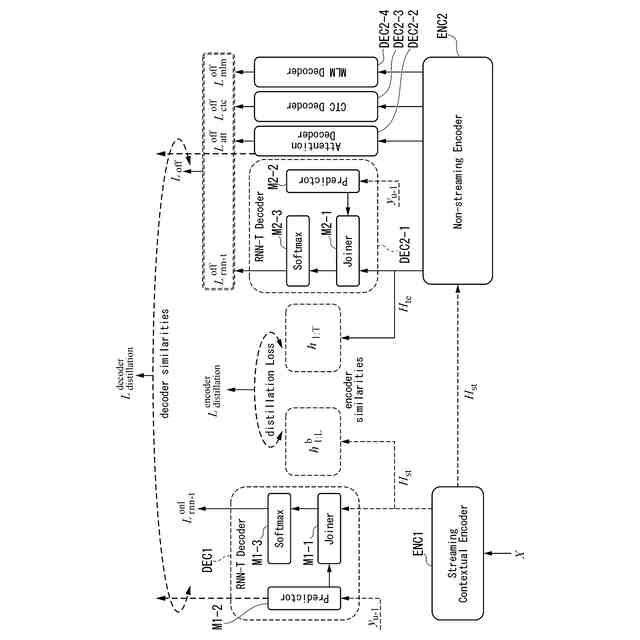
エンドツーエンド(E2E)自動音声認識(ASR)は、ストリーミングとノンストリーミングの2つのモードで動作する(例えば非特許文献1参照)。ストリーミングASRとノンストリーミングASRには、それぞれに長所と短所があることが知られている。ストリーミングASRは、音声フレームを受信しながらリアルタイムで処理することができるが、音声認識の精度がノンストリーミングASRに比べて低い傾向にある。一方で、ノンストリーミングASRは、音声フレームをリアルタイムで処理することができず、音声発話の全体を待つ必要があるものの、音声認識の精度がストリーミングASRに比べて高い傾向にある。
【先行技術文献】
【非特許文献】
【0003】
Arun Narayanan, Tara N. Sainath, Ruoming Pang, Jiahui Yu, Chung-Cheng Chiu, Rohit Prabhavalkar, Ehsan Variani, Trevor Strohman, “Cascaded encoders for unifying streaming and non-streaming ASR,” in Proc. ICASSP, 2021, DOI: org/10.48550/arXiv.2010.14606.
【発明の概要】
【発明が解決しようとする課題】
【0004】
しかしながら従来の技術では、ストリーミングASRとノンストリーミングASRとを組み合わせて音声認識の精度を向上させることについて改善の余地があった。
【0005】
本発明は、このような事情を考慮してなされたものであり、音声認識の精度を更に向上させることができる音声認識装置、音声認識方法、及びプログラムを提供することを目的の一つとする。
【課題を解決するための手段】
【0006】
本発明に係る音声認識装置、音声認識方法、及びプログラムは以下の構成を採用した。
(1)本発明の第1の例は、音声ストリームの単位時間あたりのフレームを取得する取得部と、ストリーミングエンコーダを用いて、前記フレームから第1特徴を生成するストリーミング特徴生成部と、ストリーミングデコーダを用いて、前記第1特徴から第1文字を生成するストリーミング文字生成部と、ノンストリーミングエンコーダを用いて、複数の前記フレームのそれぞれの前記第1特徴を合わせた第1特徴列から、第2特徴列を生成するノンストリーミング特徴生成部と、複数のノンストリーミングデコーダを用いて、前記第2特徴列から第2文字列を生成するストリーミング文字生成部と、前記第1特徴列及び前記第2特徴列に基づいて、前記ストリーミングエンコーダと前記ノンストリーミングエンコーダとの間で知識蒸留を行う学習部と、を備える音声認識装置である。
【0007】
(2)本発明の第2の例は、第1の例において、前記学習部は、前記第1特徴列が前記第2特徴列に類似するように、前記ストリーミングエンコーダと前記ノンストリーミングエンコーダとの間で前記知識蒸留を行うものである。
【0008】
(3)本発明の第3の例は、第1又は第2の例において、前記学習部は、更に、複数の前記第1特徴のそれぞれから生成された前記第1文字を時系列に並べた第1文字列の尤度と、前記第2特徴列から生成された前記第2文字列の尤度とに基づいて、前記ストリーミングデコーダと前記複数のノンストリーミングデコーダとの間で前記知識蒸留を行うものである。
