TOP
|
特許
|
意匠
|
商標
特許ウォッチ
Twitter
他の特許を見る
10個以上の画像は省略されています。
公開番号
2025111462
公報種別
公開特許公報(A)
公開日
2025-07-30
出願番号
2025054044,2023558844
出願日
2025-03-27,2021-12-15
発明の名称
自己アライメントを用いたストリーミングASRモデル遅延の短縮
出願人
グーグル エルエルシー
,
Google LLC
代理人
個人
,
個人
,
個人
主分類
G10L
15/06 20130101AFI20250723BHJP(楽器;音響)
要約
【課題】自己アライメントを用いてストリーミング自動音声認識(ASR)モデル遅延を短縮する音声認識モデル及びコンピュータ実装方法を提供する。
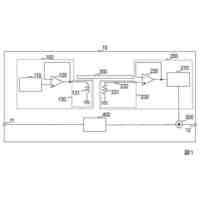
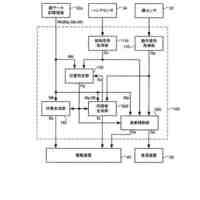
【解決手段】ストリーミング音声認識モデル200は、音響フレーム110のシーケンスを受信し、音響フレームのシーケンスにおける対応する音響フレームについての高次特徴表現202を生成するオーディオエンコーダと、最終ソフトマックス層240よって出力された非ブランク記号242のシーケンスを受信し、密な表現222を生成するラベルエンコーダ220と、オーディオエンコーダによって生成された高次特徴表現およびラベルエンコーダによって生成された密な表現を入力として受信し、あり得る音声認識仮説にわたる確率分布232を生成するジョイントネットワーク230と、を含む。
【選択図】図2
特許請求の範囲
【請求項1】
ストリーミング音声認識モデル(200)であって、
オーディオエンコーダ(210)であって、
音響フレーム(110)のシーケンスを入力として受信し、
複数の時間ステップの各々において、前記音響フレーム(110)のシーケンスにおける対応する音響フレーム(110)についての高次特徴表現(202)を生成する
ように構成された、オーディオエンコーダ(210)と、
ラベルエンコーダ(220)であって、
最終ソフトマックス層(240)によって出力された非ブランク記号(242)のシーケンスを入力として受信し、
前記複数の時間ステップの各々において、密な表現(222)を生成する
ように構成された、ラベルエンコーダ(220)と、
ジョイントネットワーク(230)であって、
前記複数の時間ステップの各々において前記オーディオエンコーダ(210)によって生成された前記高次特徴表現(202)および前記複数の時間ステップの各々において前記ラベルエンコーダ(220)によって生成された前記密な表現(222)を入力として受信し、
前記複数の時間ステップの各々において、対応する時間ステップにおけるあり得る音声認識仮説にわたる確率分布(232)を生成する
ように構成された、ジョイントネットワーク(230)とを備え、
前記ストリーミング音声認識モデル(200)は、自己アライメントを使用して、各訓練バッチについて、各時間ステップにおける基準強制アライメントフレームの1フレーム左側のアライメント経路を促すことによって予測遅延を短縮するように訓練される、音声認識モデル(200)。
続きを表示(約 1,300 文字)
【請求項2】
前記ストリーミング音声認識モデル(200)は、トランスフォーマ-トランスデューサモデルを備える、請求項1に記載の音声認識モデル(200)。
【請求項3】
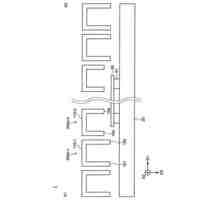
前記オーディオエンコーダ(210)は、トランスフォーマ層(400)のスタックを備え、各トランスフォーマ層(400)は、
正規化層(404)と、
相対位置符号化を伴うマスクされたマルチヘッドアテンション層(406)と、
残差接続(408)と、
スタッキング/アンスタッキング層(410)と、
フィードフォワード層(412)とを備える、請求項2に記載の音声認識モデル(200)。
【請求項4】
前記スタッキング/アンスタッキング層(410)は、対応するトランスフォーマ層(400)のフレームレートを変更して訓練および推論の間の前記トランスフォーマ-トランスデューサモデルによる処理時間を調整するように構成される、請求項3に記載の音声認識モデル(200)。
【請求項5】
前記ラベルエンコーダ(220)は、トランスフォーマ層(400)のスタックを備え、各トランスフォーマ層(400)は、
正規化層(404)と、
相対位置符号化を伴うマスクされたマルチヘッドアテンション層(406)と、
残差接続(408)と、
スタッキング/アンスタッキング層(410)と、
フィードフォワード層(412)とを備える、請求項2から4のいずれか一項に記載の音声認識モデル(200)。
【請求項6】
前記ラベルエンコーダ(220)は、bigram埋め込みルックアップデコーダモデルを備える、請求項1から5のいずれか一項に記載の音声認識モデル(200)。
【請求項7】
前記ストリーミング音声認識モデル(200)は、
リカレントニューラル-トランスデューサ(RNN-T)モデル、
トランスフォーマ-トランスデューサモデル、
畳み込みネットワーク-トランスデューサ(ConvNet-トランスデューサ)モデル、または
コンフォーマ-トランスデューサモデル、のうちの1つを含む、請求項1から6のいずれか一項に記載の音声認識モデル(200)。
【請求項8】
自己アライメントを使用して予測遅延を短縮するように前記ストリーミング音声認識モデル(200)を訓練することは、外部アライナモデルを使用して復号グラフ(300)のアライメントを制約することなく自己アライメントを使用することを含む、請求項1から7のいずれか一項に記載の音声認識モデル(200)。
【請求項9】
前記ストリーミング音声認識モデル(200)は、ユーザデバイス(10)またはサーバ(60)上で実行される、請求項1から8のいずれか一項に記載の音声認識モデル(200)。
【請求項10】
前記音響フレーム(110)のシーケンスにおける各音響フレーム(110)は、次元特徴ベクトルを備える、請求項1から9のいずれか一項に記載の音声認識モデル(200)。
(【請求項11】以降は省略されています)
発明の詳細な説明
【技術分野】
【0001】
本開示は、自己アライメントを用いてストリーミング自動音声認識(ASR)モデル遅延を短縮することに関する。
続きを表示(約 3,900 文字)
【背景技術】
【0002】
オーディオ入力を得てテキストに書き起こすプロセスである自動音声認識(ASR)は、モバイルデバイスおよび他のデバイスによって使用される非常に重要な技術である。一般に、ASRは、オーディオ入力(たとえば、発話)を得てオーディオ入力をテキストに書き起こすことによって人が話したことの正確なトランスクリプションを提供することを試みる。現代のASRモデルは、ディープニューラルネットワークの継続的な開発に基づいて精度(たとえば、低い単語誤り率(WER))とレイテンシ(たとえば、ユーザの発話とトランスクリプションとの間の遅延)の両方が改善され続けている。現在ASRシステムを使用する際、ASRシステムが、リアルタイムに相当するかまたは場合によってはリアルタイムよりも速いが、正確でもあるストリーミング方式によって発話を復号することが要求される。しかし、遅延制約なしにシーケンス尤度を最適化するストリーミングエンドツーエンドモデルでは、このようなモデルが、より遠い将来のコンテキストを使用することによってモデルの予測を向上させるように学習することに起因して、オーディオ入力と予測テキストとの間に大きい遅延が生じる。
【先行技術文献】
【特許文献】
【0003】
米国特許出願第17/210465号
【発明の概要】
【課題を解決するための手段】
【0004】
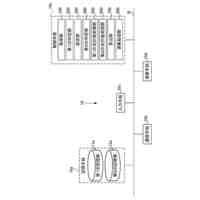
本開示の一態様は、音響フレームのシーケンスを入力として受信し、複数の時間ステップの各々において、音響フレームのシーケンス内の対応する音響フレームについての高次特徴表現を生成するように構成されたオーディオエンコーダを含む、ストリーミング音声認識モデルを提供する。ストリーミング音声認識モデルはまた、ラベルエンコーダであって、最終ソフトマックス層によって出力された非ブランク記号のシーケンスを入力として受信し、複数の時間ステップの各々において、密な表現を生成するように構成されたラベルエンコーダを含む。ストリーミング音声認識モデルはまた、ジョイントネットワークであって、複数の時間ステップの各々においてオーディオエンコーダによって生成された高次特徴表現および複数の時間ステップの各々においてラベルエンコーダによって生成された密な表現を入力として受信し、複数の時間ステップの各々において、対応する時間ステップにおけるあり得る音声認識仮説にわたる確率分布を生成するように構成されたジョイントネットワークを含む。ここで、ストリーミング音声認識モデルは、自己アライメントを使用して、各訓練バッチについて、各時間ステップにおける基準強制アライメントフレームの1フレーム左側のアライメント経路を促すことによって予測遅延を短縮するように訓練される。