【0009】
(4)本発明の第4の例は、第3の例において、前記ストリーミングデコーダには、前記第1文字を予測する予測器が少なくとも含まれており、前記複数のノンストリーミングデコーダには、アテンション機構を含むデコーダであるアテンションデコーダが少なくとも含まれており、前記学習部は、前記予測器によって予測される前記第1文字を時系列に並べた前記第1文字列の尤度が前記アテンションデコーダによって出力される前記第2文字列の尤度に類似するように、前記予測器と前記アテンションデコーダとの間で前記知識蒸留を行うものである。
【0010】
(5)本発明の第5の例は、音声ストリームの単位時間あたりのフレームを取得すること、ストリーミングエンコーダを用いて、前記フレームから第1特徴を生成すること、ストリーミングデコーダを用いて、前記第1特徴から第1文字を生成すること、ノンストリーミングエンコーダを用いて、複数の前記フレームのそれぞれの前記第1特徴を合わせた第1特徴列から、第2特徴列を生成すること、複数のノンストリーミングデコーダを用いて、前記第2特徴列から第2文字列を生成すること、前記第1特徴列及び前記第2特徴列に基づいて、前記ストリーミングエンコーダと前記ノンストリーミングエンコーダとの間で知識蒸留を行うこと、を含む音声認識方法である。
(【0011】以降は省略されています)
この特許をJ-PlatPat(特許庁公式サイト)で参照する
関連特許
本田技研工業株式会社
車両
12日前
本田技研工業株式会社
装置
11日前
本田技研工業株式会社
モータ
8日前
本田技研工業株式会社
車両構造
8日前
本田技研工業株式会社
送電装置
6日前
本田技研工業株式会社
受電装置
6日前
本田技研工業株式会社
車両構造
8日前
本田技研工業株式会社
ステータ
4日前
本田技研工業株式会社
保持装置
5日前
本田技研工業株式会社
内燃機関
11日前
本田技研工業株式会社
ロボット
1か月前
本田技研工業株式会社
内燃機関
11日前
本田技研工業株式会社
会話装置
4日前
本田技研工業株式会社
断続装置
6日前
本田技研工業株式会社
通知装置
11日前
本田技研工業株式会社
固体電池
6日前
本田技研工業株式会社
切断装置
4日前
本田技研工業株式会社
保管装置
6日前
本田技研工業株式会社
保管装置
6日前
本田技研工業株式会社
電解装置
19日前
本田技研工業株式会社
バッテリ
5日前
本田技研工業株式会社
バッテリ
5日前
本田技研工業株式会社
鞍乗型車両
18日前
本田技研工業株式会社
リンク機構
4日前
本田技研工業株式会社
リアクトル
11日前
本田技研工業株式会社
放電処理方法
6日前
本田技研工業株式会社
潤滑システム
6日前
本田技研工業株式会社
電源システム
6日前
本田技研工業株式会社
分離システム
8日前
本田技研工業株式会社
運転制御装置
8日前
本田技研工業株式会社
鞍乗り型車両
28日前
本田技研工業株式会社
車両制御装置
12日前
本田技研工業株式会社
固体二次電池
18日前
本田技研工業株式会社
車両制御装置
18日前
本田技研工業株式会社
潤滑システム
18日前
本田技研工業株式会社
車両制御装置
20日前
続きを見る
他の特許を見る





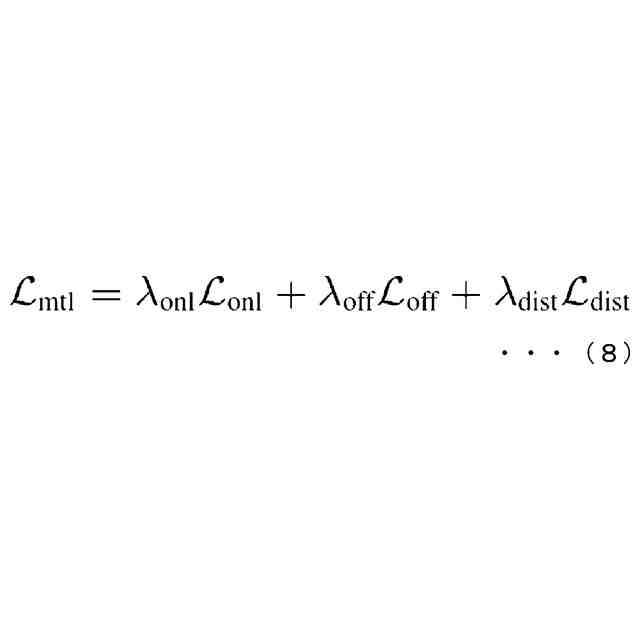

 特許ウォッチ
特許ウォッチ