【0005】
本開示の実装形態は、以下の任意の特徴のうちの1つまたは複数を含んでもよい。いくつかの実装形態では、ストリーミング音声認識モデルは、トランスフォーマ-トランスデューサモデルを含む。これらの実装形態では、オーディオエンコーダは、トランスフォーマ層のスタックを含んでもよく、各トランスフォーマ層は、正規化層と、相対位置符号化を伴うマスクされたマルチヘッドアテンション層と、残差接続、スタッキング/アンスタッキング層と、フィードフォワード層とを含む。ここで、スタッキング/アンスタッキング層は、対応するトランスフォーマ層のフレームレートを変更して訓練および推論の間にトランスフォーマ-トランスデューサモデルによる処理時間を調整するように構成されてもよい。いくつかの例では、ラベルエンコーダは、トランスフォーマ層のスタックを含み、各トランスフォーマ層は、正規化層と、相対位置符号化を伴うマスクされたマルチヘッドアテンション層と、残差接続、スタッキング/アンスタッキング層と、フィードフォワード層とを含む。
【0006】
場合によっては、ラベルエンコーダは、bigram埋め込みルックアップデコーダモデルを含んでもよい。いくつかの例では、ストリーミング音声認識モデルは、リカレントニューラル-トランスデューサ(RNN-T)モデル、トランスフォーマ-トランスデューサモデル、畳み込みネットワーク-トランスデューサ(ConvNet-トランスデューサ)モデル、またはコンフォーマ-トランスデューサモデルのうちの1つを含む。自己アライメントを使用して予測遅延を短縮するようにストリーミング式音声認識モデルを訓練することは、外部アライナモデルを使用して復号グラフのアライメントを制約することなく自己アライメントを使用することを含んでもよい。いくつかの実装形態では、ストリーミング音声認識モデルは、ユーザデバイスまたはサーバ上で実行される。いくつかの例では、音響フレームのシーケンスにおける各音響フレームは、次元特徴ベクトルを含む。
【0007】
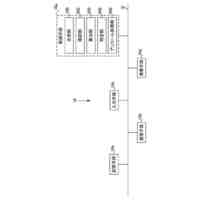
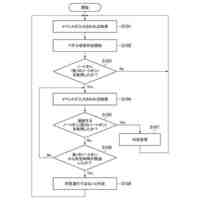
本開示の別の態様は、データ処理ハードウェア上で実行されたときに、自己アライメントを使用して予測遅延を短縮するようにストリーミング音声認識モデルを訓練するための動作をデータ処理ハードウェアに実行させるコンピュータ実装方法を提供する。動作は、ストリーミング音声認識モデルへの入力として、発話に対応する音響フレームのシーケンスを受信することを含む。ストリーミング音声認識モデルは、音響フレームのシーケンスとラベルトークンの出力シーケンスとの間のアライメント確率を学習するように構成される。動作はまた、ストリーミング音声認識モデルからの出力として、発話についての音声認識結果を生成することを含む。音声認識結果は、復号グラフを使用してラベルトークンの出力シーケンスを生成することを含む。動作はまた、音声認識結果および発話のグランドトゥルーストランスクリプションに基づいて、音声認識モデル損失を生成することを含む。動作はまた、基準強制アライメントフレームを含む基準強制アライメント経路を復号グラフから取得することと、復号グラフから、基準強制アライメント経路における各基準強制アライメントフレームから左側の1フレームを識別することとを含む。動作はまた、基準強制アライメント経路における各強制アライメントフレームから左側の識別されたフレームに基づいてラベル遷移確率を合計することと、ラベル遷移確率の合計および音声認識モデル損失に基づいてストリーミング音声認識モデルを更新することを含む。
【0008】
本開示の実装形態は、以下の任意の特徴のうちの1つまたは複数を含んでもよい。いくつかの実装形態では、動作は、ストリーミング音声認識モデルのオーディオエンコーダによって、複数の時間ステップの各々において音響フレームのシーケンスにおける対応する音響フレームについての高次特徴表現を生成することと、ストリーミング音声認識モデルのラベルエンコーダへの入力として、最終ソフトマックス層によって出力された非ブランク記号のシーケンスを受信することと、ラベルエンコーダによって、複数の時間ステップの各々において密な表現を生成することと、ストリーミング音声認識モデルのジョイントネットワークへの入力として、複数の時間ステップの各々においてオーディオエンコーダによって生成された高次特徴表現および複数の時間ステップの各々においてラベルエンコーダによって生成された密な表現を受信することと、ジョイントネットワークによって、複数の時間ステップの各々において、対応する時間ステップにおけるあり得る音声認識仮説にわたる確率分布を生成することとをさらに含む。いくつかの例では、ラベルエンコーダは、トランスフォーマ層のスタックを含み、各トランスフォーマ層は、正規化層と、相対位置符号化を伴うマスクされたマルチヘッドアテンション層と、残差接続、スタッキング/アンスタッキング層と、フィードフォワード層とを含む。ラベルエンコーダは、bigram埋め込みルックアップデコーダモデルを含んでもよい。
【0009】
いくつかの実装形態では、ストリーミング音声認識モデルは、トランスフォーマ-トランスデューサモデルを含む。オーディオエンコーダは、トランスフォーマ層のスタックを含んでもよく、各トランスフォーマ層は、正規化層と、相対位置符号化を伴うマスクされたマルチヘッドアテンション層と、残差接続、スタッキング/アンスタッキング層と、フィードフォワード層とを含む。ここで、スタッキング/アンスタッキング層は、対応するトランスフォーマ層のフレームレートを変更して訓練および推論の間のトランスフォーマ-トランスデューサモデルによる処理時間を調整するように構成されてもよい。
【0010】
いくつかの実装形態では、ストリーミング音声認識モデルは、リカレントニューラル-トランスデューサ(RNN-T)モデル、トランスフォーマ-トランスデューサモデル、畳み込みネットワーク-トランスデューサ(ConvNet-トランスデューサ)モデル、またはコンフォーマ-トランスデューサモデルのうちの1つを含む。ストリーミング音声認識モデルは、ユーザデバイスまたはサーバ上で実行されてもよい。いくつかの例では、動作は、外部アライナモデルを使用して復号グラフのアライメントを制約することなく、自己アライメントを使用して予測遅延を短縮するようにストリーミング式音声認識モデルを訓練することをさらに含む。
(【0011】以降は省略されています)
この特許をJ-PlatPatで参照する
関連特許
三井化学株式会社
遮音構造体
1か月前
三井化学株式会社
吸音構造体
1か月前
富士フイルム株式会社
消音器
6日前
三井化学株式会社
遮音構造体
1か月前
個人
弦楽器用押弦補助具及び弦楽器
1か月前
三井化学株式会社
遮音構造体
1か月前
林テレンプ株式会社
防音カバー
1か月前
積水化学工業株式会社
吸音構造体
2日前
ヤマハ株式会社
弦楽器用の支持装置
6日前
富士フイルム株式会社
消音器付き風路
6日前
株式会社総合車両製作所
吸音パネル
29日前
株式会社JVCケンウッド
車載装置
1か月前
個人
電気自動車等の「接近音」における最適な「音の種類」
1か月前
株式会社レゾナック
吸音材及び車両部材
22日前
株式会社HOWA
遮音構造
1か月前
カシオ計算機株式会社
楽器
1か月前
個人
電子管楽器
1か月前
株式会社第一興商
カラオケ装置
15日前
株式会社第一興商
カラオケ装置
29日前
株式会社JVCケンウッド
情報処理装置及び情報処理方法
1か月前
株式会社第一興商
カラオケ装置
1か月前
株式会社コルグ
電子楽器用アナログエフェクタ
28日前
有限会社舞システム企画
介護情報生成システム
6日前
ヤマハ株式会社
鍵盤装置
7日前
ヤマハ株式会社
連打判定装置および方法、プログラム
16日前
シャープ株式会社
制御装置、電気機器、およびシステム
9日前
ヤマハ株式会社
発音制御装置
1か月前
トヨタ自動車株式会社
制御装置
10日前
トヨタ自動車株式会社
電気自動車
1か月前
AOBAENERGY株式会社
サービス提供機器
1か月前
トヨタ自動車株式会社
音響式遮音材の製造方法
1か月前
本田技研工業株式会社
音声認識方法および音声認識装置
8日前
井関農機株式会社
作業車の操縦者用騒音低減装置
29日前
日本電波工業株式会社
音声再生装置及び音声再生方法
29日前
コニカミノルタ株式会社
音声変換装置、音声変換方法および音声変換プログラム
14日前
ローランド株式会社
鍵盤装置および押鍵情報の検出方法
1か月前
続きを見る
他の特許を見る











 特許ウォッチ
特許ウォッチ